在多模态、生成模型中会用到几种类型的自编码器,通常具有Encoder、Decoder的结构。
参考链接:https://zhuanlan.zhihu.com/p/388620573
https://zhuanlan.zhihu.com/p/633744455
https://www.spaces.ac.cn/archives/6760
一、AE(AutoEncoder)
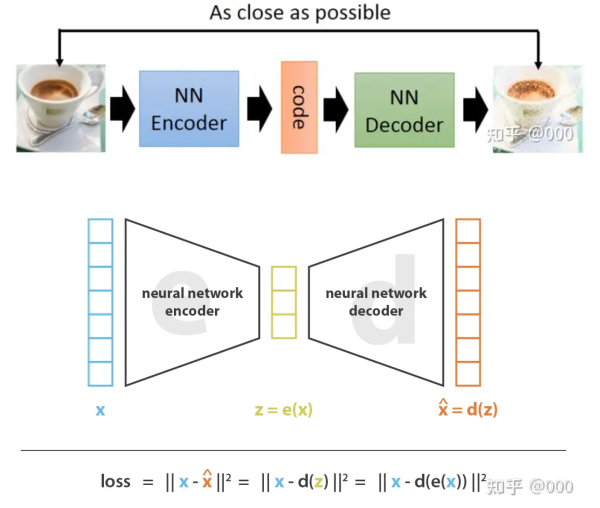
自编码器很简单,诞生也比较早,Encoder、Decoder的结构通常可以理解为数据压缩和降维,encoder把高维的输入空间X变换到低维的隐空间(latent space)Z中。decoder把低维的隐空间Z变换到原来的高维输入空间X中。
隐空间中的 向量z 称为 隐向量(latent vector),隐向量z 可以看作 输入向量x 的低维表示。这个 z 有 latent vector、embedding、code 这些叫法。
模型的训练目标使得重建的hat{x}和原输入x尽可能接近。损失函数采用重建损失(reconstruction loss),即hat{x}和x的交叉熵损失。
z=encoder(x)
\\
\hat{x}=decoder(z)这里盗一下图:
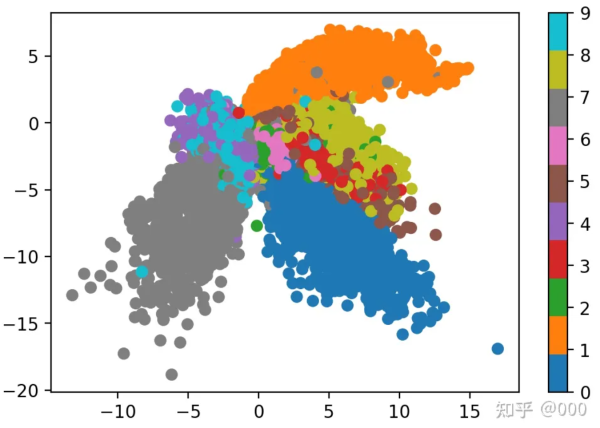
在MNIST数据集中,我们把信息压缩为二维的隐向量,表示出来如下图:
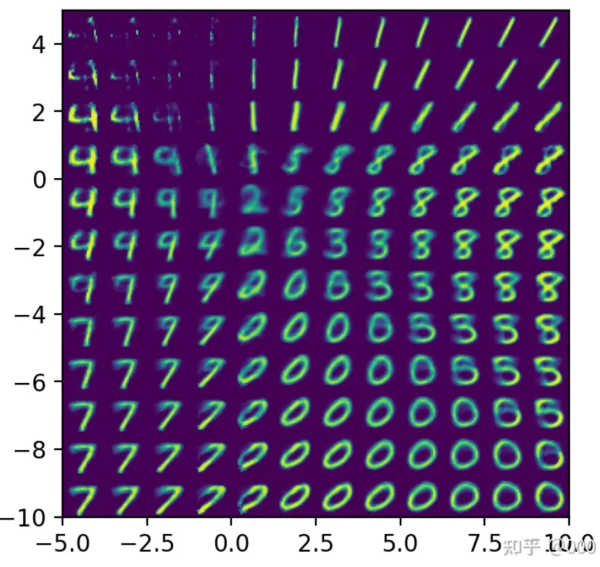
我们注意到AE在隐空间中不是每个点都和表现有对应,这些gap间隙中的隐向量并没有很好的重建效果,MNIST从训练好的隐空间gap间隙中取一些隐向量Z来重建,得到如下结果,重建结果并不好。
为了让学到的 隐空间Z 连续、稠密,就有了VAE。
二、VAE(Variational AutoEncoder,可变分布自编码器)
VAE论文Auto-Encoder Variational Bayes,提出于2013年: https://arxiv.org/abs/1312.6114
在VAE中,encoder不再直接输入隐向量z,而是输出隐向量z的分布(均值mu和标准差sigma),再从这个分钟采样得到隐向量z。
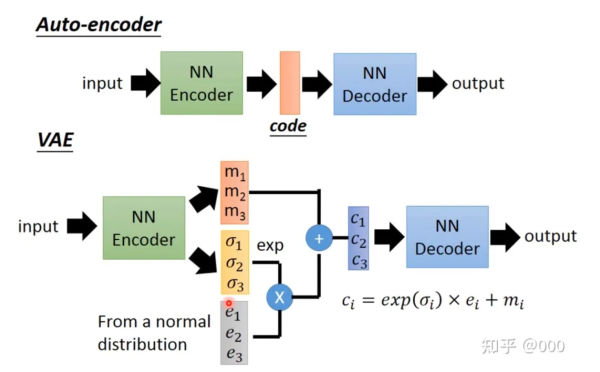
AE将输入encode成隐空间的单个点,而VAE则将输入encode成隐空间的分布。
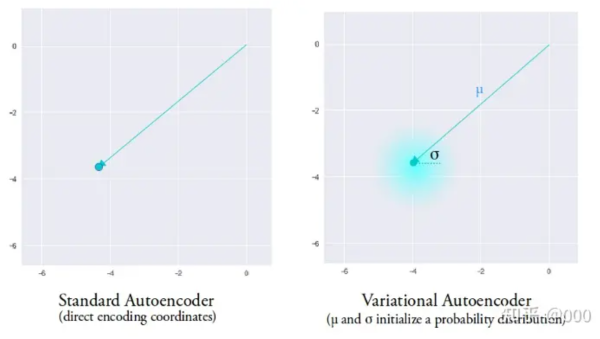
如果训练得到的分布大部分标准差sigma比较小,那么VAE就和普通AE差别不大了。我们希望学到的隐空间Z是连续、稠密、聚在一团而又能很好分靠不同标签的。于是为了避免sigma过小,就在损失函数中加入KL Loss。KL Loss 计算的是N(mu,sigma^2)和标准正态分布N(0,1)的KL散度。
三、VQ-VAE(Vector Quanized-Variational AutoEncoder)向量化的VAE
VQ-VAE来自论文 Neural Discrete Representation Learning(2017年),https://arxiv.org/abs/1711.00937, 也是首个提出codebook机制的生成模型。
VAE学习到的是连续的隐空间缝补,而VQ-VAE想学到离散的隐空间。一个简化的VQ-VAE可以做如下表示:
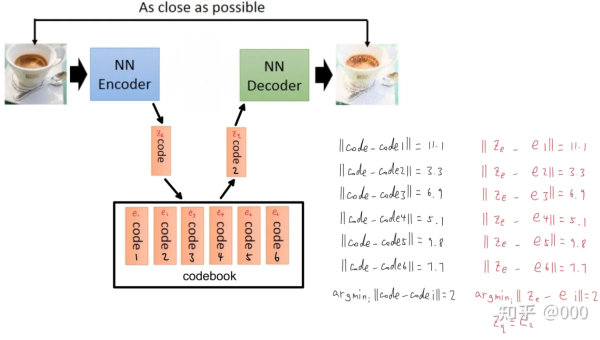
在VQ-VAE中,输入向量经过encoder得到z_e, 然后在codebook,也就是VQ-VAE学习的离散隐空间中,寻找与z_e最为接近的隐向量e_i,将这个隐向量作为decoder。
z_e=encoder(x)
\\
z_q=e_k, \\ \ \ \ (k=argmin_i||z_e-e_i||)
\\
\hat{x}=decoder(z_q)VQ-VAE的隐空间codebook中的隐向量是离散的,数量是固定的有限多的,而VAE中的隐空间中的隐向量是连续的,数量是无限多个的。
让有限数量的隐向量e_i来重建很多不同数据x是很困难的,因此,在VQ-VAE中的encoder会输出很多个向量z_e。论文中图示如下:
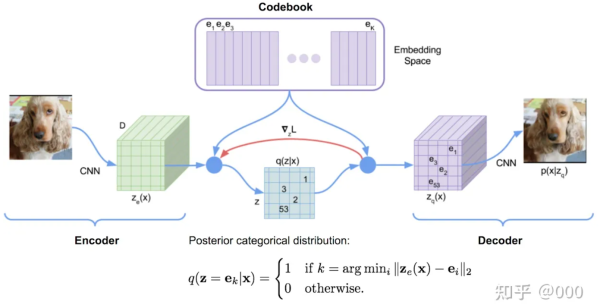
这里 encoder 是 CNN结构,输出 m1×m2 个 D维(D=隐向量的维度) 的 ze。这 m1×m2个向量 分别在 codebook 中寻找与各自最接近的隐向量 ei ( ei 是D维的),然后令对应的 eq=ei 。
例如在上图中,m1=6,m2=6,codebook 中有 K 个隐向量。第3行第3列的 ze 最接近的隐向量是 e3 ,于是令第3行第三列的 zq=e3 ;第5行第3列的 ze 最接近的隐向量是 e53 ,于是令第5行第3列的 zq=e53 。这 m1×m2 个 ze 可以有 K^(m1×m2) 个不同的组合,也就可以重建出 K^(m1×m2) 个不同的图像。
接下来我们考虑VQ-VAE的损失函数:loss = reconstruction loss + codebook loss + commitment loss.
reconstruction loss 就是x和hat{x}的交叉熵损失。
codebook loss,encoder输出ze和隐向量ei的平方损失。
commitment loss, encoder的输出ze与隐向量ei的平方损失。用于训练encoder。
在 VAE 中,希望 隐向量 满足 正态分布(normal distribution),所以损失函数有个 KL loss;在 VQ-VAE 中,隐向量满足 均匀分布(uniform distribution),所以 隐向量的分布(1/K, 1/K, ……, 1/K) 与 完美的隐向量的分布(0, ……, 0, 1, 0, ……, 0) 的 KL散度(计算如下) 是个常数(log K),所以损失函数不需要加 KL loss。
用exponential moving average代替codebook loss,因为 codebook loss 只用于更新 codebook,所以可以不要 codebook loss,直接用 指数滑动平均(exponential moving average) 来更新codebook。
TODO
四、dVAE
DALL-E对VQ-VAE的改进
TODO