KAN(Kolmogorov-Arnold Networks)相比于MLP的改进在于激活函数的可学习,可以用更少量的参数来做更深层次的拟合,极大减少了网络参数,增强了网络的可解释性,KAN缺点在于训练过于缓慢,这篇笔记主要是对论文主干的翻译,我们先看看KAN的论文。(Paper有48页,慢慢啃)
从概率论到信息论:由浅入深理解 KL 散度和交叉熵
在机器学习里,我们经常会遇到两个非常重要的概念: 它们经常出现在分类任务、知识蒸馏、VAE、语言模型训练、强化 … 阅读更多
a blog driven by interest~
在机器学习里,我们经常会遇到两个非常重要的概念: 它们经常出现在分类任务、知识蒸馏、VAE、语言模型训练、强化 … 阅读更多

这篇博客主要介绍Codebook机制和CodeFormer,之前介绍了一种类似包含dictionary的算法 RestoreFormer和RestoreFormer++,他们有一些共通的机制,之前看VQ-VAE时候没有把Codebook梳理清楚,这里补补坑。
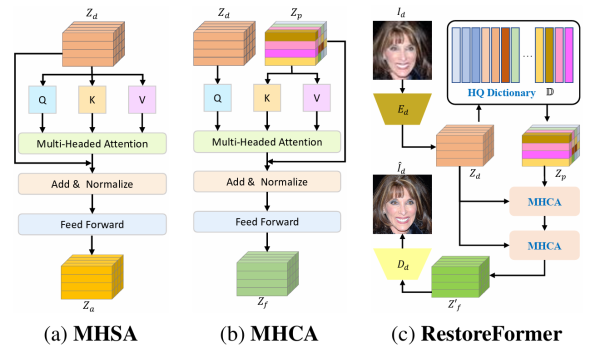
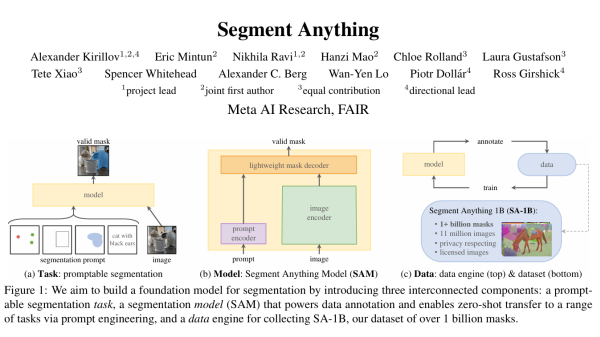
RestoreFormer收录于CVPR2022,其后续工作RestoreFormer++被收录于TPAMI2023,属于图像复原领域比较具有代表性的工作。这里需要一些transformer的前置知识,可以参见Vision Transformer.
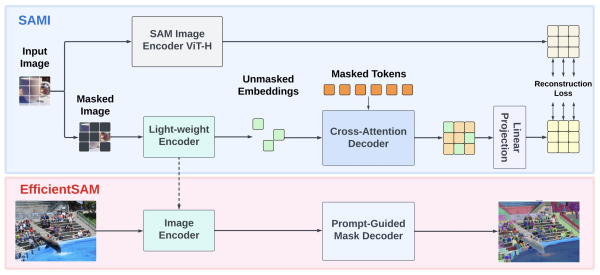
开始之前需要一些前置知识,关于SAM请移步:SAM论文笔记, 关于ViT基础请移步:Vision Transformer,关于MAE请移步知乎:MAE(Masked Autoencoders) – 知乎 (zhihu.com)。
SAM的解码器已经足够快,但是图像编码器用的ViT还是很大,于是很多工作就在SAM基础上改进性能,进行轻量化,其中有一些比较出色的工作 比如 MobileSAM 、 FastSAM 和 EfficientSAM 等,已经将SAM推到了相当轻量。这篇博客主要是EfficientSAM的论文笔记。
在多模态、生成模型中会用到几种类型的自编码器,通常具有Encoder、Decoder的结构。

京东方的一篇论文,主打轻量级网络做Real-Time SR,只有一层,对标传统bicubic上采样,因为轻量,所以实用,同时一层网络的可解释性也更强。
论文地址:Edge-SR:Super-Resolution For The Masses
通过视觉测量深度的方法目前分为如下几种,一种是双目立体匹配,该方法的好处是有一个明确的物理模型,存在视差的概念,深度信息是根据时差转换得到,另一种是单目运动,该方法也可以看成一种特殊的双目模型或者多目模型,只不过它是时间上的多目,还有一种方法是完全的单目深度估计,直接由网络端到端给出深度,单目网络在可解释性和可移植性上不如双目和单目运动,但是其效果没有比双目差太多。
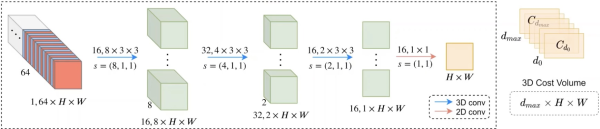
随着近年来车载系统视觉方案不断完善,立体视觉问题不断收敛,学界出现了一批轻量级网络,效果还不差,这篇博客主要介绍一个轻量级双目立体匹配网络mobilestereonet,后文简称MSN。博主理解MSN主要贡献还是在与对网络模型的压缩,骨干和后面的特征提取大量使用深度可分离卷积,而论文中提及的一些网络结构,经过博主实验下来,这些并不重要(比如3d卷积用分组卷积替代,网络性能并没有明显降低),直接感受是,参数确实更少,计算也更少。
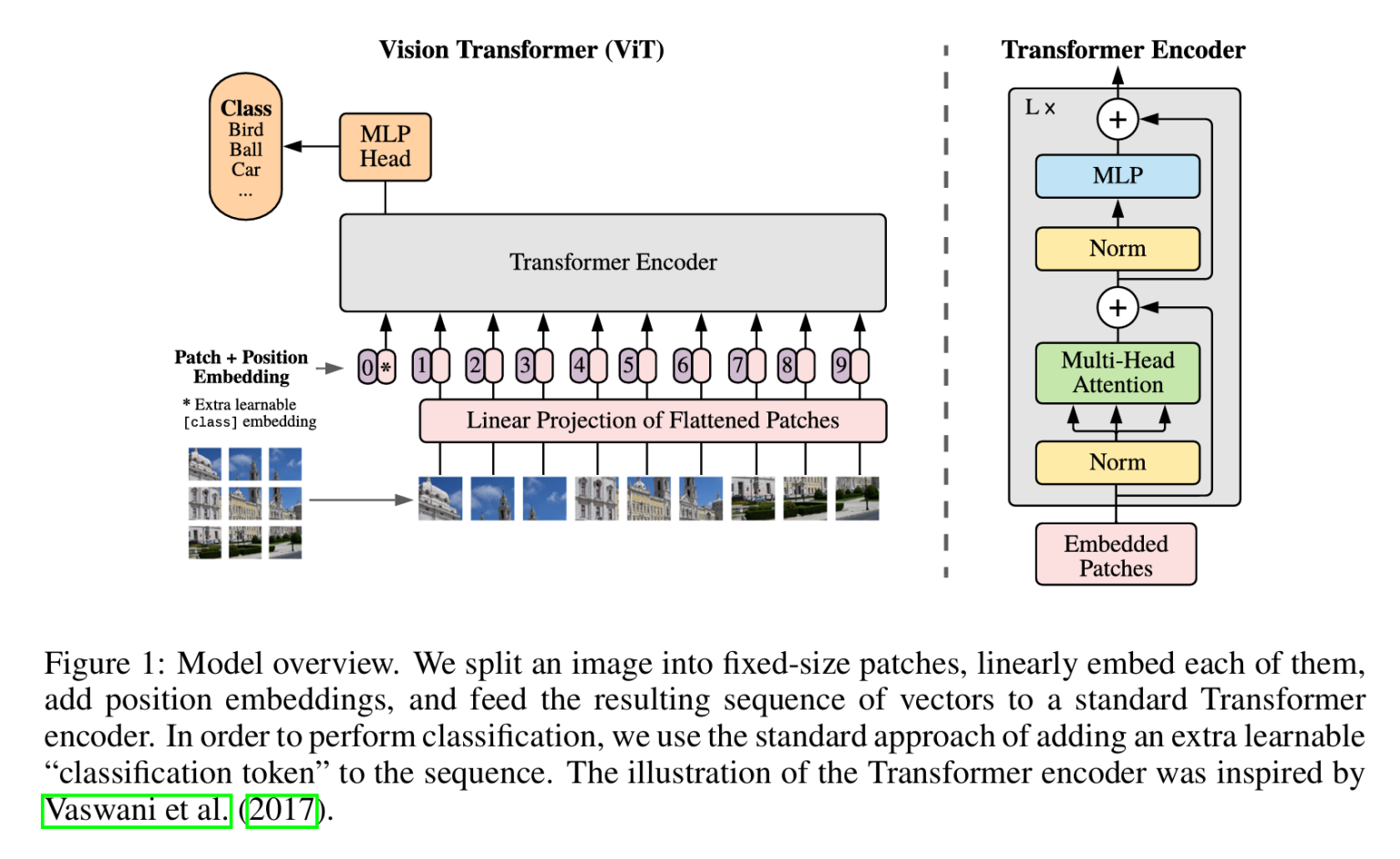
Transformer从NLP发展到视觉,开始改变视觉问题的处理方式,SwinTransformer和ViT都是典型的网络结构,典型的Transformer结构中大量使用Multi-Head Attention。ViT基于经典的Transformer模型,采用图像分块的方式将图像处理的问题转化为seq2seq的问题,这篇博客会从Attention开始,介绍到ViT。
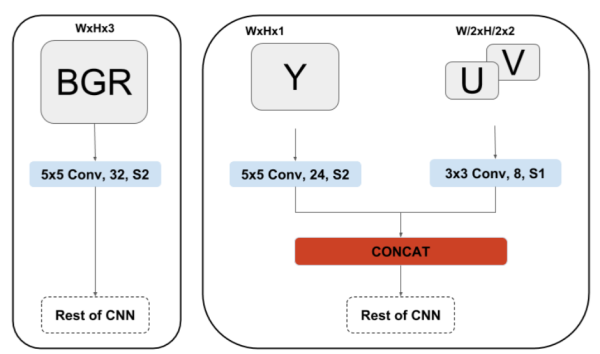
在ISP pipe中,最后输出的一般都是YUV图像,YUV420的数据量是RGB数据量的两倍,我们在送入CNN处理的时候处理RGB图像居多,如果CNN也可以直接输入YUV图像,那么前级需要的带宽就会减为输入RGB图的一半。
YUVMultiNet提供了一种实用的结构来处理YUV图像。这篇博客只会介绍处理YUV的这种结构,如果对MultiNet感兴趣可以移步原文:https://arxiv.org/pdf/1904.05673.pdf
曝光图像融合通常的应用场景是HDR,传统的图像融合算法分为两类,一类是像素级的图像融合,通过将图像不同频段分离,在像素层及进行融合,另一类是基于变换域的方法,把图像变换到频率、小波域进行图像融合,最后再反变换回来,有些类似于同态滤波的形式。博主之前介绍过Mertens Exposure Fusion、Pyramid Blending、Possion Blending等都是经典的传统图像融合算法。
传统图像融合算法在融合曝光程度差异小的图像时非常有效,但是图像之间曝光差异程度大的时候融合结果就会出现瑕疵,事实上极端曝光情况下的图像融合具有非常大的挑战,这篇博客介绍一种基于无监督的图片融合算法DeepFuse,看名字就知道这是一种CNN的算法实现。
darknet是一个C语言实现的深度学习框架,几乎不依赖任何库,安装编译都很方便,训练好的模型可以直接在opencv上部署,堪称业界良心。这篇博客主要包含目标检测数据标注和预处理、yolo_v3代码编译、模型训练、在opencv上部署,都是简要的笔记。
大概两三年前,博主有发过一篇综述:深度学习综述(二)深度学习用于目标检测 ,那时候主要是Fast-RCNN系列到yolo和ssd系列,之后很久不务正业没有跟进了。最近又开始跟进下,摘抄些笔记,没啥有深度的东西。
梳理下目标检测算法,大致经历了如下发展: 传统机器学习方法(slide window+feature extraction) -> Region Proposal + CNN -> Anchor Based CNN -> Anchor Free CNN。本文简单介绍Anchor Base方法中最著名的YOLO和SSD,Anchor Free方法中的CornerNet。

在图像分类应用下,诞生了不少经典网络。ShuffleNet以速度快和便于移植而著称,这篇博客将简单介绍ShuffleNet,以及Pytorch下模型的训练、保存、微调、生成CaffeModle。