Transformer从NLP发展到视觉,开始改变视觉问题的处理方式,SwinTransformer和ViT都是典型的网络结构,典型的Transformer结构中大量使用Multi-Head Attention。ViT基于经典的Transformer模型,采用图像分块的方式将图像处理的问题转化为seq2seq的问题,这篇博客会从Attention开始,介绍到ViT。
参考链接:
Vision Transformer 超详细解读 (原理分析+代码解读) (一) – 知乎 (zhihu.com)
Cross-Attention in Transformer Architecture (vaclavkosar.com)
一、Attention
1. scale-dot attention
NLP中Attention函数可以被描述为一个查询(query)到一系列(键key值value)对的映射,我们简单给下定义公式:
Attention(Query,Source)=\Sigma_{i=1}^{\ell_x}Simularity(Query,Key_i)*Value_i涉及两个问题:Simularity的定义及QKV的涵义。
Simularity直接按照数学上向量相似度的定义即可,就两个向量的点乘,点乘结果越大,方向越一致,则两个向量越相似。我们按照向量长度dk来归一化,再对其结果求softmax归一化,那么我们就得到一个常用的attention函数。(其中Q和V 的来源都是source)
Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})VQK^T的结果就是一个数值范围为0-1的mask矩阵,也可以理解为attention score矩阵。以一系列键值K对在Q上的投影,mask矩阵乘以V就得到过滤后的特征。(博主自己的理解是,以Q特征空间来衡量K,给出一个0-1之间的特征相似度,相似度低的V就被过滤掉,输出过滤后的V,实际是在做特征空间的变换)
更进一步的拓展到搜索领域,QKV分别代表搜索场景中的输入信息、关键信息、返回信息,利用QK建立可变化的权重关系,V建立可变化输入。
补充一点,这里相似度的定义也不一定要用softmax,点积、cos相似性、MLP网络都可以取代这里的softmax,我们后面介绍其它attention时会进一步提到。
2. Self-Attention(自注意力)
自注意力机制,简单来说就是QKV中的Q=K=V,以自身序列作为query,来衡量和自身元素key的相似新,调控以自身value形成的特征。
从自然语言处理的视角来看,Q(查询)、K(键)和V(值)是由同一句话中的每个字基于其它字(包括自身)的关注度得分计算而来。因此,自注意力(Self-Attention)机制的主要目的是使序列关注自身内部各部分之间的关联。
这里,我们需要注意到,K/V中,如果同时替换任意两个字的位置,对最终结果不会由影响,这也就是后面要引入位置embedding的原因。
用代码来说:
class BertSelfAttention(nn.Module):
def __init__(self, config):
self.query = nn.Linear(config.hidden_size, self.all_head_size) # 输入768, 输出768
self.key = nn.Linear(config.hidden_size, self.all_head_size) # 输入768, 输出768
self.value = nn.Linear(config.hidden_size, self.all_head_size) # 输入768, 输出768
def forward(self,hidden_states): # hidden_states 维度是(L, 768)
Q = self.query(hidden_states)
K = self.key(hidden_states)
V = self.value(hidden_states)
attention_scores = torch.matmul(Q, K.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
attention_probs = nn.Softmax(dim=-1)(attention_scores)
out = torch.matmul(attention_probs, V)
return out
这里,关于QKV维度的问题,我们在multi-head attention那里讲。
从网上盗一张图来理解下:(*^____^*)
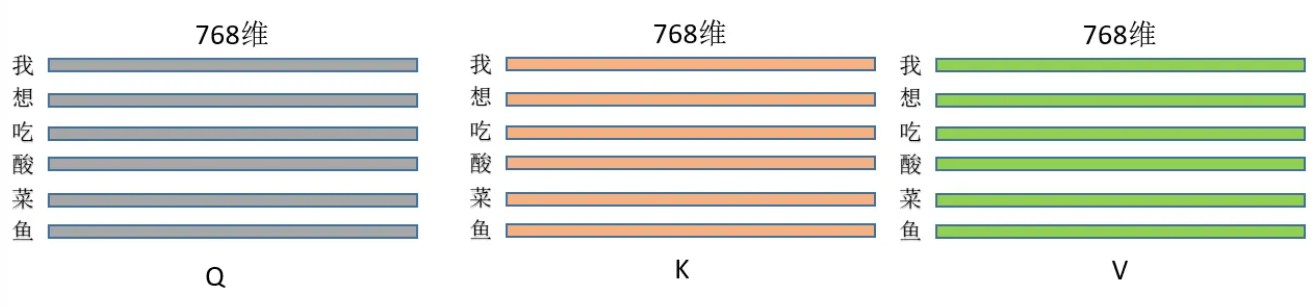
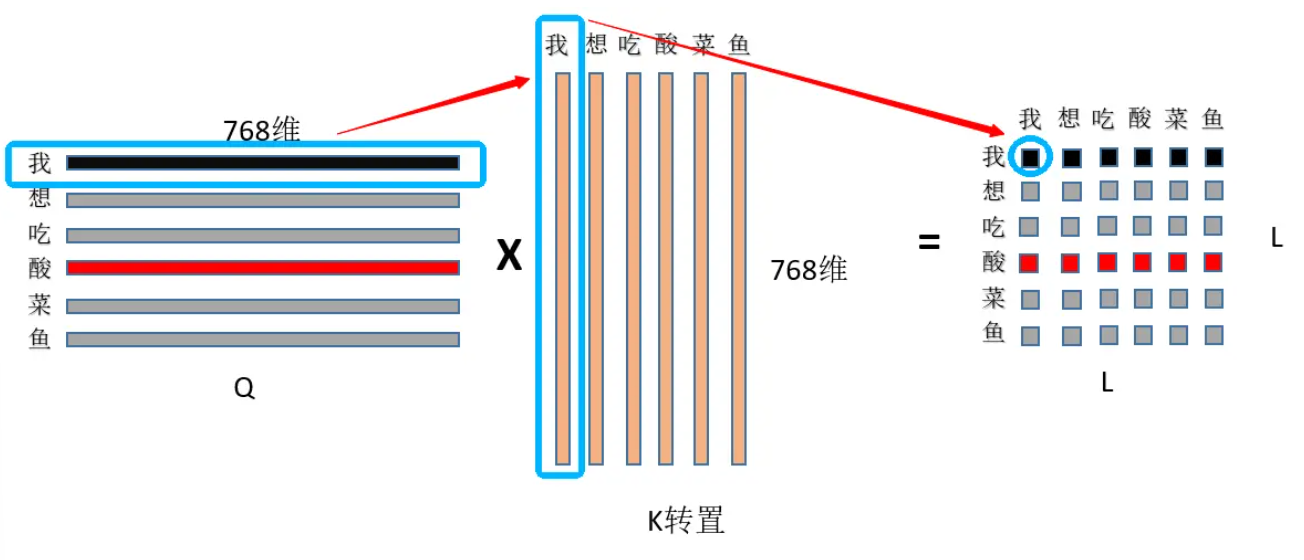
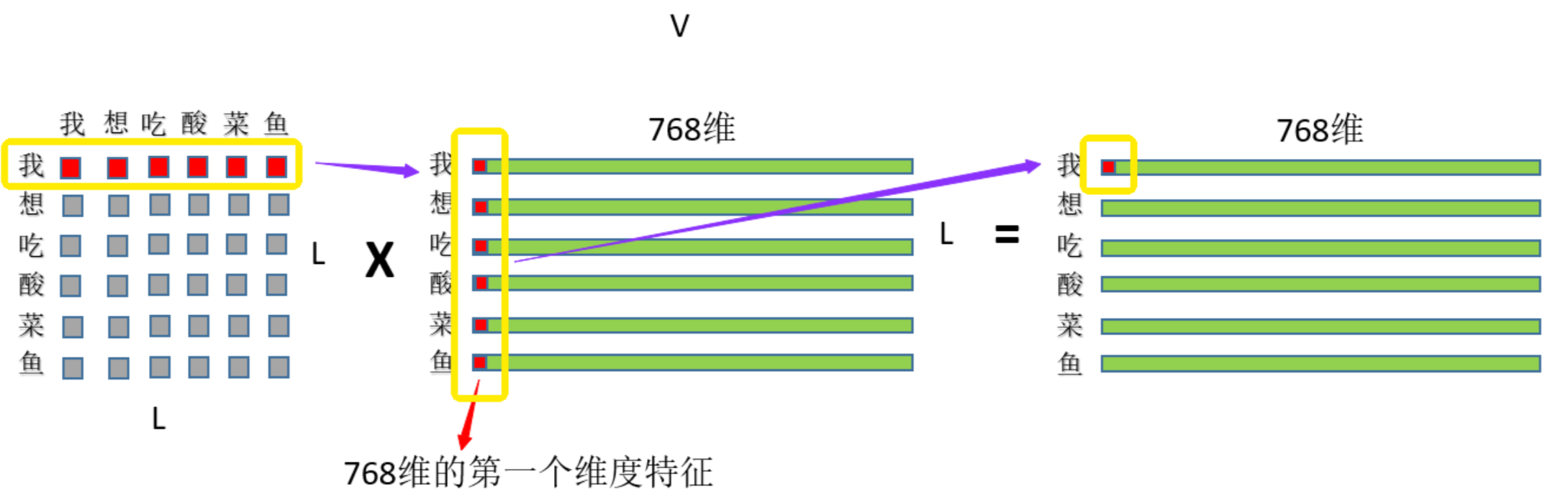
为了方便理解就再盗一张图(*^____^*)
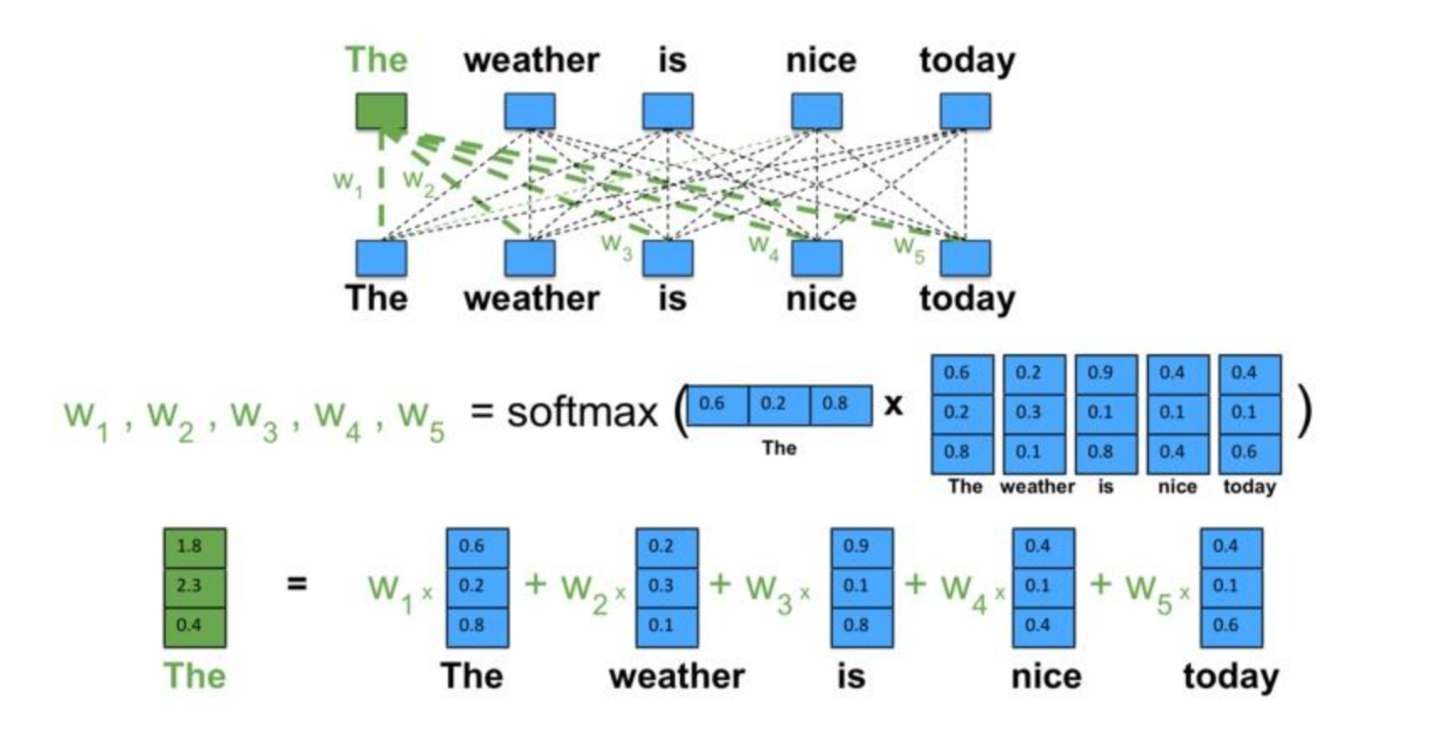
3. Cross-Attention(交叉注意力)
Cross-Attention与Self-Attention类似,不同之处在于Cross-Attention的Q来源于一个序列,而K和V来源于另一个序列,实现了一个序列对另一个序列的“关注”。在后续的Transformer介绍中,我们会看到解码器需通过此机制关注编码器的输出。自注意力与交叉注意力均基于同一核心机制。
这里我们注意,Cross-Attention输出序列的长度是和Query长度一致的。(在下图中则为3,一个Q对应一个输出)
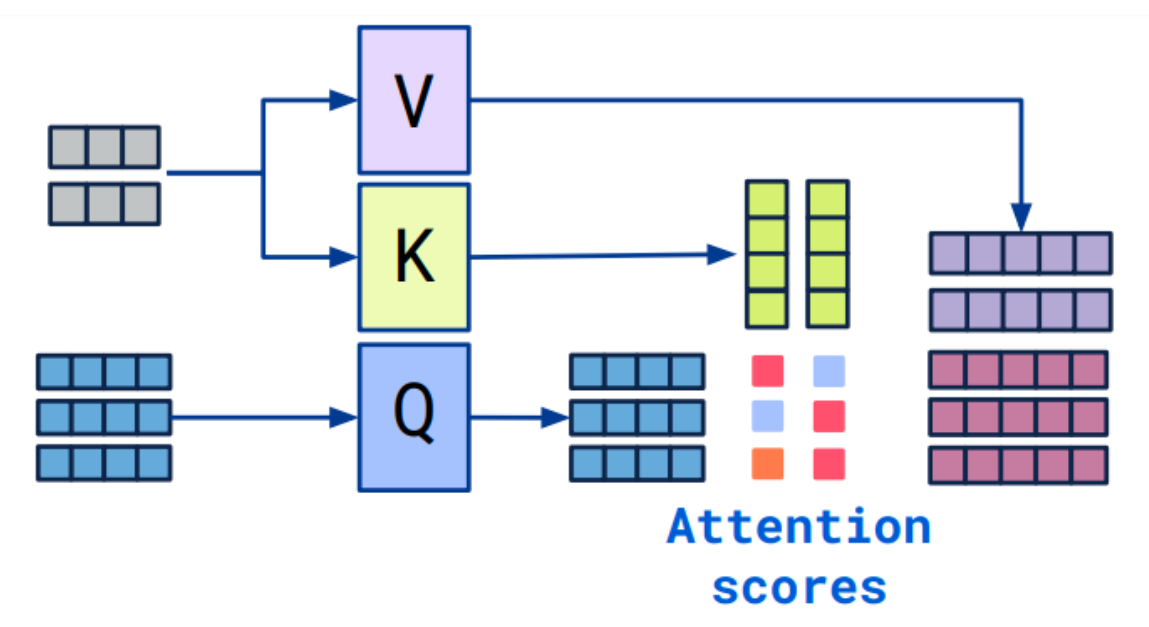
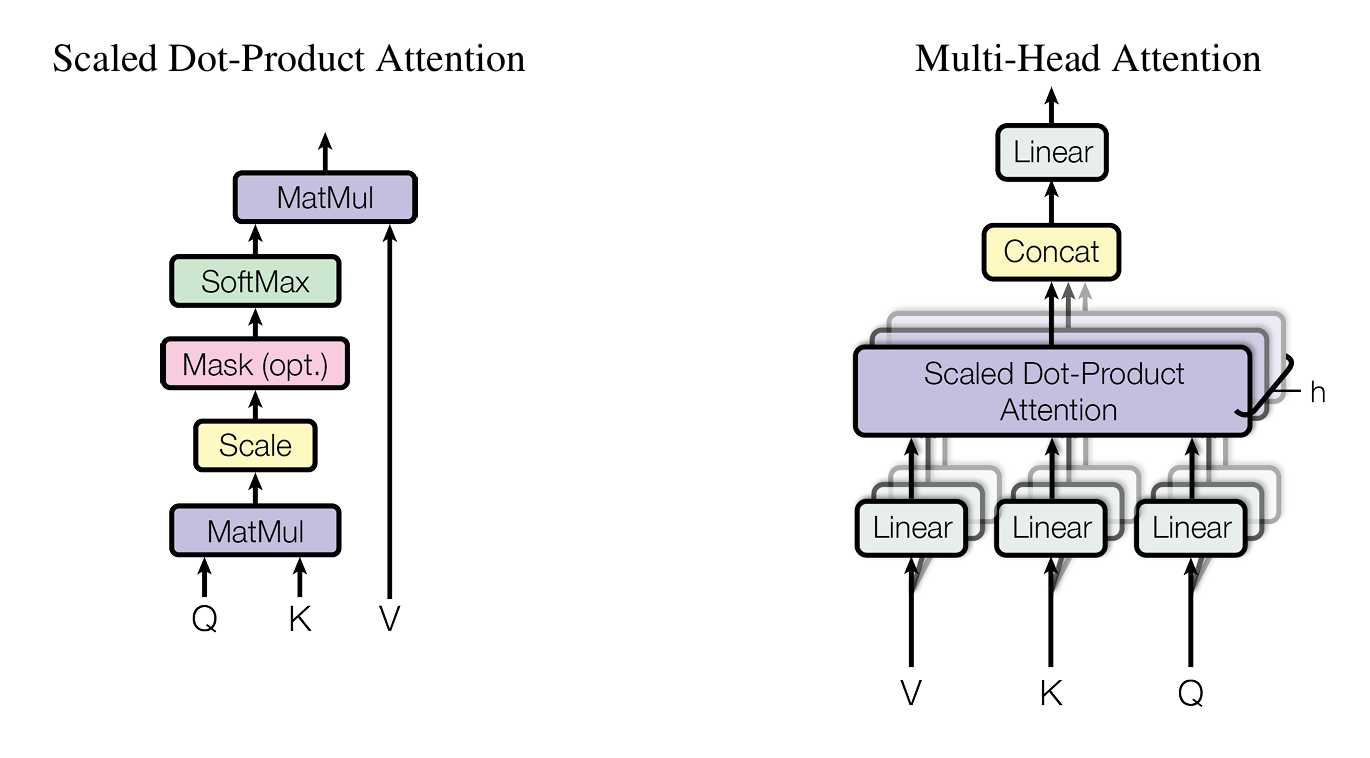
4. Multi-Head Attention(多头注意力)
Multi-Head Attention通过线性变化,将一个完整的token embedding向量投影到不同逻辑子空间中,以在多个子空间产生更加细腻、全面的关注,模型会关注不同方面的信息,也使得Transformer能够更好的捕捉每个单词之间的多重关系和细微差别。
若需获取d维特征,采用多头注意力机制,将注意力模块分为h个头并行计算。每个注意力头独立处理一部分Query、Key和Value参数,最终将各头的结果综合得到最终的注意力评分。
Multi-Head Attention的Attention可以时Self-Attention,也可以是经典Attention
多头注意力机制的公式如下,QKV在每个头的计算中经过各自不同的权重矩阵进行投影,这里WQ、WK、WV在训练过程是随机初始化的,而推理过程中三个矩阵是固定的。
Q_i=QW_i^Q,K_i=KW_i^K,V_i=VW_i^V, i =1,...,h\\ head_i=Attention(Q_i,K_i,V_i), i=1,...,h\\ MultiHead(Q,K,V)=Concat(head_1,...,head_h)W^O
V、K、Q在独立并行运算时维度降为d/h,因此无论头数如何,参数量保持不变。需要指出,即便head为1,多头注意力与标准缩放点积注意力仍有区别;它在输入输出阶段均进行线性变换,且输出端额外应用了W^O进行变换,这是因为简单拆分计算注意力再合并的方法效果不佳。
5. Masked Attention
前面提到的scale-dot attention、multi-head attention等,都可以对其增加一个mask。增加mask的原因是,Transformer推理时是序列顺序输入进行预测,训练时将结果一次性给到Transformer,这里为了给网络一个mask掩膜,防止训练时泄露后面的信息给到网络,使用mask时,可以保证Transfomer的输出不会因为传入词的多少而改变。

6.注意力机制的超参数
注意力机制又三个超参数,会决定数据的维度:
- Embedding维度
- Query维度(key和Value的维度相等)
- 注意力头的数量
二、Transformer
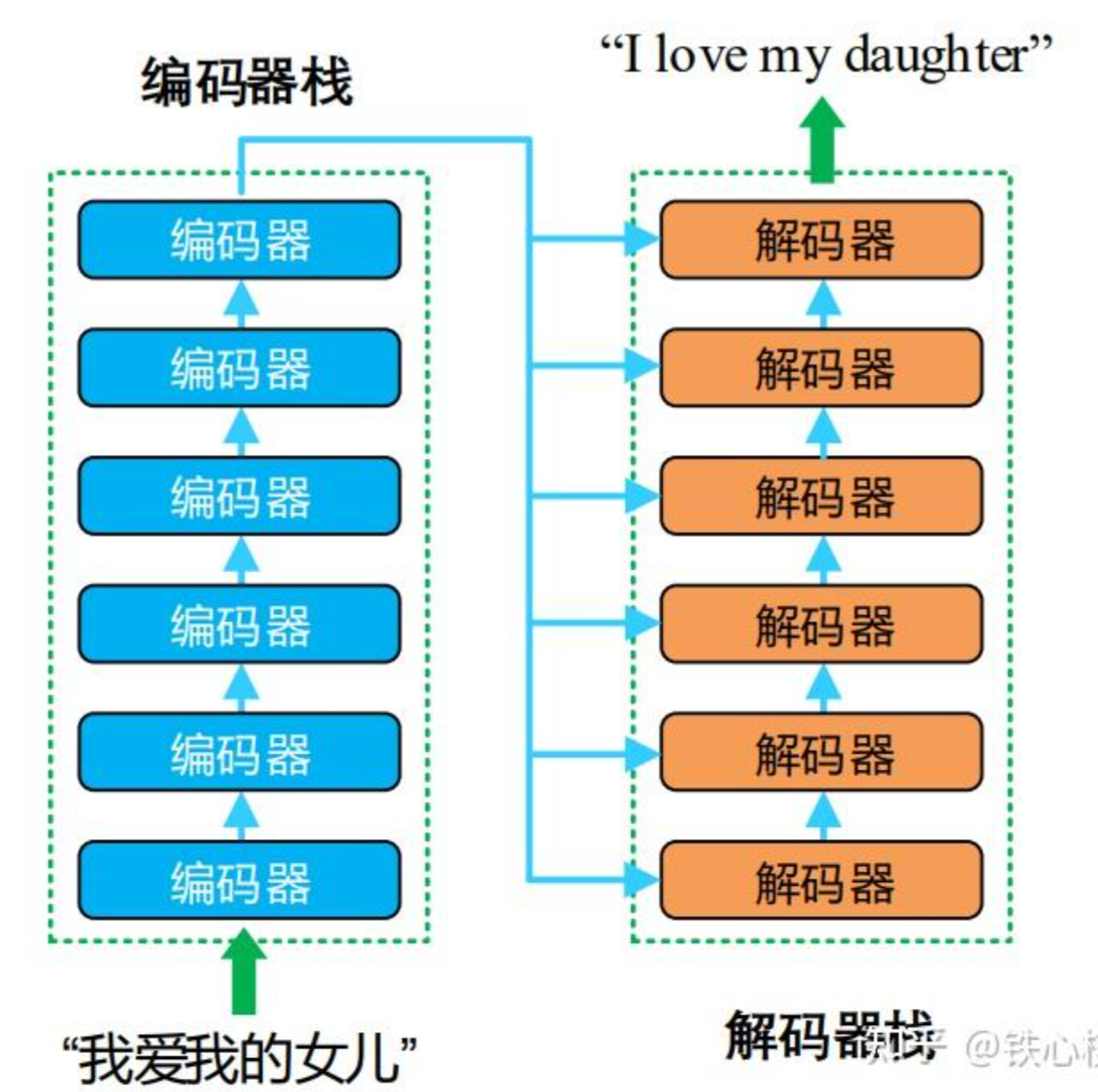
1. Encoder-Decoder结构
Transformer是一个Encoder-Decoder结构的模型,Encoder的最终输出会送给解码器:
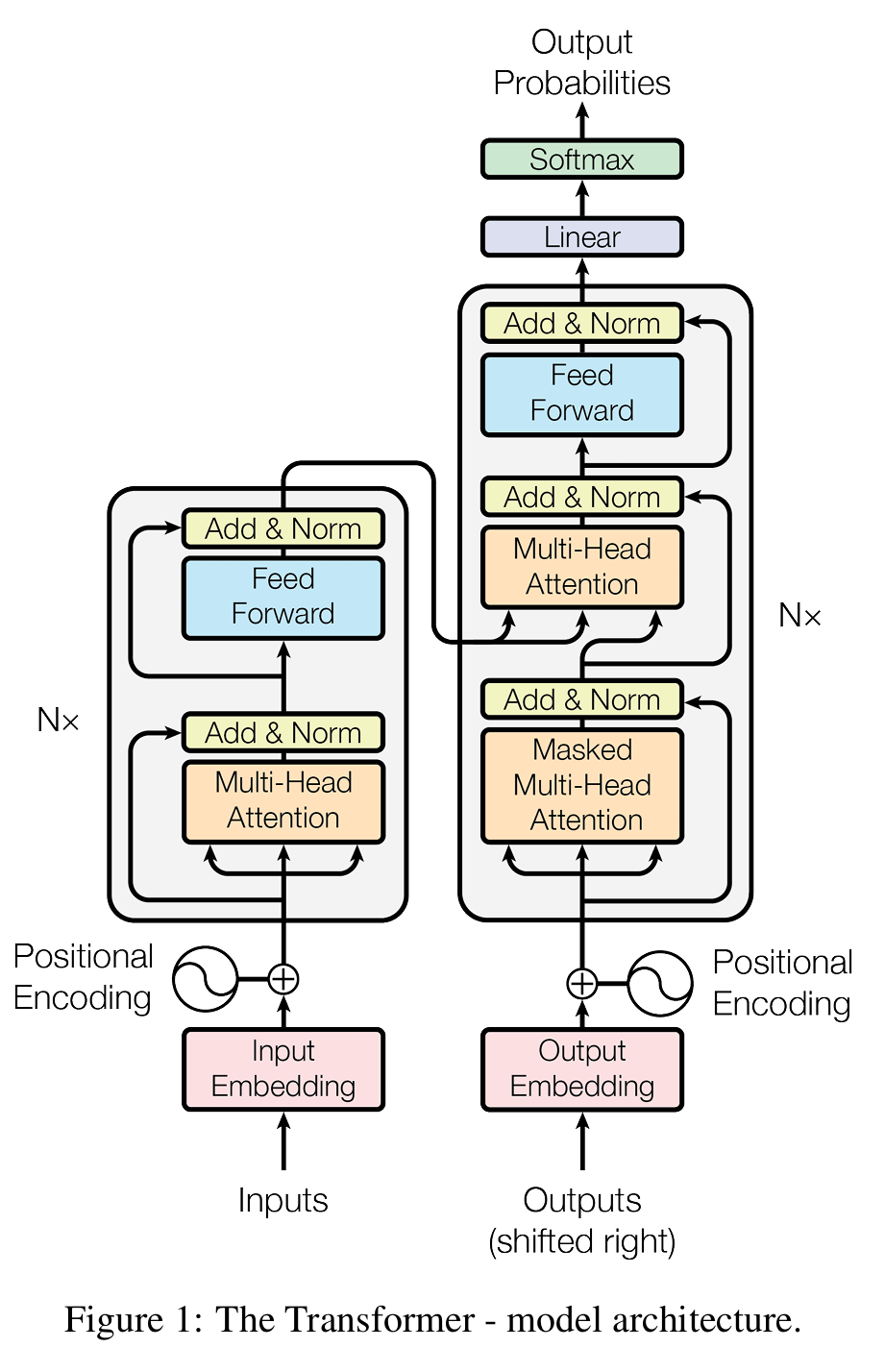
单个编码器和解码器的结构如下图描述,其中由多个多头注意力组成:
2. Position Embedding
Position Embedding的原因我们介绍过了,这里贴下paper中embedding方法的公式,这样可以让相邻位置由加大差异,同时序列每个位置的编码不同。
PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}}) \\
PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}})这里用三角函数,也是为了让网络能够相对容易的计算相对位置关系
cos(\alpha+\beta)=cos(\alpha)cos(\beta)-sin(\alpha)sin(\beta)\\ sin(\alpha+\beta)=sin(\alpha)cos(\beta)+cos(\alpha)sin(\beta)
3. Feed Forword
前馈层对前级输出做了两次线性变换,每次线性变换后都引入了非线性激活函数,目的是为了更加深入的提取特征,提取更深层的特征。
三、Vision Transformer
1. VIT的结构
ViT将输入图片分为多个patch(16×16),再将每个patch投影为固定长度的向量送入transformer,后续encoder的操作和原始transformer中的encoder操作完全相同。因为paper提出的模式是处理图片分类任务,因此在输入序列中加入一个特殊的token,该token对应的输出即为最后的类别预测。

按照上面的流程,ViT block可以分成下面几个步骤:
- patch embedding:例如输入图片大小为224×224,将图片分为固定大小的patch,patch大小为16×16,则每张图像会生成224×224/16×16=196个patch,即输入序列长度为196,每个patch维度16x16x3=768,线性投射层的维度为768xN (N=768),因此输入通过线性投射层之后的维度依然为196×768,即一共有196个token,每个token的维度是768。这里还需要加上一个特殊字符cls,因此最终的维度是197×768。到目前为止,已经通过patch embedding将一个视觉问题转化为了一个seq2seq问题
- positional encoding(standard learnable 1D position embeddings):ViT同样需要加入位置编码,位置编码可以理解为一张表,表一共有N行,N的大小和输入序列长度相同,每一行代表一个向量,向量的维度和输入序列embedding的维度相同(768)。注意位置编码的操作是sum,而不是concat。加入位置编码信息之后,维度依然是197×768
- LN/multi-head attention/LN:LN输出维度依然是197×768。多头自注意力时,先将输入映射到q,k,v,如果只有一个头,qkv的维度都是197×768,如果有12个头(768/12=64),则qkv的维度是197×64,一共有12组qkv,最后再将12组qkv的输出拼接起来,输出维度是197×768,然后在过一层LN,维度依然是197×768
- 将维度放大再缩小回去,197×768放大为197×3072,再缩小变为197×768
一个block之后维度依然和输入相同,都是197×768,因此可以堆叠多个block。最后会将特殊字符cls对应的输出作为encoder的最终输出 ,代表最终的image presentation(另一种做法是不加cls字符,对所有的tokens的输出做一个平均),如下图公式(4),后面接一个MLP进行图片分类
2. 实现细节
模型尺寸
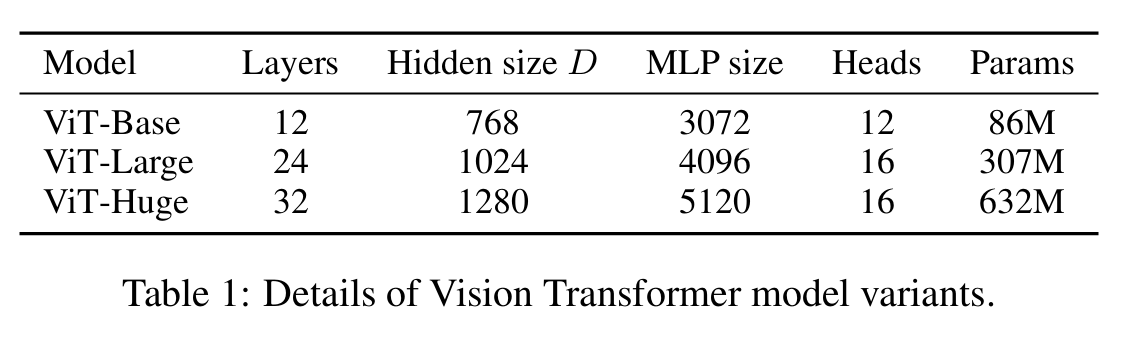
图像表示上,可以不加特殊字符cls,这里ViT为了尽可能模型结构接近原始transformer,所以采用了Bert的做法,加入特殊字符。
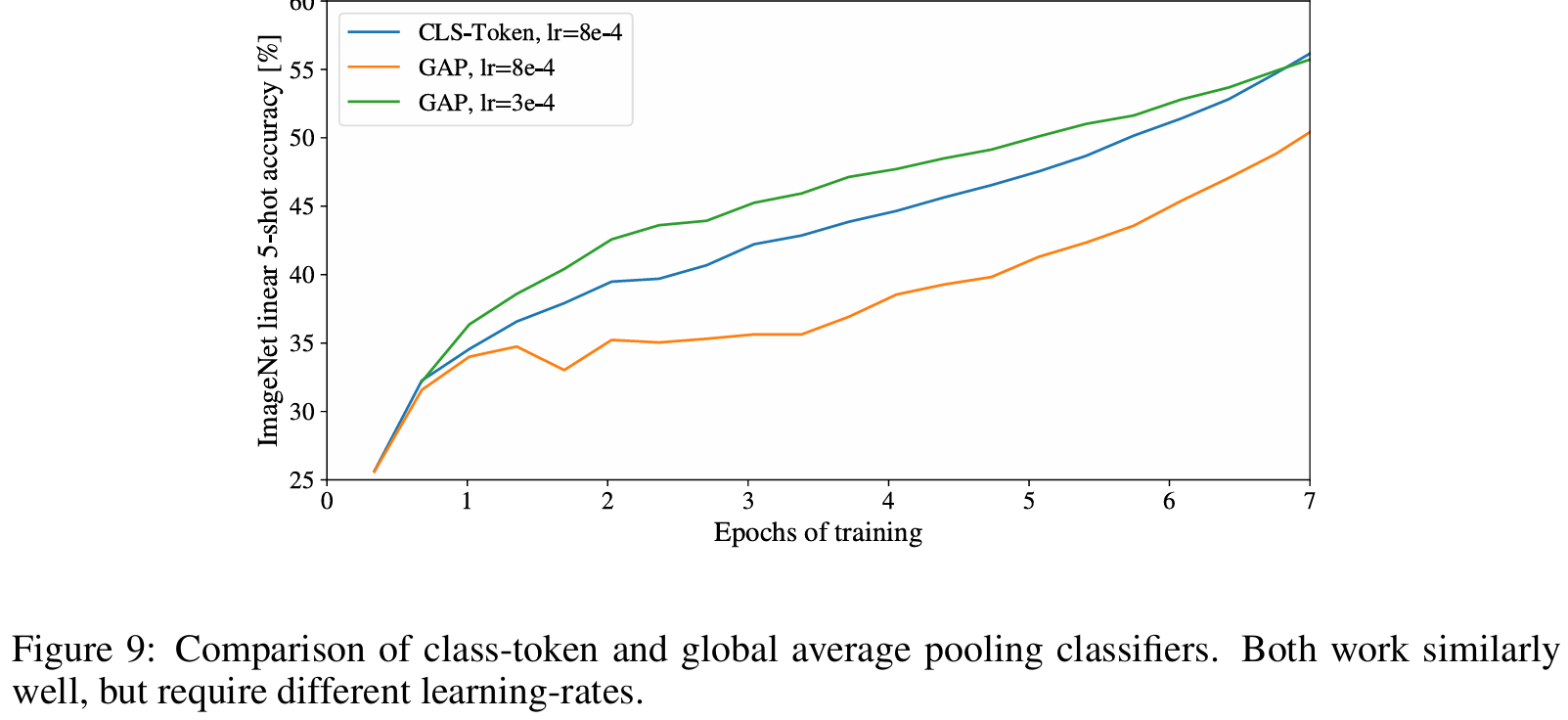
位置编码上考虑1D和2D区别不是很大,甚至没有位置编码结果也没有差很多。
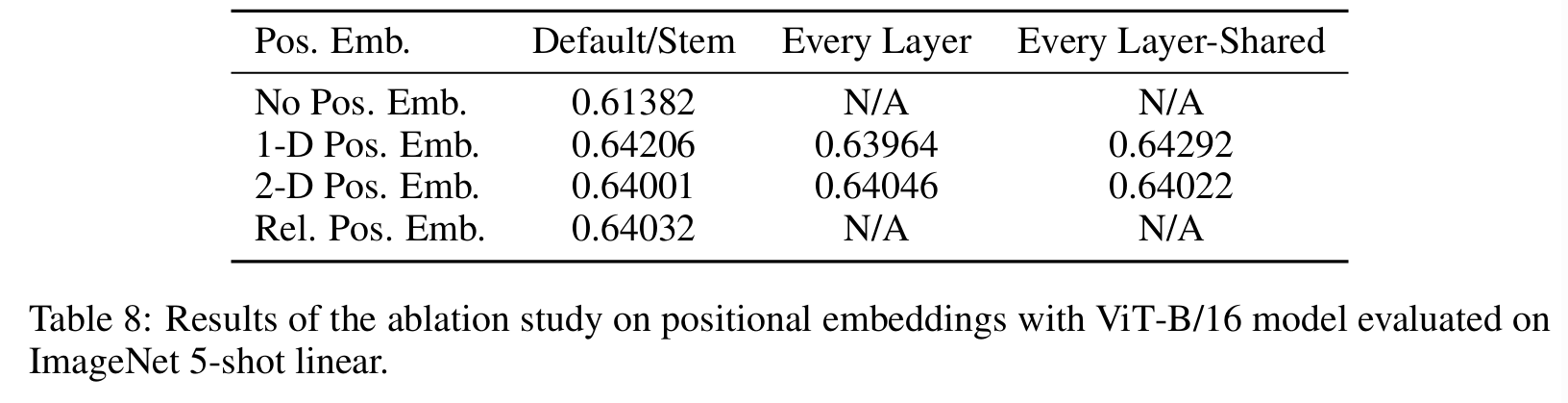
3. 实验结果
为了探究模型的可扩展性(to explore model scalability),预训练阶段使用了ImageNet-1K(1.3million)、ImageNet-21K(14million),JFT-18K(303million)三个数据集。同时参考BiT,删除预训练数据集中和下游任务测试集中重复的数据(de-duplicate the pre-training datasets w.r.t. the test sets of the downstream)
下游数据集包括:ImageNet(on the original validation labels),ImageNet (on the cleaned-up ReaL labels ),CIFAR-10/100,Oxford-IIIT Pets,Oxford Flowers-102,VTAB (19 tasks)
ImageNet ReaL参考2020-Are we done with imagenet? VTAB参考2019-A large-scale study of representation learning with the visual task adaptation benchmark,所有数据集的预处理参考BiT
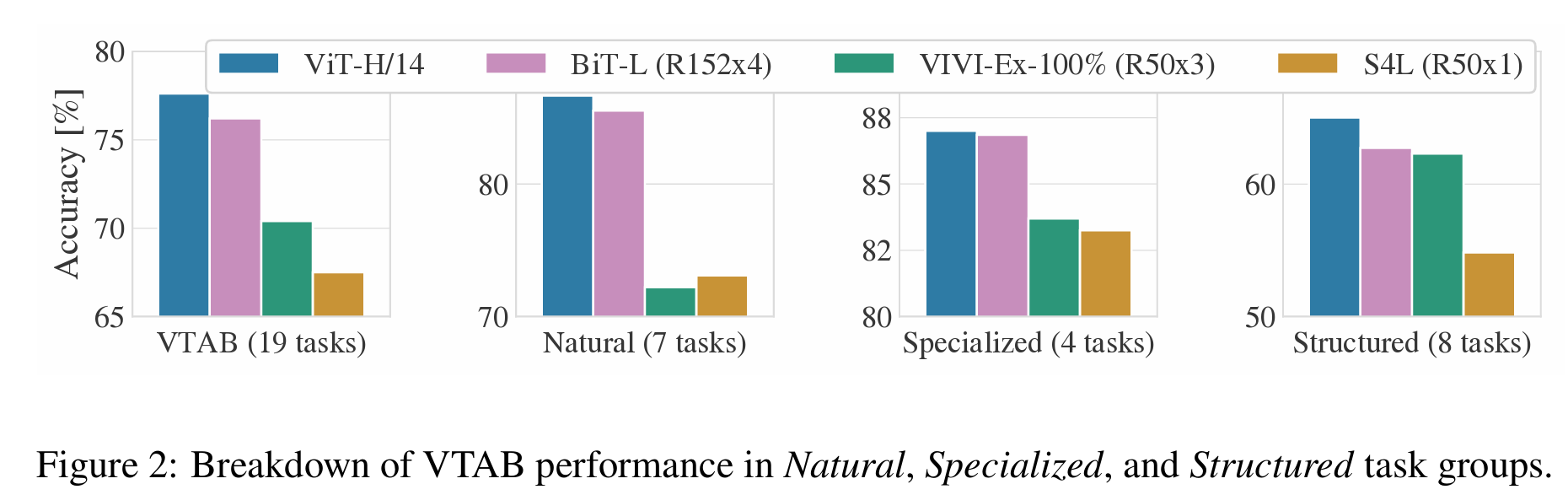
可以看到在JFT数据集上预训练的ViT模型,迁移到下游任务后,表现要好于基于ResNet的BiT和基于EfficientNet的Noisy Student,且需要更少的预训练时间
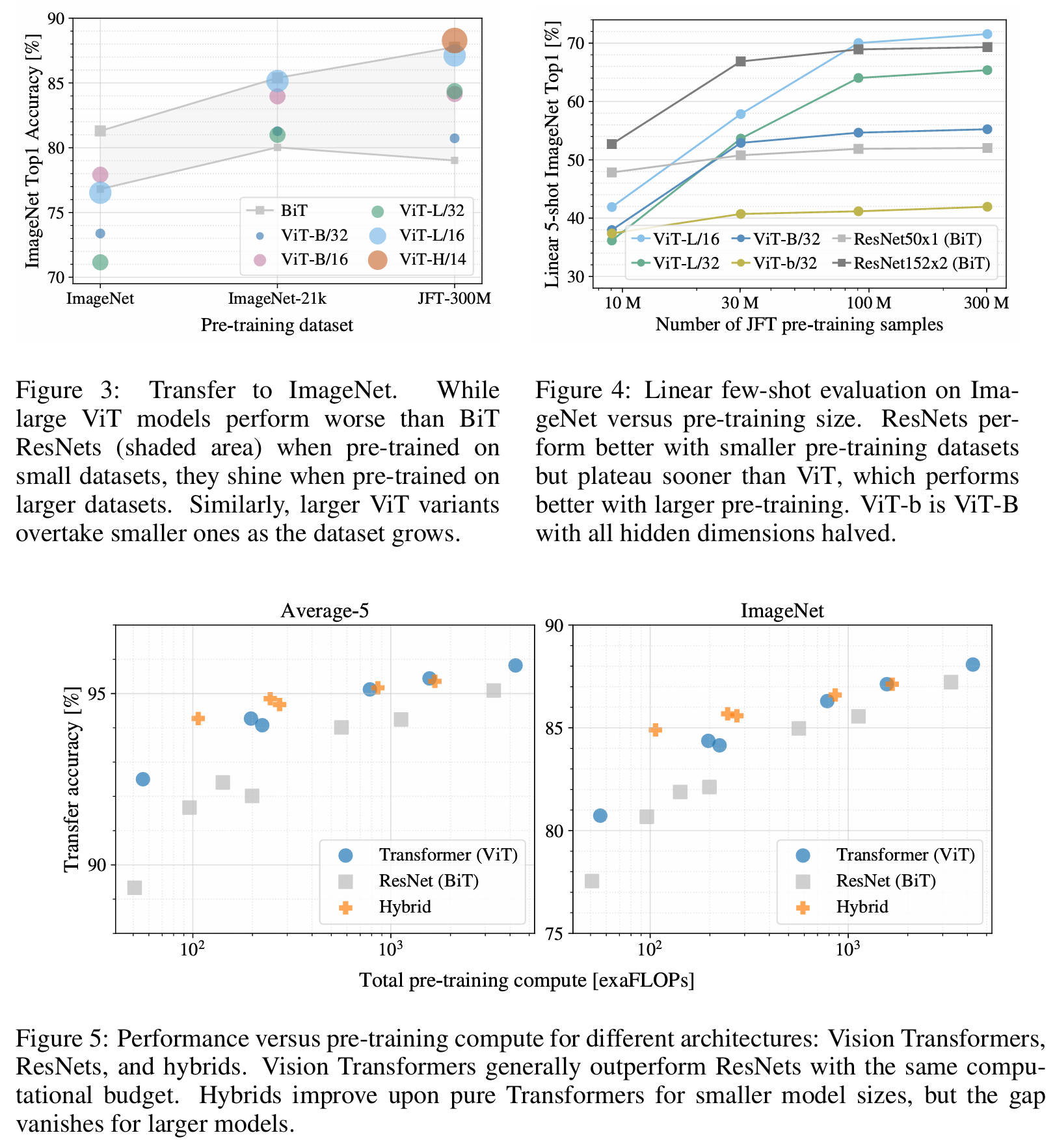
上面的实验显示,当在很大的数据集上预训练时,ViT性能超越CNN,后面探究不同大小预训练数据集对模型性能的影响(不能只看超大数据集)
4. 模型可视化
左图,ViT block第一层的前28个主成分,中间,位置编码相似性分析
右图,为了理解self-attention是如何聚合信息的(To understand how ViT uses self-attention to integrate information across the image),基于attention weight计算不同layer不同head的average attention distance
