Hugging face起初是一家总部位于纽约的聊天机器人初创服务商,聊天机器人服务没搞起来,但是hugging face在github上开源的transformers库大火,已经成为机器学习届最活跃的开源社区。这篇博客简单介绍下怎样从hugggingface获取数据和使用模型。
hugging face的官方网站:http://www.huggingface.co./ 。 我们基本可以从这里捞到很多数据集、预训练模型、课程 和 文档。
博主也主要是摘抄学习,前排放参考链接:
http://fancyerii.github.io/2021/05/11/huggingface-transformers-1/
https://zhuanlan.zhihu.com/p/535100411
https://www.heywhale.com/mw/notebook/60a3868506b942001798960e
安装
pip install transformers测试安装是否成功
from transformers import pipeline模型组成
一般transformer模型有三个部分组成,tokenizer、model、post processing。
Tokenizer的作用是把输入文本做切分,然后变成向量
Model负责根据输入的变量提取语义信息,输出logits
Post Processing根据模型输出语义信息,执行具体的nlp任务,比如生成标签、关系分析等
其中Model又分为三种模型,Encoder模型(如Bert,用于句子分类、命名实体识别等)、Decoder模型(如GPT,用于文本生成),Seq2Seq模型(如Bart,用于摘要、翻译、生成性问答等)
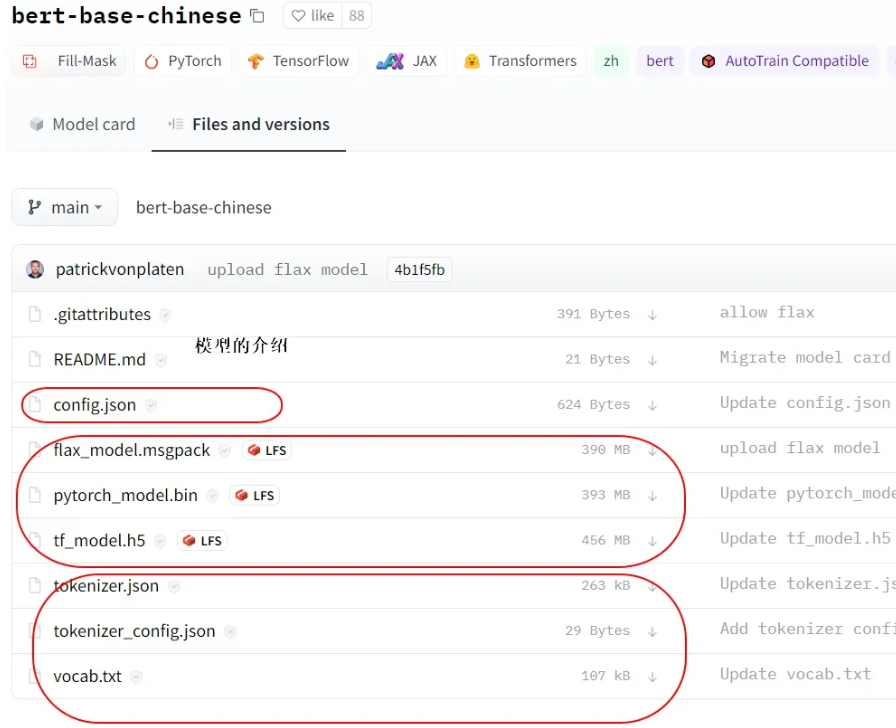
我们以一个中文模型的例子“Bert-base-Chinese”为例,其中包含几类文件,
config中的参数用来控制模型样式、隐藏层宽度和深度、激活函数类别等。
tokernizer(包含三个文件),其中包含配置和字典
其它几个稍大一些的是打包好的模型文件
Tokenizer
我们先导入官方模型,这里可以写模型名称从官网下载,也可以写本地路径,加在已经下载好的或者自己训练好的模型。
import torch
from transformers import BertModel, BertTokenizer, BertConfig
# 首先要import进来
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
config = BertConfig.from_pretrained('bert-base-chinese')
config.update({'output_hidden_states':True}) # 这里直接更改模型配置
model = BertModel.from_pretrained("bert-base-chinese",config=config)我们可以用tokenizer的encode方法把id编码成token,看下tokenizer的编码结果:
注意101是[CLS], 102是[SEP]
print(tokenizer.encode("生活的真谛是美和爱")) # 对于单个句子编码
print(tokenizer.encode_plus("生活的真谛是美和爱","说的太好了")) # 对于一组句子编码
# 输出结果如下:
[101, 4495, 3833, 4638, 4696, 6465, 3221, 5401, 1469, 4263, 102]
{'input_ids': [101, 4495, 3833, 4638, 4696, 6465, 3221, 5401, 1469, 4263, 102, 6432, 4638, 1922, 1962, 749, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1,
1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
# 也可以直接这样用
sentences = ['网络安全开发分为三个层级',
'车辆系统层级网络安全开发',
'车辆功能层级网络安全开发',
'车辆零部件层级网络安全开发',
'测试团队根据车辆网络安全目标制定测试技术要求及测试计划',
'测试团队在网络安全团队的支持下,完成确认测试并编制测试报告',
'在车辆确认结果的基础上,基于合理的理由,确认在设计和开发阶段识别出的所有风险均已被接受',]
test1 = tokenizer(sentences)
print(test1) # 对列表encoder
print(tokenizer("网络安全开发分为三个层级")) # 对单个句子encoder有encode 方法,自然也有decode方法,decode可以把ID解码成token
decoded_sequence = tokenizer.decode(encoded_sequence)Attention Mask
如果输入是一个batch,那么会返回Attention Mask,它可以告诉模型那部分是padding的,从而要mask掉。
我们可以单独对两个句子进行编码,返回两个不同长度的序列。
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
sequence_a = "This is a short sequence."
sequence_b = "This is a rather long sequence. It is at least longer than the sequence A."
encoded_sequence_a = tokenizer(sequence_a)["input_ids"]
encoded_sequence_b = tokenizer(sequence_b)["input_ids"]
>>> len(encoded_sequence_a), len(encoded_sequence_b)
(8, 19)这样没有办法把它们放到一个Tensor里。我们需要把短的序列padding或者长的序列阶段truncate。
我们可以看到第一个ID后面补了很多0, 我们约定0代表padding,但是用起来很麻烦,我们通过一个attention mask明确标出哪个是padding
padded_sequences = tokenizer([sequence_a, sequence_b], padding=True)
print(padded_sequences["input_ids"])
[[101, 1188, 1110, 170, 1603, 4954, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [101, 1188, 1110, 170, 1897, 1263, 4954, 119, 1135, 1110, 1120, 1655, 2039, 1190, 1103, 4954, 138, 119, 102]]
>>> padded_sequences["attention_mask"]
[[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]Model
我们以当前的例子,用model实例化bertmodel类,来处理文本
from transformers import pipeline
# 运行该段代码要保障你的电脑能够上网,会自动下载预训练模型,大概420M
unmasker = pipeline("fill-mask",model = "bert-base-uncased") # 这里引入了一个任务叫fill-mask,该任务使用了base的bert模型
unmasker("The goal of life is [MASK].", top_k=5) # 输出mask的指,对应排名最前面的5个,也可以设置其他数字
# 输出结果如下,似乎都不怎么有效哈。
[{'score': 0.10933303833007812,
'token': 2166,
'token_str': 'life',
'sequence': 'the goal of life is life.'},
{'score': 0.03941883146762848,
'token': 7691,
'token_str': 'survival',
'sequence': 'the goal of life is survival.'},
{'score': 0.032930608838796616,
'token': 2293,
'token_str': 'love',
'sequence': 'the goal of life is love.'},
{'score': 0.030096106231212616,
'token': 4071,
'token_str': 'freedom',
'sequence': 'the goal of life is freedom.'},
{'score': 0.024967126548290253,
'token': 17839,
'token_str': 'simplicity',
'sequence': 'the goal of life is simplicity.'}]Post Processing
后处理通常根据模型来决定,比如需要一个二分类任务,我们就可以用softmax层做一个二分类,得到两个标签的概率。
Demo Code
贴一段IMDB电影评论数据感情分析的例子(一共50000条评论,正面负面各25000条),直接看代码比较好
# _*_ coding:utf-8 _*_
# 利用深度学习做情感分析,基于Imdb 的50000个电影评论数据进行;
import torch
from torch.utils.data import DataLoader,Dataset
import os
import re
from random import sample
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from transformers import BertModel, BertTokenizer
from tqdm import tqdm
# 路径需要根据情况修改,要看你把数据下载到哪里了
# 数据下载地址在斯坦福官网,网上搜索就有
data_base_path = r"./imdb_test/aclImdb"
# 这个里面是存储你训练出来的模型的,现在是空的
model_path = r"./imdb_test/aclImdb/mode"
#1. 准备dataset,这里写了一个数据读取的类,并把数据按照不同的需要进行了分类;
class ImdbDataset(Dataset):
def __init__(self,mode,testNumber=10000,validNumber=5000):
# 在这里我做了设置,把数据集分成三种形式,可以选择 “train”默认返回全量50000个数据,“test”默认随机返回10000个数据,
# 如果是选择“valid”模式,随机返回相应数据
super(ImdbDataset,self).__init__()
# 读取所有的训练文件夹名称
text_path = [os.path.join(data_base_path,i) for i in ["test/neg","test/pos"]]
text_path.extend([os.path.join(data_base_path,i) for i in ["train/neg","train/pos"]])
if mode=="train":
self.total_file_path_list = []
# 获取训练的全量数据,因为50000个好像也不算大,就没设置返回量,后续做sentence的时候再做处理
for i in text_path:
self.total_file_path_list.extend([os.path.join(i,j) for j in os.listdir(i)])
if mode=="test":
self.total_file_path_list = []
# 获取测试数据集,默认10000个数据
for i in text_path:
self.total_file_path_list.extend([os.path.join(i,j) for j in os.listdir(i)])
self.total_file_path_list=sample(self.total_file_path_list,testNumber)
if mode=="valid":
self.total_file_path_list = []
# 获取验证数据集,默认5000个数据集
for i in text_path:
self.total_file_path_list.extend([os.path.join(i,j) for j in os.listdir(i)])
self.total_file_path_list=sample(self.total_file_path_list,validNumber)
def tokenize(self,text):
# 具体要过滤掉哪些字符要看你的文本质量如何
# 这里定义了一个过滤器,主要是去掉一些没用的无意义字符,标点符号,html字符啥的
fileters = ['!','"','#','$','%','&','\(','\)','\*','\+',',','-','\.','/',':',';','<','=','>','\?','@'
,'\[','\\','\]','^','_','`','\{','\|','\}','~','\t','\n','\x97','\x96','”','“',]
# sub方法是替换
text = re.sub("<.*?>"," ",text,flags=re.S) # 去掉<...>中间的内容,主要是文本内容中存在<br/>等内容
text = re.sub("|".join(fileters)," ",text,flags=re.S) # 替换掉特殊字符,'|'是把所有要匹配的特殊字符连在一起
return text # 返回文本
def __getitem__(self, idx):
cur_path = self.total_file_path_list[idx]
# 返回path最后的文件名。如果path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素。
# cur_filename返回的是如:“0_3.txt”的文件名
cur_filename = os.path.basename(cur_path)
# 标题的形式是:3_4.txt 前面的3是索引,后面的4是分类
# 如果是小于等于5分的,是负面评论,labei给值维1,否则就是1
labels = []
sentences = []
if int(cur_filename.split("_")[-1].split(".")[0]) <= 5 :
label = 0
else:
label = 1
# temp.append([label])
labels.append(label)
text = self.tokenize(open(cur_path,encoding='UTF-8').read().strip()) #处理文本中的奇怪符号
sentences.append(text)
# 可见我们这里返回了一个list,这个list的第一个值是标签0或者1,第二个值是这句话;
return sentences,labels
def __len__(self):
return len(self.total_file_path_list)
# 2. 这里开始利用huggingface搭建网络模型
# 这个类继承再nn.module,后续再详细介绍这个模块
#
class BertClassificationModel(nn.Module):
def __init__(self,hidden_size=768):
super(BertClassificationModel, self).__init__()
# 这里用了一个简化版本的bert
model_name = 'distilbert-base-uncased'
# 读取分词器
self.tokenizer = BertTokenizer.from_pretrained(pretrained_model_name_or_path=model_name)
# 读取预训练模型
self.bert = BertModel.from_pretrained(pretrained_model_name_or_path=model_name)
for p in self.bert.parameters(): # 冻结bert参数
p.requires_grad = False
self.fc = nn.Linear(hidden_size,2)
def forward(self, batch_sentences): # [batch_size,1]
sentences_tokenizer = self.tokenizer(batch_sentences,
truncation=True,
padding=True,
max_length=512,
add_special_tokens=True)
input_ids=torch.tensor(sentences_tokenizer['input_ids']) # 变量
attention_mask=torch.tensor(sentences_tokenizer['attention_mask']) # 变量
bert_out=self.bert(input_ids=input_ids,attention_mask=attention_mask) # 模型
last_hidden_state =bert_out[0] # [batch_size, sequence_length, hidden_size] # 变量
bert_cls_hidden_state=last_hidden_state[:,0,:] # 变量
fc_out=self.fc(bert_cls_hidden_state) # 模型
return fc_out
# 3. 程序入口,模型也搞完啦,我们可以开始训练,并验证模型的可用性
def main():
testNumber = 10000 # 多少个数据参与训练模型
validNumber = 100 # 多少个数据参与验证
batchsize = 250 # 定义每次放多少个数据参加训练
trainDatas = ImdbDataset(mode="test",testNumber=testNumber) # 加载训练集,全量加载,考虑到我的破机器,先加载个100试试吧
validDatas = ImdbDataset(mode="valid",validNumber=validNumber) # 加载训练集
train_loader = torch.utils.data.DataLoader(trainDatas, batch_size=batchsize, shuffle=False)#遍历train_dataloader 每次返回batch_size条数据
val_loader = torch.utils.data.DataLoader(validDatas, batch_size=batchsize, shuffle=False)
# 这里搭建训练循环,输出训练结果
epoch_num = 1 # 设置循环多少次训练,可根据模型计算情况做调整,如果模型陷入了局部最优,那么循环多少次也没啥用
print('training...(约1 hour(CPU))')
# 初始化模型
model=BertClassificationModel()
optimizer = optim.AdamW(model.parameters(), lr=5e-5) # 首先定义优化器,这里用的AdamW,lr是学习率,因为bert用的就是这个
# 这里是定义损失函数,交叉熵损失函数比较常用解决分类问题
# 依据你解决什么问题,选择什么样的损失函数
criterion = nn.CrossEntropyLoss()
print("模型数据已经加载完成,现在开始模型训练。")
for epoch in range(epoch_num):
for i, (data,labels) in enumerate(train_loader, 0):
output = model(data[0])
optimizer.zero_grad() # 梯度清0
loss = criterion(output, labels[0]) # 计算误差
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 打印一下每一次数据扔进去学习的进展
print('batch:%d loss:%.5f' % (i, loss.item()))
# 打印一下每个epoch的深度学习的进展i
print('epoch:%d loss:%.5f' % (epoch, loss.item()))
#下面开始测试模型是不是好用哈
print('testing...(约2000秒(CPU))')
# 这里载入验证模型,他把数据放进去拿输出和输入比较,然后除以总数计算准确率
# 鉴于这个模型非常简单,就只用了准确率这一个参数,没有考虑混淆矩阵这些
num = 0
model.eval() # 不启用 BatchNormalization 和 Dropout,保证BN和dropout不发生变化,主要是在测试场景下使用;
for j, (data,labels) in enumerate(val_loader, 0):
output = model(data[0])
# print(output)
out = output.argmax(dim=1)
# print(out)
# print(labels[0])
num += (out == labels[0]).sum().item()
# total += len(labels)
print('Accuracy:', num / validNumber)
if __name__ == '__main__':
main()