刚有一个idea,用语义分割来做图像跟踪,搜了一下发现已经有人做过了,细细的看了下Paper,和自己相当还不一样。FCN是深度学习语义分割的鼻祖,而这片Paper的名字叫做FCNT,看了之后发现我误会了,此FCN非彼FCN,由于是比较早的算法了,性能和MEEM处于同一层次,不过考虑到这是深度学习方法用于跟踪的重要实践,还是做个笔记好了。
博主认为图像跟踪过程的本质就是语义的跟踪(我是这么理解的),所以,使用语义分割来完成图像跟踪是自然而然想到的。事实上深度学习用于图像跟踪,也就是利用了其深层特征中的语义信息。这篇博客就主要介绍这篇文献:Visual Tracking with Fully Convolutional Networks。
Motivation
深度学习跟踪算法之前诞生了许多优秀的方法,它们是基于构建外观模型来进行跟踪的,这些方法又可以分为两种,一种是生成式,通过最小化重建误差来构建外观模型,另一种是判别式,通过构建一个分类器区分前景和背景(就是目标检测的思路),但是这些方法都是手工选取特征的,手工选取特征的种种不足就不多讲了,于是采用深度学习方法来进行跟踪。
经过一些实验观察发现:
- 一、CNN中有的特征有效,有的特征包含噪声,所以我们需要选择特征
- 二、激活的特征层是局部稀疏,包含语义的
- 三、高层编程语义,底层编码特征信息



Paper中还介绍了一组实验,简单的说就是,对于一个已经训练好的人脸识别检测网络,选取3副人脸图像,分先分类正确时重建误差较小,选择不同人的人脸图像测试重建误差,发现使用两个层的特征可以得到更为鲁棒的结果。
Architecture
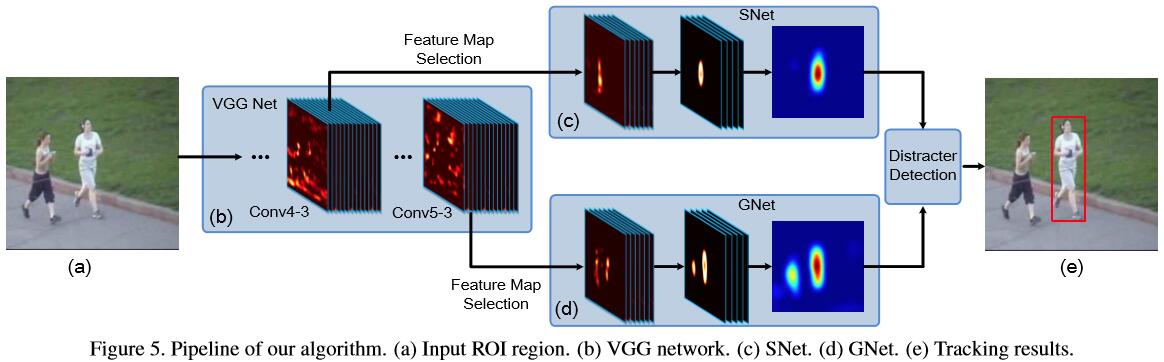
在预训练好的VGG网络基础上增加了,SNET和GNET做在线训练,通过两个heatmap来得到位置。本身内容不多,就简要的说一下。
模型使用最小化heatmap误差来训练SNET回合GNET
![]()
特征图选择只在初始时进行。通过将特征图对应位置设置为0来判断影响,根据如下公式s的变化来判断f的重要性,这个具体看Paper了
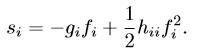
还有一个细节就是最终位置的确定,是采用了高斯混合模型,结合两张heatmap来进行计算的。
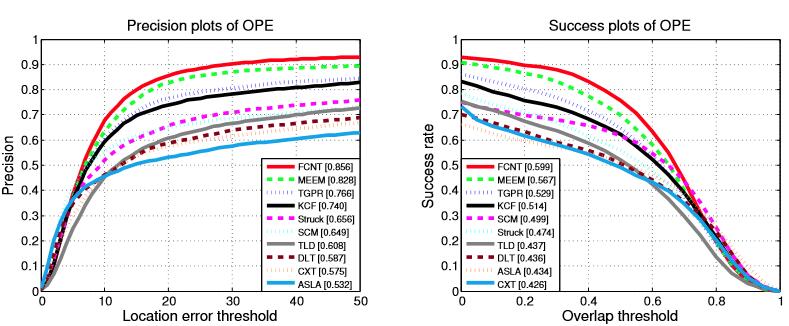
Results
实验结果站在当时的角度还是很优秀的,比MEEM好一点,MEEM是长时间领先,被推荐到PAMI上的算法,当然,和现在的方法比已经差远了,不得不感叹这个领域研究进展的速度。