开始之前需要一些前置知识,关于SAM请移步:SAM论文笔记, 关于ViT基础请移步:Vision Transformer,关于MAE请移步知乎:MAE(Masked Autoencoders) – 知乎 (zhihu.com)。
SAM的解码器已经足够快,但是图像编码器用的ViT还是很大,于是很多工作就在SAM基础上改进性能,进行轻量化,其中有一些比较出色的工作 比如 MobileSAM 、 FastSAM 和 EfficientSAM 等,已经将SAM推到了相当轻量。这篇博客主要是EfficientSAM的论文笔记。
论文主页:https://yformer.github.io/efficient-sam/
开源代码:https://github.com/yformer/EfficientSAM
一、简介
首先,我们看下EfficientSAM的整体性能,Pretrained Image Encoder参数大小约为5M,参数量和推理速度都比SAM快20倍,AP比SAM低2。
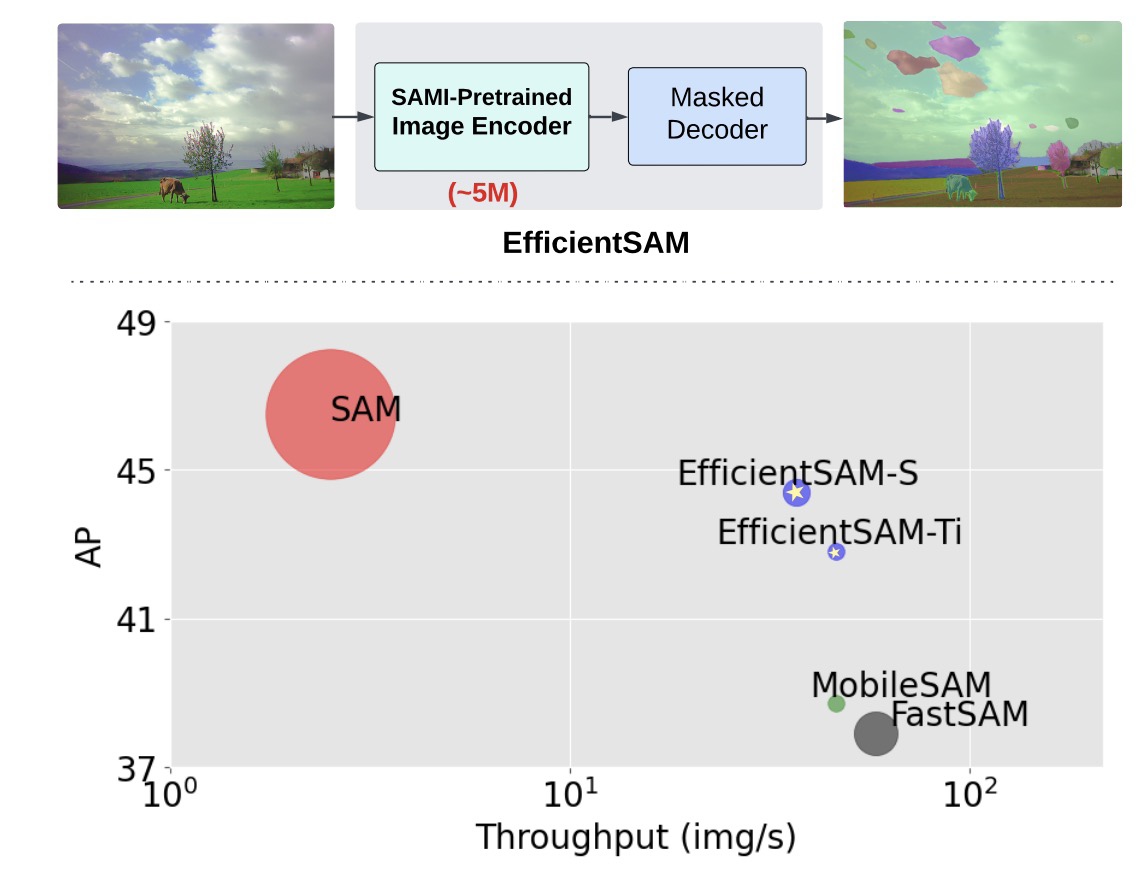
二、结构
EfficientSAM整个框架分为两个阶段,第一个阶段SAMI 在ImageNet上pretraining,第二阶段在SA-1B数据上对SAM finetune。
在SAMI pretraining阶段,也借助MAE方式进行训练,masked auto encoder从SAM Image encoder学习特征。
pretraining阶段的cross-attention decoder仅重建屏蔽交集,key和value来自于未屏蔽和屏蔽的特征。解码器和编码器的输出特征被合并并重新排序到他们在输入图像标记中的原始位置。
linear projection 主要讲SAM图像编码起的特征和MAE的特征对齐,从而解决任何尺寸不匹配的问题。
在pretraining完成后,微调EfficientSAM的时候就不需要pretraining时候的cross-attention decoder了,直接把与训练时候的light-weight encoder拿来用。
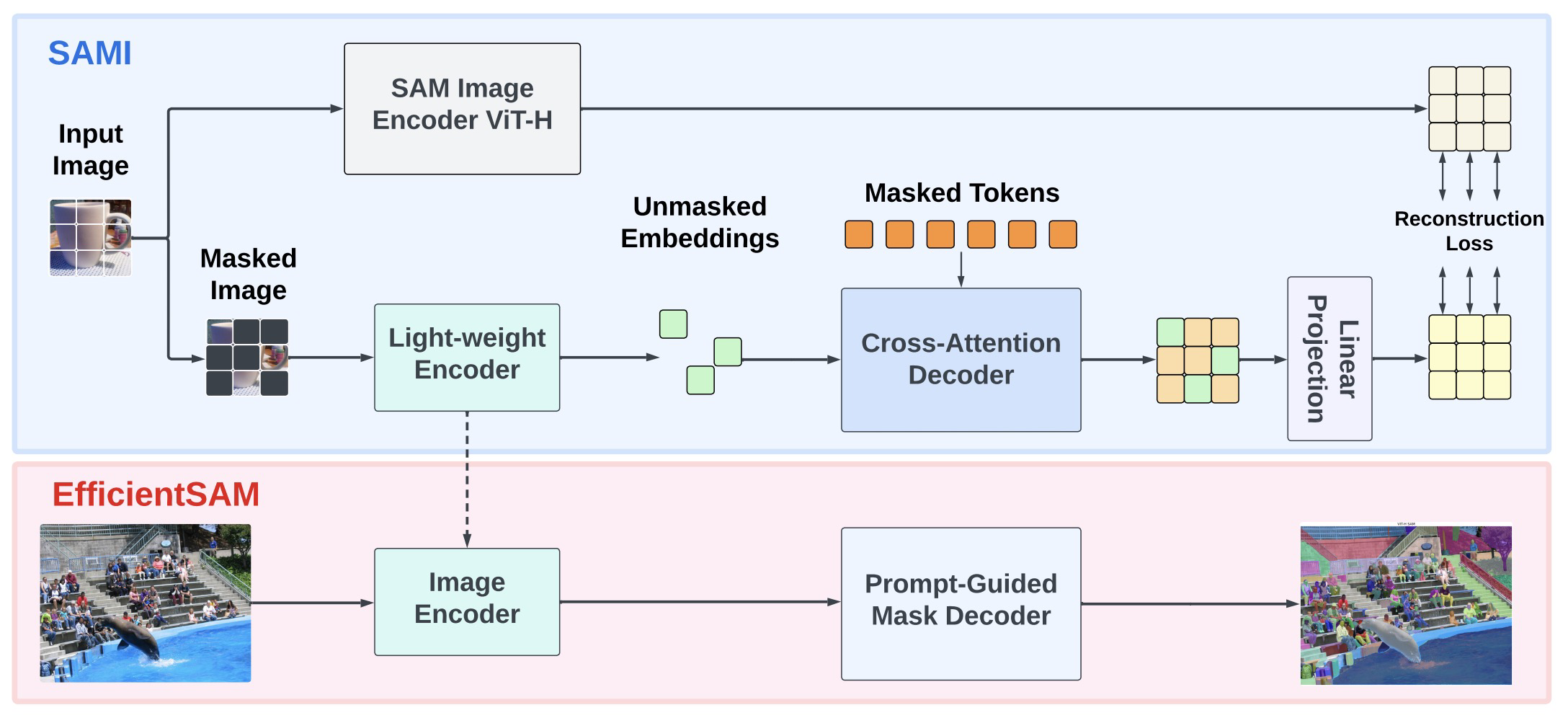
对于Segment Anything任务,SAMI与训练的轻量级编码起(入ViT-Tiny和ViT-Small)与SAM的默认Masked Decoder相结合,一创建EfficientSAM模型。
三、实验
参见论文,这里就不贴图了。