RestoreFormer收录于CVPR2022,其后续工作RestoreFormer++被收录于TPAMI2023,属于图像复原领域比较具有代表性的工作。这里需要一些transformer的前置知识,可以参见Vision Transformer.
一、链接
RestoreFormer论文: Wang_RestoreFormer_High-Quality_Blind_Face_Restoration_From_Undegraded_Key-Value_Pairs_CVPR_2022_paper.pdf (thecvf.com)
RestoreFormer代码:wzhouxiff/RestoreFormer: [CVPR 2022] RestoreFormer: High-Quality Blind Face Restoration from Undegraded Key-Value Pairs (github.com)
RestoreFormer++论文:arxiv.org/pdf/2308.07228.pdf
RestoreFormer++代码:wzhouxiff/RestoreFormerPlusPlus: Pytorch implementation of RestoreFormer++ (github.com)
二、RestoreFormer
2.1 RestoreFormer的结构
从论文里面这张图说起,
MHSA:Multi-Head Self-Attention, MHCA: Multi-Head Cross-Attention, 这二者是基础的attention模块。如果对这个不熟悉还请移步Vision Transformer。
右图是RestoreFormer的pipeline,图像首先进入一个编码器Ed,编码器Ed提取出退化人脸图像的表征Zd,(这里下标d表示degraded),然后拿Zd取HQ Dictionary中查找和Zd最接近的表征Zp,然后Zd作为query,这两个表征一起做交叉注意力。经过两次交叉注意力之后输出特征,然后过一个decoder得到复原之后的图像。
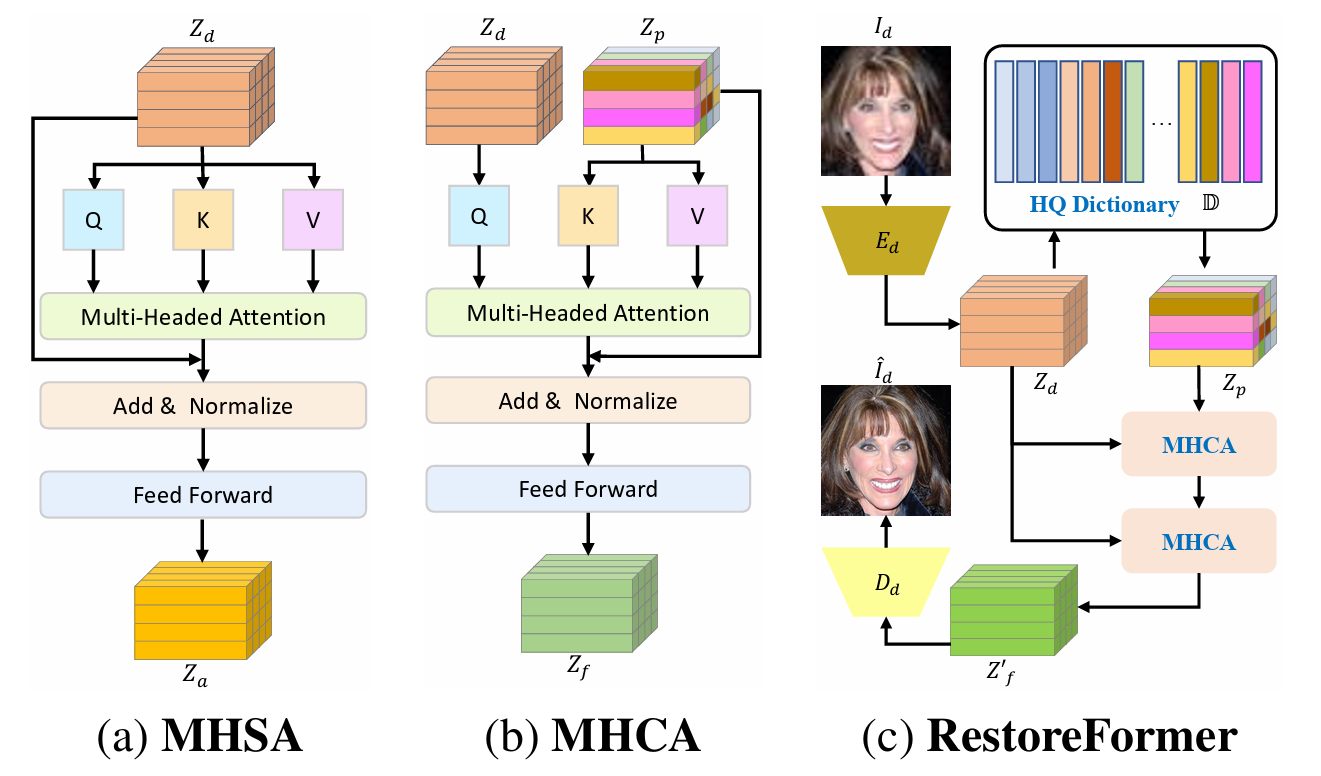
2.2 RestoreFormer的设计
HQ Dictionary主要是参考了向量量化的思想,论文用一个高质量的人脸生成网络来学习HQ Dictionary。
论文说大多数ViT based 方法只考虑图像内部的纹理,只能做MHSA(自己attention自己),论文提出的RestoreFormer通过引入HQ Dictionary,就可以用Dictonary中的信息来CrossAttention,这样有两个源头,就会更好。
2.3 HQ Dictionary
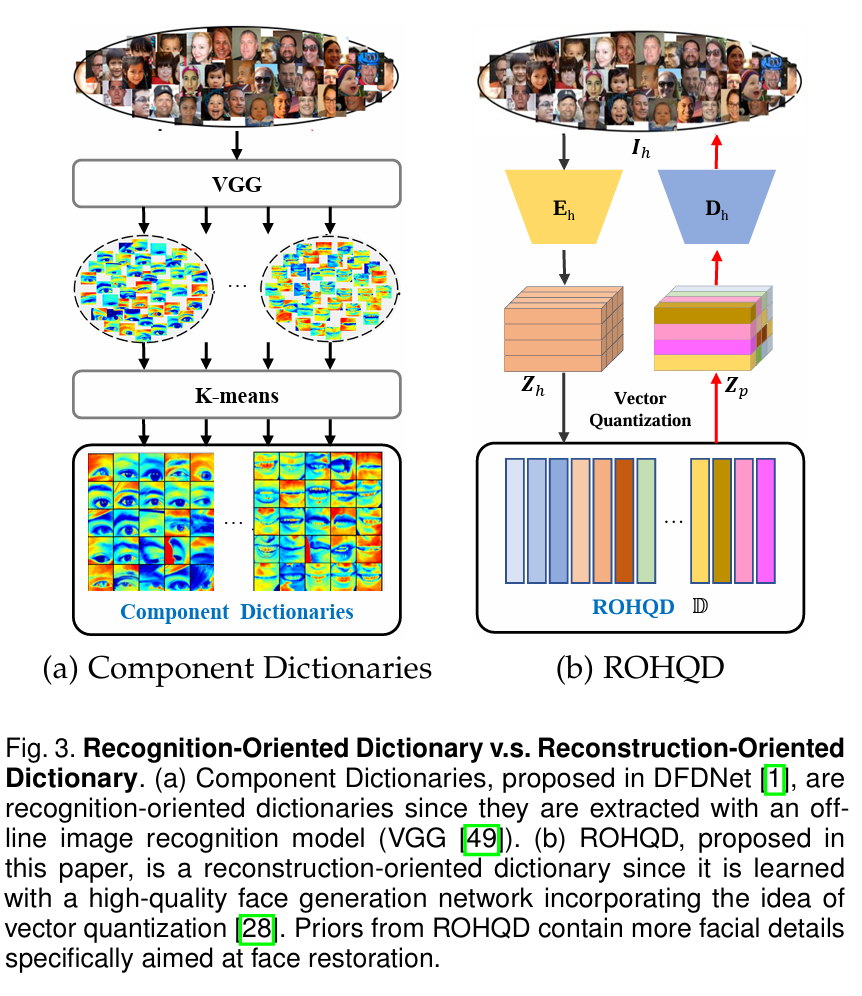
类似Dictionary的想法在DFDNet中就提出过,通过VGG特征+Kmeans,离线构建一个字典供后面使用,RestoreFormer中的HQ Dictionary是使用高清人脸做自编码器的中间特征,做特征向量量化来构建的。
dm是字典内容,对于位置(i,j),那么选自字典内容dm,会要求更接近Zh
(我们这里要留意下面途中Zh额Zp的颜色表达,以方便我们理解)
\textbf{Z}_p^{(i,j)}=argmin_{d_m}||\textbf{Z}_h^{(i,j)}-d_m||_2^2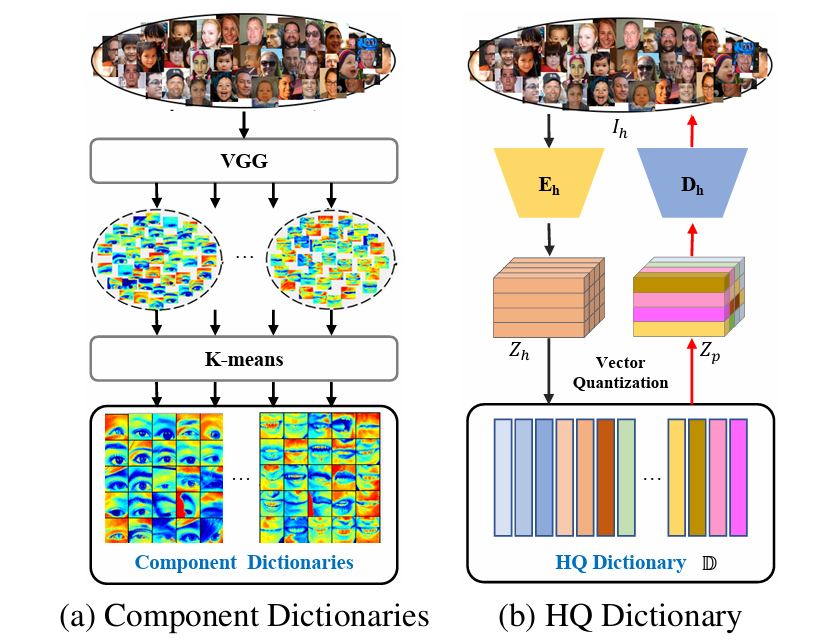
HQ Dictionary,训练过程使用向量量化(VQ),将Zp移动到Zh,论文中展示的loss函数为好几个loss的组合,下面这两个loss用来约束特征,会使得Zp接近Zh,由于使用的是high quality数据进行训练,那么Zp中自然也就包含了练好的人脸恢复信息。
\mathcal{L}'_d=||sg[\textbf{Z}_h]-\textbf{Z}_p||_2^2 \\
\mathcal{L}'_c=||\textbf{Z}_h-sg[\textbf{Z}_p]||_2^2 \\
sg[]\ is\ stop\ gradient\ operator除了上面这两个loss,还有三个Loss用来约束重建图像相似新的,一个是perceptual loss,一个是adversarial loss,一个是L1 loss,最后将这几个loss按照一定权重组合起来。
2.4 实验细节和分析
HQ Dictionary寻来你数据是FFHQ数据集,包含70k 512×512的图像。另外,RestoreFormer也在该数据集上构建了退化数据,主要做的是blur+noise+jpeg_quality的退化,另外还有一些更具体的参数设置,可以参考论文原文
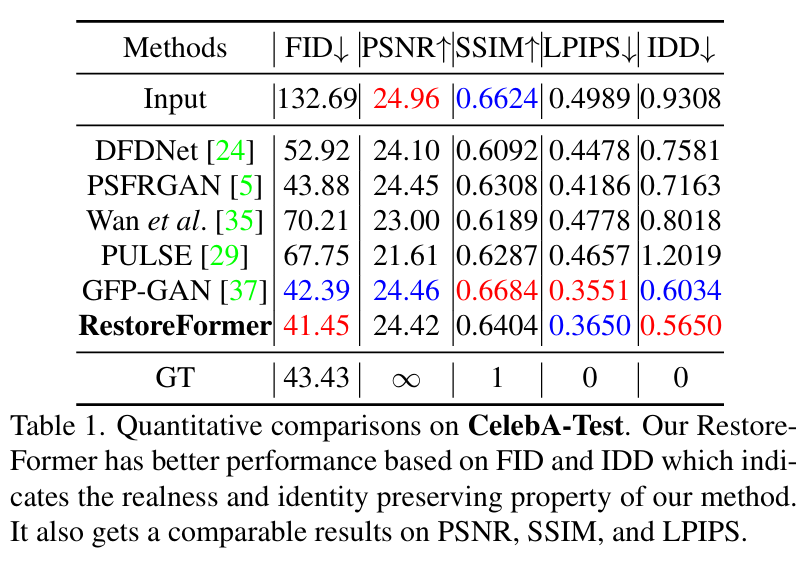
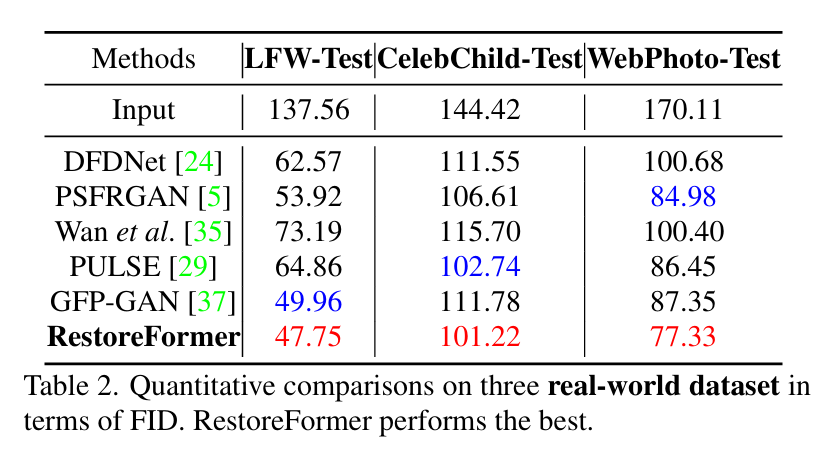
测试集和效果对比也请参见论文,这里只贴下结果表格,都达到SOTA

三、RestoreFormer++
RestoreFormer++(TPAMI2023)是RestoreFormer更进一步的工作,
下面是各个方法的演示效果:
从演示图像中可以看到Restormer++有一些去雾和去模糊的效果,论文说RestoreFormer++有多尺度机制,包含一个EDM(extending degrading model)来产生更多实际退化图像,会使得RestoreFormer++有更好的去雾效果。

3.1 结构
我们还是从论文中给出的RestoreFormer++的结构来说起,这里同样存在一个Encoder和一个Decoder和一个Fusion Block。
论文名称( Towards Real-World Blind Face Restoration from Undegraded Key-Value Pairs)里面强调了 Undergraded Key-Value Pairs。这里和前作restoreformer一样,key为degrade featre Zd,value 为 high-quality feature Zp。
RestoreFormer++ 首先把图像送入Encoder,然后Encoder中的中间特征层和ROHQD Dictionary中与Zd距离最近的特征一起被送入Fusion Block(其中就隐含了多尺度的信息)。 Fusion block就是很多MHCA,Fusion Block出来的特征再送入Decoder中,(这样看起来就有些像Transformer了),最终输出复原的图像。

3.2 ROHQD
(Reconsturction-Oriented High-Quality Dictionary)这里论文使用的图和RestoreFormer中使用的Dictionary几乎一样,不过多赘述。
3.3 EDM(Extending Degrading Model)
前作RestoreFormer中使用的退化是 blur、noise、jpeg,在RestoreFormer++中进一步拓展成更复杂的退化流程EDM,EDM会做两个scale的退化,退化图像一开始做一个shift平移,后面两路各自包含了haze、blur、noise、jpg等,然后两路退化通过一个mask融合在一起。

3.4 数据和实验
详细的数据处理和实验结果参见原论文,这里只介绍下面的消融实验,消融实验上面一排是结果,exp2和exp3是在对比数据源,exp4-exp7是对比方法和S层数。
下面一排是attention map, 其标题sxhy,s表示scale,h表示attention head,我们看左眼部分实在s16尺度上重点关注的,而细尺度更加关注边缘细节。

谢谢,希望能有帮助