darknet是一个C语言实现的深度学习框架,几乎不依赖任何库,安装编译都很方便,训练好的模型可以直接在opencv上部署,堪称业界良心。这篇博客主要包含目标检测数据标注和预处理、yolo_v3代码编译、模型训练、在opencv上部署,都是简要的笔记。
〇、参考链接
这些博客写的比较详细,博主也是参照这些博客一步步走下来的,在这些博客基础上总结扩充的:
一、数据标注
使用labelimg,有python版本,也有打包好的二进制文件(window/linux)直接用:下载地址 本站暂存的windows版本
我们使用Pascal标注格式,将标注文件xml和图像存放在一起,放到同一目录下。标注的时候可以在软件里设置自动保存(View->AutoSaving),就不需要一直弹窗确认了。下面是软件的快捷键,可以提高标注效率。
| Ctrl + u | Load all of the images from a directory |
| Ctrl + r | Change the default annotation target dir |
| Ctrl + s | Save |
| Ctrl + d | Copy the current label and rect box |
| Space | Flag the current image as verified |
| w | Create a rect box |
| d | Next image |
| a | Previous image |
| del | Delete the selected rect box |
| Ctrl++ | Zoom in |
| Ctrl– | Zoom out |
| ↑→↓← | Keyboard arrows to move selected rect box |
二、数据增强
标注好图像之后,为了取得好的训练效果,常常需要对数据集进行扩充,在变化图像的时候谁带也把标注文件一起处理好,这样同源的图像就不用重复标注了。
有一些Python的脚本比较好用,博主根据自己需要写了一个matlab的(这里没哟该标注框的位置,如果你用的变换有目标位置发生改变的,要换算一下矩形框位置进行修改)
clear
FOLDER = 'D:/data/drone/';
EXT = '.jpg';
output_path = '1';
mkdir(output_path);
files = dir([FOLDER '*' EXT]);
% calculate transform position
for i = 1:length(files)
file = files(i);
img = imread(fullfile(file.folder, file.name));
% read xml
xmlfile = fullfile(file.folder, [file.name(1:end-4) '.xml']);
fp = fopen(xmlfile, 'r');
A = fscanf(fp,'%c');
fclose(fp);
%output_path = file.folder;
% transform image
parfor trans = 1:10
img_new_name = fullfile(output_path, ...
[file.name(1:end-4) '.' sprintf('%02d',trans) '.JPG']);
xml_new_name = fullfile(output_path, ...
[file.name(1:end-4) '.' sprintf('%02d',trans) '.xml']);
% transform image
img_new = data_enhance(img, trans);
imwrite(img_new, img_new_name);
% trnasform xml
A_new = strrep(A, file.name, ...
[file.name(1:end-4) '.' sprintf('%02d',trans) '.JPG']);
fp = fopen(xml_new_name, 'w');
fprintf(fp, '%s', A_new);
fclose(fp);
end
end
里面用到的图像变换函数(后面几个变换会改变标注框的位置,如果要用后面的变换,上面那个文件中还需要修改矩形的位置):
function [img] = data_enhance(img_src,type)
img = img_src;
if type == 0
img = img_src;
elseif type == 1
img = imsharpen(img_src);
elseif type == 2
img = imnoise(img_src, 'gaussian');
elseif type == 3
img = imnoise(img_src, 'poisson');
elseif type == 4
img = img_src * 0.8;
elseif type == 5
img = img_src * 0.9;
elseif type == 6
img = img_src * 1.1;
elseif type == 7
img = img_src * 1.2;
elseif type == 8
img = imguidedfilter(img_src);
elseif type == 9
img = imgaussfilt(img_src,2);
elseif type == 10
img = rgb2gray(img_src);
img = cat(3, img, img, img);
elseif type == 31
img = rot90(img_src,180);
elseif type == 32
img = fliplr(img_src);
elseif type == 33
img = fliplr(img_src);
img = rot90(img,180);
elseif type == 41
img = imrotate(img_src,2);
elseif type == 42
img = imratate(img_src,3);
elseif type == 43
img = imresize(img_src, 0.8);
elseif type == 44
img = imresize(img_src, 1.2);
end
img = uint8(img);
end
三、数据处理
我们已经有了训练需要的数据,但是它与darknet规定的格式不同,darknet并不认识它,这一步就是我们在训练之前需要把数据和标注的格式处理成darknet需要的格式。
先新建一个VOCdevkit目录,在其下新建一个VOC2007目录,再在VOC2007下新建Annotations、ImageSets、JPEGImages三个目录,再在ImageSets下面新建Main目录
最终目录结构如下(先不用管里面的txt文件,txt文件都是脚本生成的):
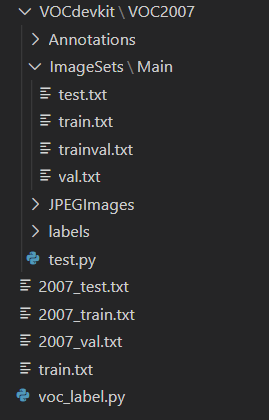
然后我们把标注好的图像放到JPEGImages目录下,然后把标注好的xml文件放到Annotations目录下,把test.py脚本放到VOC2007目录下,把voc_label.py脚本。
test.py脚本的作用是生成训练检测文件列表。test.py最开头的参数可以调整用于训练和验证的图像比例。
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
voc_label.py脚本的作用是按照上一步生成的文件列表,将标注也转化成darknet认识的txt格式,也就是目录最外层的txt,这几个txt是真正最后传递给darknet的。该脚本使用有两点要注意:
下面的脚本里默认图片是jpg格式,如果你的图片是其它格式,那么需要在脚本中修改
修改目录 Sets 和类别 classes,脚本下载链接:voc_label.py
wget https://pjreddie.com/media/files/voc_label.py
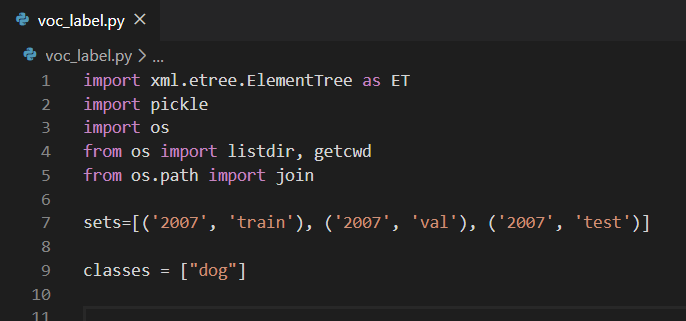
首先运行test.py脚本,再运行voc_label.py脚本,看到对应txt文件生成,就大功告成了
四、darknet代码编译
1. 下载代码
git clone https://github.com/pjreddie/darknet
2. 编译代码
如果是linux,直接修改MakeFile,是使用GPU还是CPU选择下就可以了,纯c写的,没啥依赖,有装opencv的话添加下路径,没有opencv也可以运行。
如果是windows,需要读github首页的readme,来确认自己的环境,cuda版本不一样的改下配置文件,该装cudnn的装cudnn,该重新cmake的重新cmake,该把cuda.procs放到指定位置就按照readme给的环境来配置就好,一般多折腾会儿都没什么问题。
3. 下载模型
也是在官网已经有了预训练好的模型,这里再贴两个模型链接,都提前下下来:
待会儿测试的时候会跑一个识别,用到的预训练模型:
wget https://pjreddie.com/media/files/yolov3.weights
预训练的时候可能会用到darknet53网络的权重:
wget https://pjreddie.com/media/files/darknet53.conv.74
这两个文件都放到和darknet.exe同一个目录下。
4. 运行测试demo
测试下效果:
darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg

五、训练模型
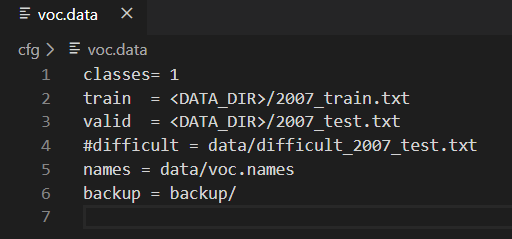
1.修改cfg/voc.data
这里指定了训练时使用的数据,我们选择之前脚本生成的txt就好
2.修改data/voc.names和coco.names
修改成自己标注时候的类别就可以
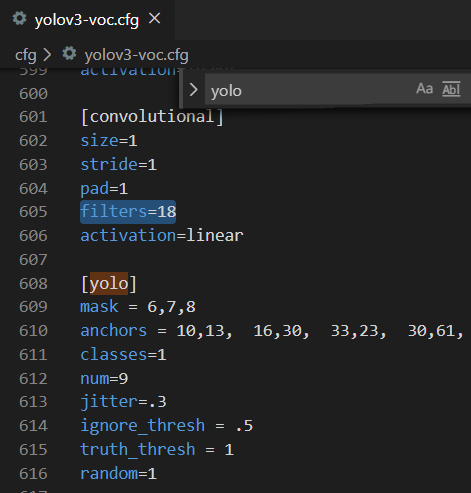
3.修改参数文件cfg/yolov3-voc.cfg
ctrl+f搜 yolo, 总共会搜出3个含有yolo的地方。
每个地方都必须要改2处, filters:3*(5+len(classes));因为输出是矩形4个location+1个置信度+1个类别
其中:classes: len(classes) = 1,这里以单个类dog为例
filters = 18
classes = 1
可修改:random = 1:原来是1,显存小改为0。(是否要多尺度输出。)
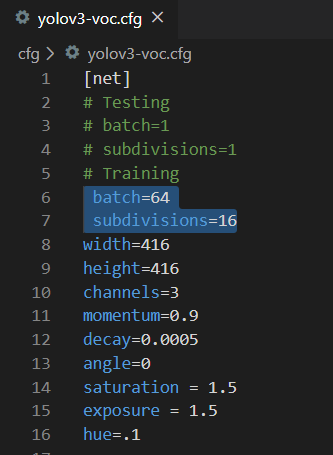
参数文件开头的地方可以选训练的batchsize,要注意,训练时要改batchsize,测试时要强制成1,。博主使用的显卡是8G现存,每次只能算4张或者5张图,所以选了64/16=4张来算,你需要根据自己显卡的情况进行配置,免得显存爆掉。
4.训练模型
我们在先前下载的darknet53权重基础上微调
darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
博主使用大概700张图片,训练到200次的时候结果已经可以看了,一晚上大概跑了3000轮,默认没100次迭代后模型备份到backup目录下

六、应用部署
opencv3.4.2之后dnn模块就支持yolov3了,因为ipp和openmp并行,opencv对cpu的利用效率很高,测试过opencv的实现比darknet本来的实现要快九倍,博主也测了下,也差不多是这么快,所以把模型通过opencv部署可以有比较快的运行速度,当然,如果你需要更快的速度,能配置一块儿比较好的显卡就另当别论了。
| OS | Framework | CPU/GPU | Time(ms)/Frame |
|---|---|---|---|
| Linux 16.04 | Darknet | 12x Intel Core i7-6850K CPU @ 3.60GHz | 9370 |
| Linux 16.04 | Darknet + OpenMP | 12x Intel Core i7-6850K CPU @ 3.60GHz | 1942 |
| Linux 16.04 | OpenCV [CPU] | 12x Intel Core i7-6850K CPU @ 3.60GHz | 220 |
| Linux 16.04 | Darknet | NVIDIA GeForce 1080 Ti GPU | 23 |
| macOS | DarkNet | 2.5 GHz Intel Core i7 CPU | 7260 |
| macOS | OpenCV [CPU] | 2.5 GHz Intel Core i7 CPU | 400 |
直接上博主的代码吧,只有一个cpp文件,也可以在github直接下载下来用:
P-Chao / yolov3-opencv
load yolov3 and detection by opencv dnn module
#include<opencv2/opencv.hpp>
float confThreshold = 0.5f;
float nmsThreshold = 0.4f;
int inpWidth = 416;
int inpHeight = 416;
std::vector<std::string> classes;
std::vector<cv::String> getOutputsNames(const cv::dnn::Net& net) {
static std::vector<cv::String> names;
if (names.empty()) {
std::vector<int> outLayers =
net.getUnconnectedOutLayers();
std::vector<cv::String> layersNames =
net.getLayerNames();
names.resize(outLayers.size());
for (size_t i = 0; i < outLayers.size(); ++i)
names[i] = layersNames[outLayers[i]-1];
}
return names;
}
// Draw the predicted bounding box
void drawPred(int classId, float conf, int left, int top, int right, int bottom, cv::Mat & frame) {
//Draw a rectangle displaying the bounding box
cv::rectangle(frame, cv::Point(left, top), cv::Point(right, bottom), cv::Scalar(0, 0, 255));
//Get the label for the class name and its confidence
std::string label = cv::format("%.2f", conf);
if (!classes.empty()) {
CV_Assert(classId < (int)classes.size());
label = classes[classId] + ":" + label;
}
//Display the label at the top of the bounding box
int baseLine;
cv::Size labelSize = cv::getTextSize(label, cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
top = std::max(top, labelSize.height);
putText(frame, label, cv::Point(left, top), cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(255, 255, 255));
}
void postprocess(cv::Mat& frame, const std::vector<cv::Mat>& outs) {
std::vector<int> classIds;
std::vector<float> confidences;
std::vector<cv::Rect> boxes;
for (size_t i = 0; i < outs.size(); ++i) {
float* data = (float*)outs[i].data;
for (int j = 0; j < outs[i].rows; ++j, data += outs[i].cols) {
cv::Mat scores = outs[i].row(j).colRange(5, outs[i].cols);
cv::Point classIdPoint;
double confidence;
cv::minMaxLoc(scores, 0, &confidence, 0, &classIdPoint);
if (confidence > confThreshold) {
int centerX = (int)(data[0] * frame.cols);
int centerY = (int)(data[1] * frame.rows);
int width = (int)(data[2] * frame.cols);
int height = (int)(data[3] * frame.rows);
int left = centerX - width / 2;
int top = centerY - height / 2;
classIds.push_back(classIdPoint.x);
confidences.push_back((float)confidence);
boxes.push_back(cv::Rect(left, top, width, height));
}
}
}
// Perform non maximum suppression to eliminate redundant overlapping boxes with
// lower confidences
std::vector<int> indices;
cv::dnn::NMSBoxes(boxes, confidences, confThreshold, nmsThreshold, indices);
for (size_t i = 0; i < indices.size(); ++i) {
int idx = indices[i];
cv::Rect box = boxes[idx];
drawPred(classIds[idx], confidences[idx], box.x, box.y,
box.x + box.width, box.y + box.height, frame);
}
return;
}
int detect(cv::Mat& image) {
// Load names of classes
std::string classesFile = "coco.names";
std::string line;
std::ifstream ifs(classesFile.c_str());
while (std::getline(ifs, line))
classes.push_back(line);
std::string modelConfiguration = "yolov3.cfg";
std::string modelWeights = "yolov3.weights";
// Load the network
cv::dnn::Net net = cv::dnn::readNetFromDarknet(
modelConfiguration, modelWeights);
net.setPreferableBackend(cv::dnn::DNN_BACKEND_OPENCV);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CPU);
if (image.empty()) {
std::cout << "input image empty !!!" << std::endl;
return 1;
}
cv::Mat blob;
cv::dnn::blobFromImage(image, blob, 1/255.0,
cv::Size(inpWidth, inpHeight), cv::Scalar(0,0,0), true, false);
net.setInput(blob);
std::vector<cv::Mat> outs;
net.forward(outs, getOutputsNames(net));
// Remove the bounding boxes with low confidence
postprocess(image, outs);
// Profile
std::vector<double> layersTimes;
double freq = cv::getTickFrequency() / 1000;
double t = net.getPerfProfile(layersTimes) / freq;
std::string label = cv::format("Inference time for a frame: %.2f ms", t);
cv::putText(image, label, cv::Point(0, 15),
cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 0, 255));
cv::Mat detectedFrame;
image.convertTo(detectedFrame, CV_8U);
cv::imwrite("predict.png",detectedFrame);
return 0;
}
int main(int argc, char * argv[]) {
cv::Mat image = cv::imread("D:/workspace/cvyolo/data/dark.jpg");
cv::imshow("image", image);
detect(image);
cv::waitKey();
return 0;
}
OK,希望能有帮助。
你好!
请问博主有尝试用libtorch 部署yolov3 吗?
我想知道怎么用libtorch部署yolov3
谢谢!
没有用libtorch部署过 0.0 ~
请问您实现部署了吗,我最近也想实现