
这篇博客主要介绍Codebook机制和CodeFormer,之前介绍了一种类似包含dictionary的算法 RestoreFormer和RestoreFormer++,他们有一些共通的机制,之前看VQ-VAE时候没有把Codebook梳理清楚,这里补补坑。
vit
图像修复笔记 RestoreFormer和RestoreFormer++
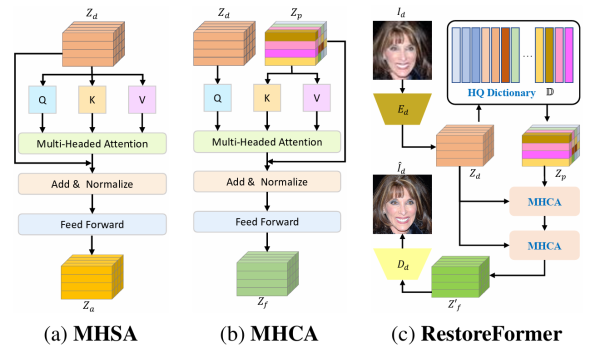
RestoreFormer收录于CVPR2022,其后续工作RestoreFormer++被收录于TPAMI2023,属于图像复原领域比较具有代表性的工作。这里需要一些transformer的前置知识,可以参见Vision Transformer.
Vision Transformer
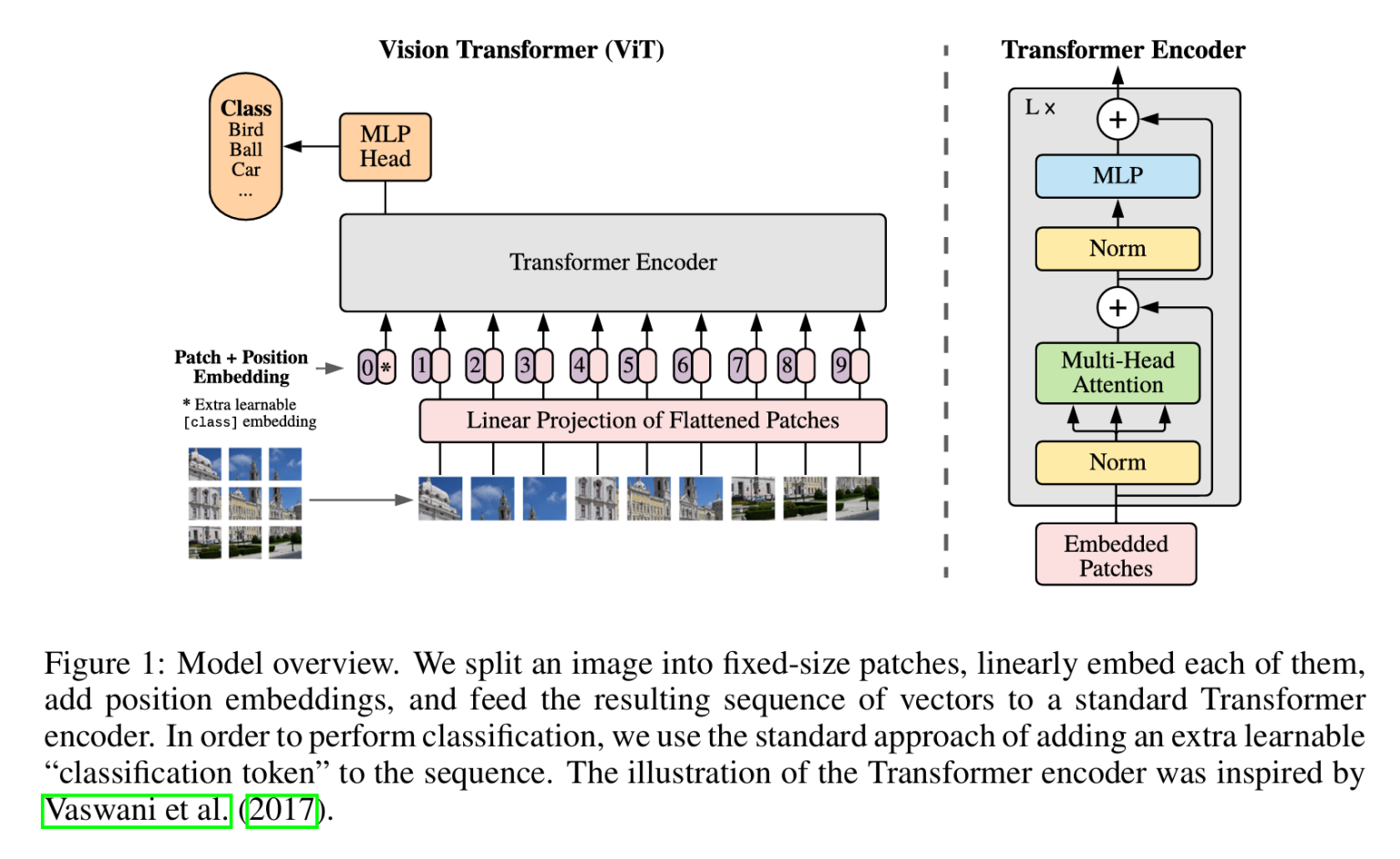
Transformer从NLP发展到视觉,开始改变视觉问题的处理方式,SwinTransformer和ViT都是典型的网络结构,典型的Transformer结构中大量使用Multi-Head Attention。ViT基于经典的Transformer模型,采用图像分块的方式将图像处理的问题转化为seq2seq的问题,这篇博客会从Attention开始,介绍到ViT。