结构化SVM方法用于跟踪,带来了速度和效果的提升。之前我有一篇讲Struck的博客,但是感觉这个算法没有讲透彻,决定捎带上SSVM再开一篇争取把问题讲清楚。结构化SVM和传统SVM方法相比,有着强大的判别能力,这篇博客将带大家一探结构化SVM在tracking上的应用。
同样是结构化SVM方法,Struck在2015年Pami中进一步加入尺度估计和GPU加速,使得Struck也具有相当的实用性。SSVM与Struck都是结构化预测框架,主要不同在于Struck采用SMO优化迭代求解,而SSVM采用DCD方法求闭式解,使得SSVM在速度上体现优势。
结构化预测
首先介绍下,什么是结构化预测,这篇博客有详细介绍。本文摘录一部分:
按照输入空间不同:特征学习(feature learning)
按照输出空间不同:二元分类(binary classification),多元分类(multiclass classification),回归问题(regression),结构化预测(structured prediction)
按照输出标记类型不同:监督式学习(supervised learning),非监督式学习(unsupervised learning),半监督式学习(semi-supervised learning),增强式学习(reinforcement learning)。这也是机器学习中最常见的分类
按照学习方法不同:批次学习(Batch Learning),线上学习(Online Learning),主动学习(Active Learning)。
按照输出空间不同机器学习可以分为:二元分类,多元分类,回归问题,和结构化预测。
二元分类
Binary classification, 目标变量取值只有两种可能性,简单来说就是做判断题,二元分类是机器学习中最基本的核心问题,许多其他算法都源自二元分类问题。很多tracking-by-detection就是直接将跟踪作为一个二元分类问题来处理。
多元分类
Multiclass classification, 相当于做选择题。
回归分析
Regression analysis,的目标变量是Numeric类型的,取值无限多个点。典型的回归分析问题包括曲线预测等。
结构化预测
Structured Learning,的目标变量和以上三者都不同,是一种结构。典型的结构化学习是对一个语言中的分析树(parse tree)。
结构化预测通过修改SVM的约束条件以及目标和核函数,将SVM从二分类问题拓展到可以预测结构化问题。结构化预测的参数学习方法有一下几种:
- structured perceptron(Collins, 2002)
- stochastic subgradient(Ratliff, 2007)
- extra-gradient(Taskar, 2006)
- cutting-plane algorithms(Joachims, 2009)
- Dual decomposition(Meshi, 2010)
结构化预测虽然提出较早,但是结构化预测用于跟踪才是近几年的事情,接下来的内容主要介绍结构化SVM用于图像跟踪。
Struck
Struck拥有很快的速度和很好的效果,如果不是KCF横空出世,Struck可能会多流行几年,KCF174fps的速度和效果已经吊打全场了,不过Struck的优秀也是遮挡不住的。
核心思想
使用结构化SVM来处理跟踪问题
结构化SVM
结构化SVM训练的目标是学习得到预测函数f,下式中g就是评分函数,评分函数输出的是连续值而非传统的[+1,-1],![]() ,y是搜索空间内的一个矩形,t是当前帧,时间空间,函数f作用是将时间空间映射到坐标空间,也就是预测位置过程的函数
,y是搜索空间内的一个矩形,t是当前帧,时间空间,函数f作用是将时间空间映射到坐标空间,也就是预测位置过程的函数
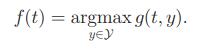
用一系列样本训练求解以下问题,就是基本SVM的Loss函数了,是属于最大间隔框架,最小化w,附带一个软间隔项:
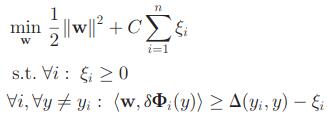
其中的△符号代表了我们定义的间隔,这个间隔的实际意义和重叠率是相关联的,重叠率为1时,该值为0,相当于训练时,中心处的样本,间隔设定为0
![]()
后面就是优化过程,推一边拉格朗日对偶条件,然后使用SMO优化
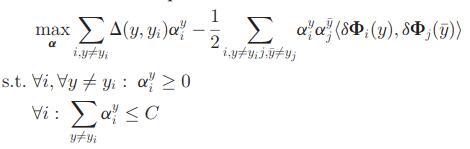
关于拉格朗日对偶原理的推导,建议参考《统计学习方法》(李航)
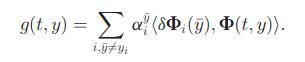
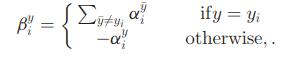
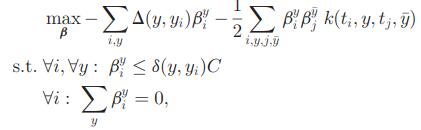
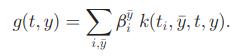
SMO优化,一次需要输入一对向量模型,一正一负,并且尽量使差异足够大,然后迭代更新支持向量

上面伪代码中,有一个符号的定义如下
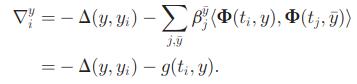
使用核函数时,g的核函数形式推导如下
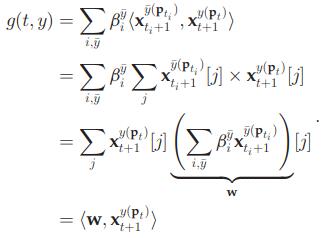
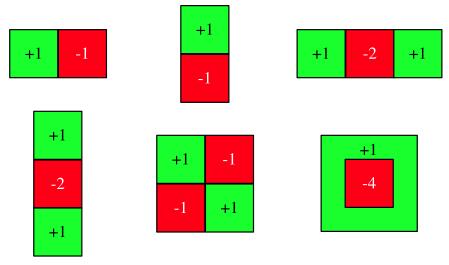
到这里,已经差不多结束结构化SVM的理论推导了,下面是介绍文章中跟踪的细节,第一个细节:算法使用的特征:Haar特征集
第二个细节:就是可以同时使用多个核函数进行组合,组合的方式也比较容易,就是在核映射之后取平均,如下式
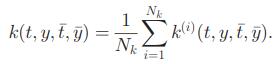 以下就是该算法中SVM维护数据的可视化表达了,这部分主要是为后面GPU实现做铺垫,数据规整才适合GPU加速嘛
以下就是该算法中SVM维护数据的可视化表达了,这部分主要是为后面GPU实现做铺垫,数据规整才适合GPU加速嘛

细节三:GPU加速,这是2015年Paper里面新加的
实现细节
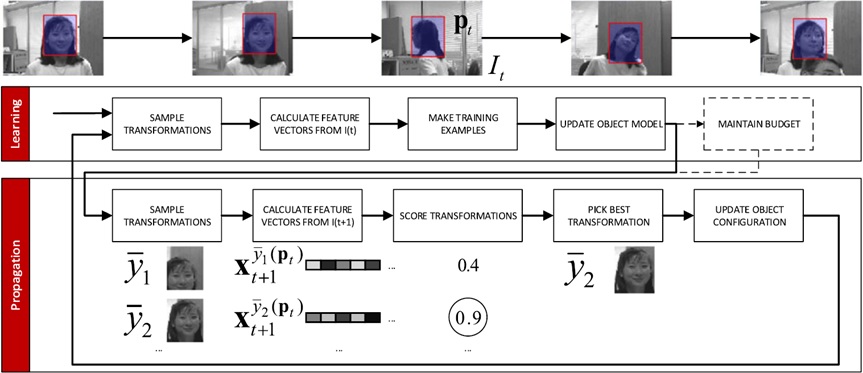
- 采样方法:对目标周围进行密集采样,超出采样框的将舍弃
- 预测位置:使用SVM对每个位置输出分数,预测当前帧位置
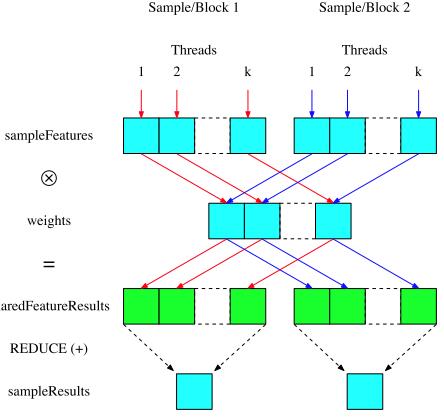
- 模型更新:根据预测,更新正负支持向量,更新过程采用的是SMO方法,每回使用一对向量,如下所示

上面的伪代码可以和Struck的C++源代码一起看,因为这份源码和上面伪代码的结构是一样的,代码和Paper结合的非常好,另外其中有些细节,如代价维护等等,都在Paper里面详细说明了,这里不过多赘述
参考文献
[1]. Hare, S., A. Saffari and P.H. Torr. Struck: Structured output tracking with kernels. in 2011 International Conference on Computer Vision. 2011: IEEE.
[2]. Hare, S., et al., Struck: Structured output tracking with kernels. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015. 38(10): p. 2096-2109.
SSVM
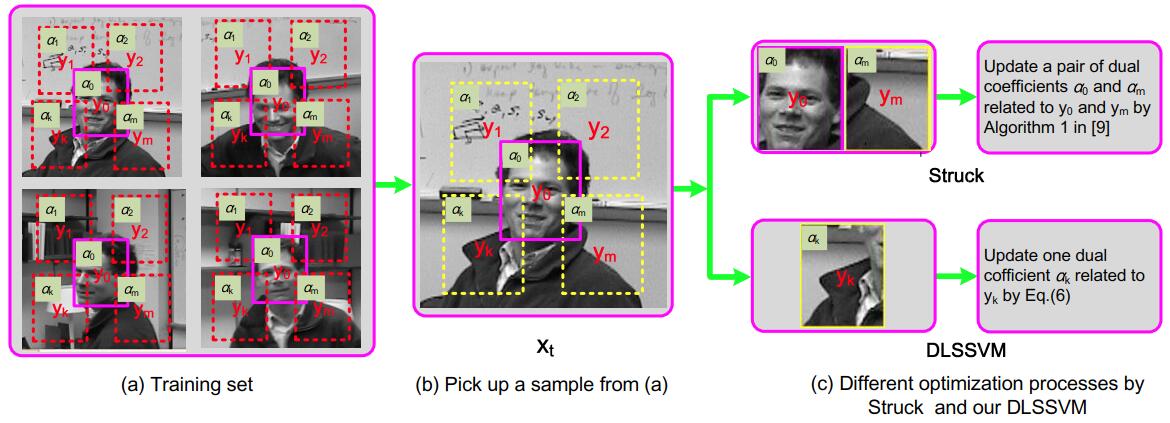
SSVM算法就是Structure SVM的缩写,其本身和Struck极为相似,那么它和Struck有哪些不同呢?
与Struck的不同
从下面这张图应该就可以看出来了吧,SSVM与Struck的不同支取在于,Struck训练时采用SMO,需要一对支持向量来进行训练,而这对支持向量又需要通过十次(代码中的参数)迭代来选取,而SSVM训练时,采取闭式解来优化参数,DCD(Dual Coordinate Descent),Paper中的Title为 Optimization with closed form solution。
搞数学的都知道(虽然我不是搞数学的),闭式解比数值解不知道高到哪里去了,那么感受一下闭式解的求解方程吧,对于一个样本k,DCD方法首先选择一个剧烈变化的最大误差
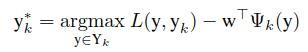
为了估计alpha,我们首先分离变量(将输出误差设置为0),alpha就被表示为下面的公式
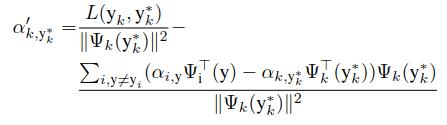
带入W取得近似解
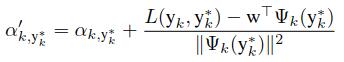 再定义一个因子
再定义一个因子
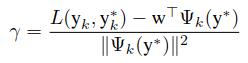
然后w的更新模型就可以表示为下士
![]()
在更新完w后,问题就简单了,下面就是结构化预测的输出公式
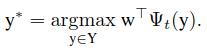
特征选取
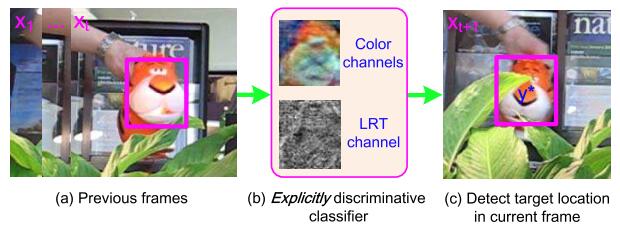
没用采用Haar、Hog之类的特征,直接裸数据+LRT,对于彩色图像就是RGB+LRT四通道,对于灰度图像就是Gray+LRT三通道。LRT就是Local Rank Transform,局部秩变换是一种非参数变换,对光照变化不敏感,以增加光照适应性。
算法实现
这个确实没什么好说的,典型的track-by-detection思路,一样的地方之前在Struck都讲过了,不一样的地方就是闭式解优化。

参考文献
[1]. Ning, J., et al. Object tracking via dual linear structured SVM and explicit feature map. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
Struck采用的SMO一次选择优化两个支持向量,而DLSSVM采用的DCD一次只需优化一个支持向量,DLSSVM强调采用线性核,以获得求解的快速性,即使采用高维特征,其速度相对Struck仍有较大优势,性能也有明显提升。但相对于最近很火的KCF,SSVM显得有点落寞,高速高性能SSVM算法仍需深入研究。
struck和KCF(CSK)确实是目前考虑速度和效果综合起来最好的trackers。在实际工程应用中用了像素特征的KCF(也就是CSK 作者的ECCV论文),效果吊打公司以前的跟踪算法,何止是吊打,简直是按在地上摩擦。当然,公司以前用的是mean-shift……
您好,想问一个问题,φ(t,y)是什么?是当前帧图像的特征吗?如果是的话,这个特征为什么会与y有关,关于特征,如果用神经网络提取的话不是只用图像就好了吗?
y就是矩形框,特征坑定跟y有关系了
提取的特征肯定是与y相关的,这个好理解,但是在计算特征的时候是用不到y的吧?
你是对一个图像块计算的特征,这个图像块就是y