FCN语义分割算法已经在很多主流深度学习平台上实现了,包括Caffe、TenserFlow、MatConvNet等。这篇博客主要介绍如何在MatConvNet上运行起FCN语义分割,包括CPU和GPU版本。博主的平台是Matlab2017a+Cuda8.0。
下载中心
- FCN-Paper论文:下载地址 [可选]
- MatConvNet:下载地址
- FCN-MatConvNet:下载地址
- VOC2011训练数据:下载地址[voc10],下载地址[voc11],下载地址[voc12]
- VOC12语义分割Benchmark:下载地址
- MatConvNet-VGG预训练模型:下载地址
- MatConvNet-FCN预训练模型:下载地址 [可选]
- Caffe FCN预训练模型:下载地址 [可选]
- CUDA加速,cuDNN运行库:下载地址 [可选]
配置步骤
1.下载代码
这里需要下载两份代码,一个是FCN的代码,另一个是MatConvNet代码,将MatConvNet中的代码放入根目录下,将文件夹名重命名为matconvnet。
2. 配置MatConvNet
2.1 使用CPU
使用CPU的话直接编译就可以了,不需要进行额外配置。(至少博主目前使用的v1.0-beta23是这样,如果你使用的版本不同最好参照官网说明)。具体编译过程参见2.3的代码
2.2 使用GPU,CUDA加速
需要有支持cuda的显卡,在英伟达官网下载cudnn库,将文件放入local文件夹下。
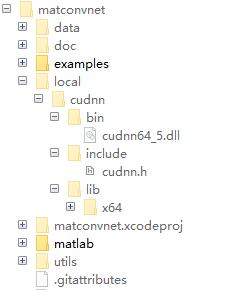
同时,在编译MatConvNet过程中,需要指定该文件夹,参见下面的编译代码。
2.3 编译MatConvNet
下面的脚本是博主写的,原先代码里面没用,使用enableGpu变量来控制是否编译GPU版本,每次切换平台都需要重新编译,所以有个if 1控制是否重新编译。使用GPU时注意下面的路径设置,配置好之后直接运行下面的脚本就可以了。
clear
addpath('utils','models','matconvnet/matlab');
global enableGpu;
enableGpu = true;
vl_setupnn();
if 1 % recompile when change patform
if enableGpu
vl_compilenn('enableGpu', true, 'enableCudnn', true, 'enableDouble', false,...
'cudnnRoot', 'matconvnet/local/cudnn');
else
vl_compilenn();
end
end
如果是cuda7.5及以下,直接使用官方版本的MatConvNet就可以了,博主使用cuda8.0,在使用的时候做了些修改,具体改了哪些博主也忘记了(当时跑一个跟踪demo,改的时候也没注意,反正就是名字啊,目录啊什么的,自己debug完全可以解决),后面会释出博主修改后的matconvnet。
如果出现编译错误,那么就需要自己定位错误,自己debug了,可能出现问题的原因主要有:编译环境配置(编译器,路径,cuda版本等),代码版本问题(目前博主没遇到过,因为MatConvNet在历史上有几次大变动,模型数据格式都变了,所以版本对应是可能导致问题的原因之一)等等0.0
3.下载数据
3.0 VGG-VD-16预训练模型
这里要知道,FCN是会调用VGG模型的,所以要下载 imagenet-vgg-verydeep-16.mat 模型文件,并方法./data/models/文件夹下。
3.1 训练数据
在下载中心下载数据,放入./data/archives文件夹下,并根据代码中的设置重命名:
根据选择版本的voc数据库 重命名为 VOC2010trainval.tar/ VOC2011trainval.tar /VOC2012trainval.tar
benchmark.targz 重命名为 berkeleyVoc12Segments.tar.gz
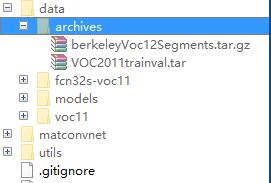
这里也可以选择直接运行fcnTrain,Matlab会自己下载,只是担心官网下载速度慢,发现使用迅雷下载速度会更快,于是建议自己下载两个数据压缩包,然后重命名,放入对应文件夹下,运行脚本时会自动检查数据并解压到对应目录。
3.2 预训练模型
如果你不想训练自己的模型,直接使用预训练好的模型(这也是MatConvNet最方便的一点),那么直接下载预训练好的模型放到./data/models/目录下即可。
4.调试训练
这一步也是最麻烦的,因为每个人遇到的问题都可能不同,所以多半时候需要自己debug,这里只提供一些个人经验了,如果有补充可以在评论区进行回复,博主可以进一步完善。
4.1 运行调试
直接运行fcnTrain()函数,这是注意其中设置的路径是否与自己设置的路径对应,第一步就是其中的VOCSetup的两个函数,其中会对数据进行解压缩处理,保证配置正确,才能定位到数据。如果提示找不到数据,那么打断点调试,看看缺了哪些数据,这些数据是否可以不要。
博主使用Matlab2017a,Cuda8.0,cudnn,硬件平台是gtx1070,后面的问题和解决仅供参考,博主在调试过程中分别遇到如下问题:
问题1:getDatasetStatistics: computing segmentation stats for training image 1 报错
错误定位到:getDatasetStatistics.m 文件 Line 9
lb = imread(sprintf(imdb.paths.classSegmentation, imdb.images.name{train(i)})) ;
经过调试,下面这个地方,看出问题来了吧,这里把’\’替换成’\\’ 或者 ‘/’ 就可以了,否则文件是读不出来的
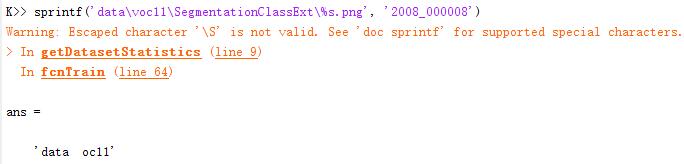
解决:将Line9处的代码替换为:
lb = imread(sprintf(strrep(imdb.paths.classSegmentation, '\', '\\'), imdb.images.name{train(i)})) ;
问题2:fcnTrain(line95) 错误代码 Reference to non-existent field ‘gpus’.
错误信息:
Error in fcnTrain (line 95)
bopts.useGpu = numel(opts.train.gpus) > 0 ;
错误信息是所,opts.train没有gpus字段,那么就要从opts.train查起了,经过调试发现整个opts.train都是空的,检查了下发现可能是需要在输入参数中进行设置?然后再github上直接找到了答案

解决:trainOpts 替换为opts.train 并将Line23 修改为 opts.train = [];
问题3:和问题1一样,字符串的问题,如下图

解决:定位错误到getbatch.m Line51, 替换成如下代码:
labelsPath = sprintf(strrep(imdb.paths.classSegmentation, '\', '\\'), imdb.images.name{images(i)}) ;
版本在不断更新,并且希望将自己的经验汇总贡献一篇教程,或者遇到了其它问题,可以在下方留言给博主。
开心的训练吧:
CPU:
直接成功

GPU:
需要再进行debug
1. 虽然编译了gpu版本的matconvnet,但是 opts.train.gpus 依然为空,最后使用的还是CPU,于是就到github去查了一下,迅速找到答案:opts.train.gpus = [1] ;
2. 然后又爆出错误:The CUDA error code was: CUDA_ERROR_ILLEGAL_ADDRESS. 继续Google,地址问题,轻松解决。
*18年2月8日补充:关于CUDA_ERROR_ILLEGAL_ADDRESS:
博主曾经采用CUDA8.0、VS2013和matconvnet-1.o-beta23测试成功(具体解决方法事后想不起来,太久远了,似乎是折腾了许久cudnn版本)
一旦牵扯到环境,问题通常都比较复(玄)杂(学),下面的引用是评论区马同学对各个环境进行的测试,最终使用GTX1070+win10调通fcn:
GTX 1070显卡 + windows10
一开始使用matconvnet-1.0-beta25.tar.gz + matlab2017b + CUDA8.0 会出现The CUDA error code was: CUDA_ERROR_ILLEGAL_ADDRESS的情况,
(1)在使用 CUDA8.0 时无论搭配哪种版本的 cudnn都无法解决这种问题,所以将CUDA8.0降为CUDA7.5,但是又会出现 Unsupported gpu architecture ‘compute_61’的情况,根据
http://blog.csdn.net/a1154761720/article/details/53395414 中的解决方法解决了。
(2)matconvnet-1.0-beta25.tar.gz编译GPU时只能用vs2015,vs2013不能使用,CUDA7.5编译又只能用vs2013.所以不能最新的matconvnet。
(3)CUDA8.0对应matlab2017,降低CUDA的版本,也就降低了matlab的版本,降为matlab2015
(4)最后的配置为
CUDA7.5 + matlab2015 + vs2013,可以直接下载别人编译好的文件
博客地址为 http://blog.csdn.net/zhjm07054115/article/details/51569450
视频以及代码的地址为 http://www.studyai.com/course/detail/64bf671f1ecf44ed9a8404a198604321
再次感谢马同学的测试和分享!
GTX1070超频到1860MHz之后,大约训练6个小时就可以出结果了,还是相当给力的。(博主训练一般就停了,6小时是根据同学训练的时间预估的)
4.2 预训练调试
上面搞定,这个就简单多了,使用预训练模型的方式有三种,根据fcnTest中的 switch case 发现三种分别是matconvnet、ModelZoo、TVG。
‘matconvnet’就是使用自己训练存储好的网络模型,以‘input’为起点
‘ModelZoo’就是使用Caffe的模型,这里我们发现目录中还有一个文件fcnTestModelZoo,如果使用matcaffe,那么可以从这个脚本开始。
‘TVG’是什么呢?我不清楚,它以’coarse’层结尾,而下载的模型是以upscore结尾的。
所以我们经过简单调试,发现需要修改的地方只有五个:
1. 修改modelPath为我们下载的模型文件
2. 修改modelFamily为 ‘TVG’
3. 修改‘TVG’结尾为‘upscore’(原先是‘coarse’),发现我们下载的模型并没有‘coarse’
4. 和训练时候一样的字符串文字,修改Line114为: labelsPath = sprintf(strrep(imdb.paths.classSegmentation, ‘\’, ‘\\’), name) ;
5. 如果使用gpu,单个GPU情况下,修改opts.gpus = [1]
% experiment and data paths
opts.expDir = 'data/fcn32s-voc11' ;
opts.dataDir = 'data/voc11' ;
%opts.modelPath = 'data/fcn32-voc11/net-epoch-50.mat' ;
opts.modelPath = 'data/models/pascal-fcn32s-dag.mat' ; // Line 9
opts.modelFamily = 'TVG' ;
[opts, varargin] = vl_argparse(opts, varargin) ;
........
case 'TVG' // Line 88
net = dagnn.DagNN.loadobj(load(opts.modelPath)) ;
net.mode = 'test' ;
%predVar = net.getVarIndex('coarse') ;
predVar = net.getVarIndex('upscore') ;
inputVar = 'data' ;
imageNeedsToBeMultiple = false ;
end
结果存储在结果路径下面,重新运行如果不删除原先的结果文件,那么会直接显示结果而不会再训练,所以要删掉原先文件再训练。
如果要测试自己的数据,那么直接im = imread(…) 的地方修改就可以了,总之调通之后,自己看代码吧
测试
开心的运行demo吧

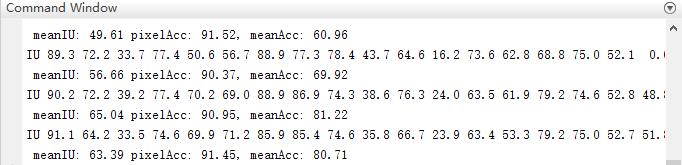
虽然训练时间很长,检测速度还是挺快的,检测时候大概需要3G显存
致敬
‘Fully Convolutional Models for Semantic Segmentation’, Jonathan Long, Evan Shelhamer and Trevor Darrell, CVPR, 2015
我的也是1070显卡,用GPU训练时也出现了The CUDA error code was: CUDA_ERROR_ILLEGAL_ADDRESS. 请问如何解决?
可能是某个地方cuda的配置路径,或者cuda版本号,或者参数的问题。
抱歉,时间太久,我也记不太清楚了~
非常感谢,那您能告诉我从哪个网址可以找到解决办法吗?我是西南林业大学的在读硕士,正在做FCN的实验,就差这一步了,代码调不通确实不甘心啊。多谢师兄了
师兄,您好!目前我也在做FCN 相关实验,调通原始代码只是第一步,目前我已经完成,制作自己的数据集,进行具体问题应用还有很所问题要处理,这个实验要求紧就是想跟您交流一下。不知道您的项目现在进行的怎么样了。
此外很感谢博主的分享,根据博文的提示让我少走了很多弯路。非常感谢!
你好,我最近也是想用FCN训练自己的数据,有一些问题,还希望可以得到您的帮助!
对了,最好使用Matlab2017
我的就是MATLAB2017b.986772475,我的qq号,方便的话加一下我吧,请多多指教