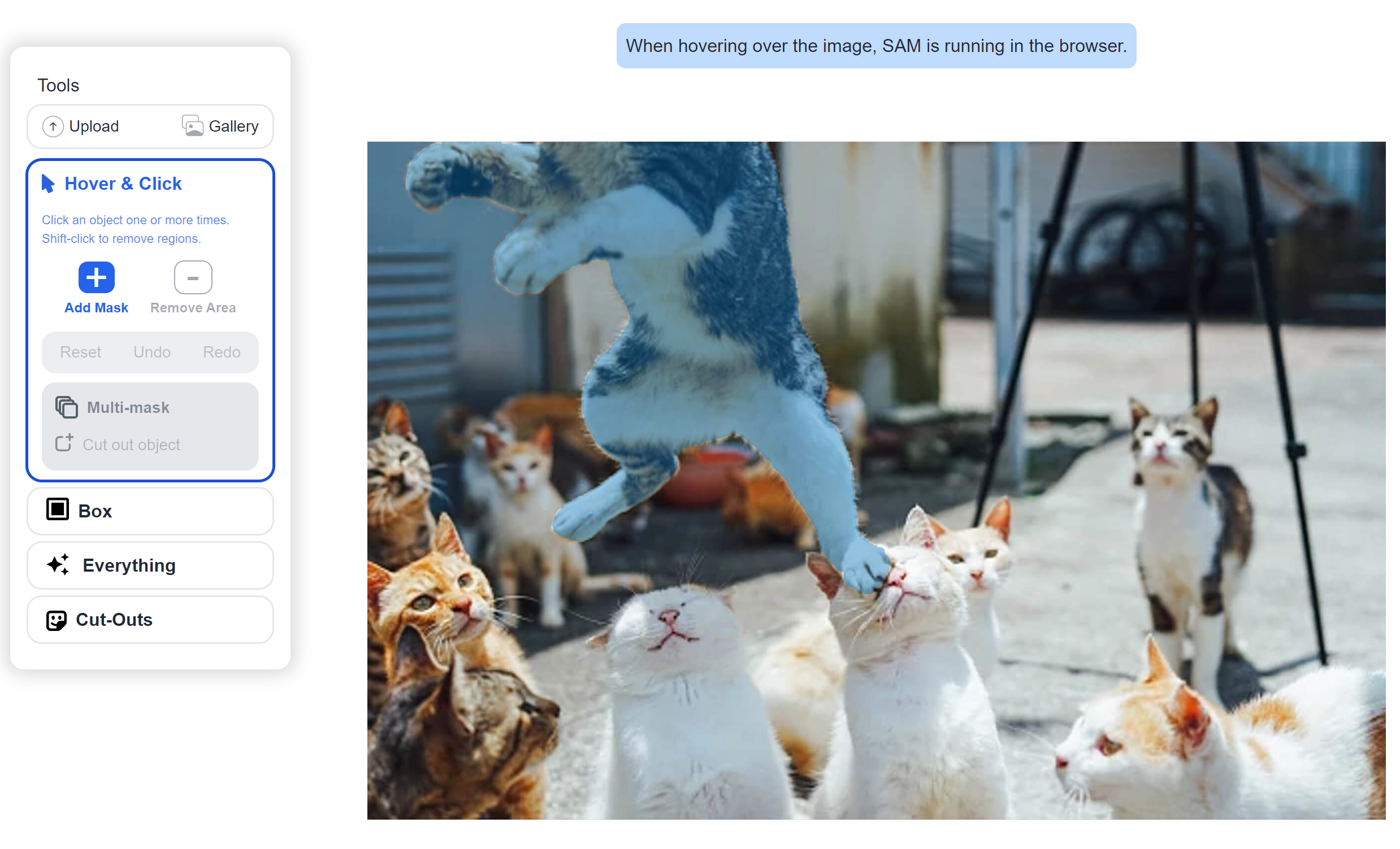
SAM,segment anything是由meta开源的分割模型,它可以用框选、提示、文本prompt范式对图像进行分割,而无需额外训练,这一类方法构筑的网络已经成为CV任务的基础模型。
论文地址:[2304.02643] Segment Anything (arxiv.org)
演示demo:Segment Anything | Meta AI (segment-anything.com)
开源代码:GitHub – facebookresearch/segment-anything: The repository provides code for running inference with the SegmentAnything Model (SAM), links for downloading the trained model checkpoints, and example notebooks that show how to use the model.
参考解读:https://www.bilibili.com/video/BV1Cv4y1E7ho
一、介绍
Segment Anything:一个新的任务、模型和数据。
SAM模型和传统模型的功能区别:
- 交互方面,SAM可以使用点击、框选、文字等prompt来制定图像中要分割的内容,这也意味着,用于自然语言处理和CV之间又建立起一座桥梁。
- SA具有zero shot的特性,对于视频中的物体,SAM也能准确识别、标记,并用ID为这些物品进行记录和分类。
- 数据构建方式不同,论文介绍了它们收集数据的循环,他们通过这种方式获取了11M张图片,1billion数据的掩膜(mask)数据。差不多每张图片有100张mask。
从demo中看,SAM具有毫秒级别的响应


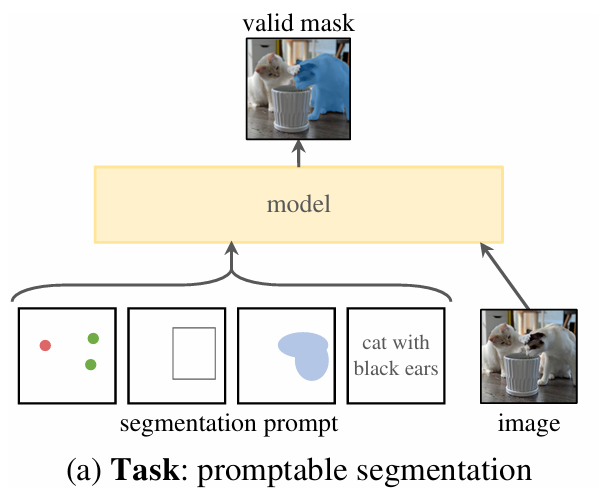
我们从论文开头的这三幅图就介绍了SA的任务描述Task、model和Data:

二、任务
论文借鉴了NLP领域里的大模型和prompt设计,在这里prompt就不再是一串文字了,而可以是一些点、矩形框、掩膜或者文字等。所有类型的prompt也将被编码和embedding一同送入模型。
pre-train时,将不同prompt和对应的groudtruth mask进行监督学习。
三、模型
模型包含图像编码器、prompt编码器和mask解码器,可以用于各种分割任务。
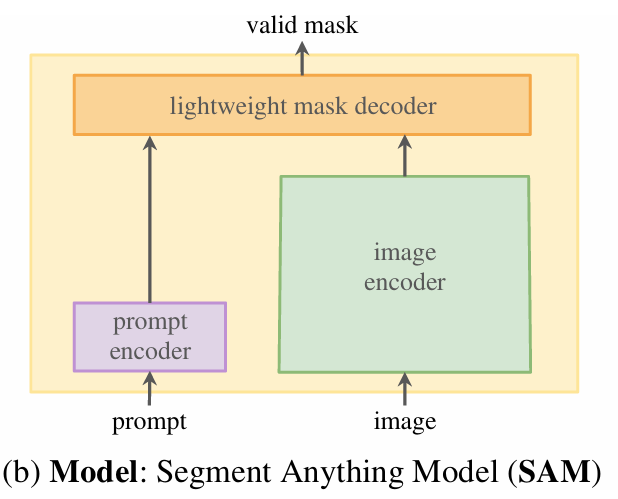
- image encoder借鉴了现有的模型,使用MAE的方法训练了一个Vision Transformer模型。MAE本身时自监督的, image encoder本身比较耗时,但是它在prompt切换时只运行一次。
- prompt encoder分为两类,一类是稀疏的(points、boxes、text),另一类是稠密的(mask)。对于文本来说,使用CLIP来提取特征,对于points和boxes使用位置编码(positional encoding),输入的是mask,使用卷积和element-wise的操作来进行编码。
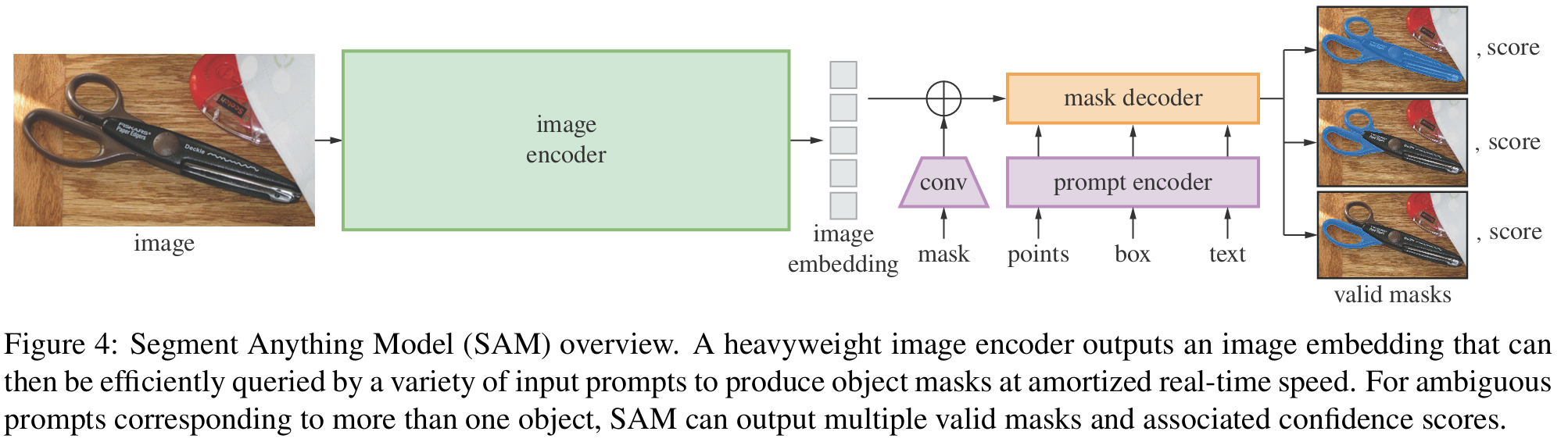
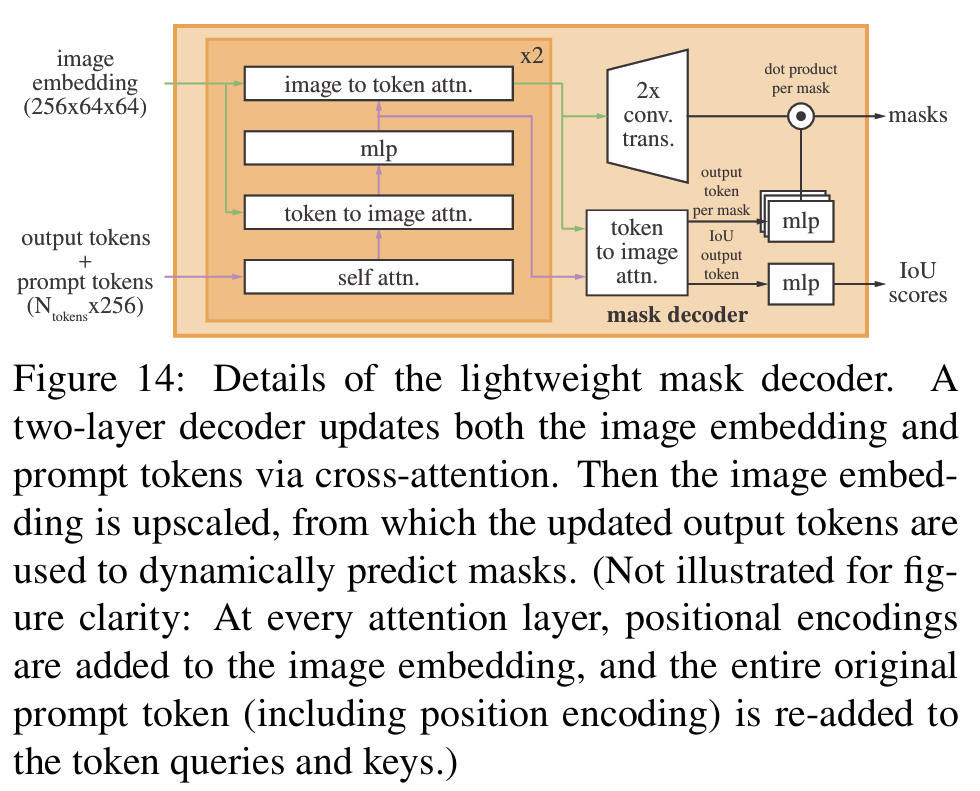
decoder主要是将encoder的信息做一些融合输出,附录中有decoder的详细介绍,这里是一个两层decoder的结构。
这里用了一个双向的cross attention(image2prompt和prompt2image),cross attention中q是一种模态的输入,k和v是另一种模态的输入,双向是指prompt2image时和image2prompt时 q和kv对应会反过来。
这里在处理模糊输入时,这里会输出三个备选的mask。这里反向传播时只会把loss最小的mask做loss反传。这里为了对不同mask进行排序,这里会输出一个IoU来对不同mask算一个confidence score。
四、数据
对于分割大模型,预先标注好的数据很少,于是论文设计了一个数据引擎,产生了一个大的分割数据集 SA-1B。
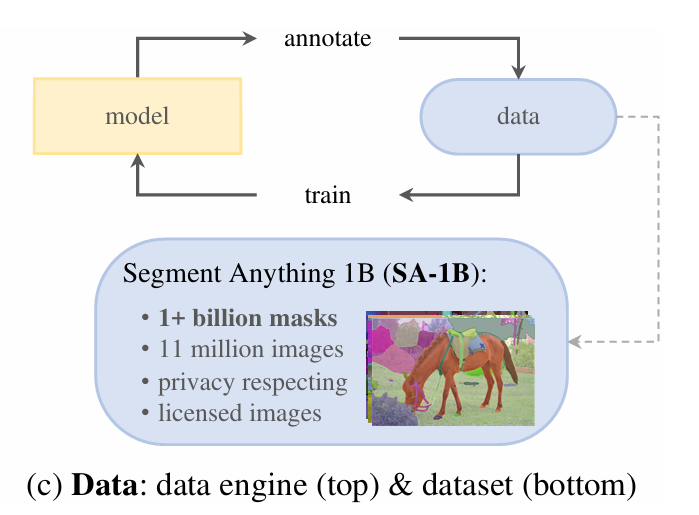
论文介绍的数据获取方式,通过模型不断产生数据,再用产生的数据不断优化模型性能,数据获取分为三个阶段:
- 第一阶段,助手阶段,模型在公开有标注的数据集上pretrain,模型就可以作为标注助手。然后,用模型对没有标注的数据进行预标注产生mask,然后人来手工refine标注结果,这样能产生很多新数据。再把标注refine的数据再喂回模型,这样来回6次往返迭代,这样SAM模型就具有更好的能力,在这个过程中,模型的大小逐渐增加。
- 第二阶段,半自动阶段,增加mask的多样性,用第一阶段训练的模型,设计一个bbox detector,来检测自动标注的框是否可信,最后只保留可信的框,把这些可信的框送给人工,人再手工在可信框外手动增加一些框,这样经过5次迭代后,数据狂冲到5.9M
- 第三阶段,全自动阶段,用模型自动标注数据,根据模型输出的IoU、confidence和stable,人工筛选掉比较差的结果。最终通过NSM筛出最终的mask加入到数据集中。
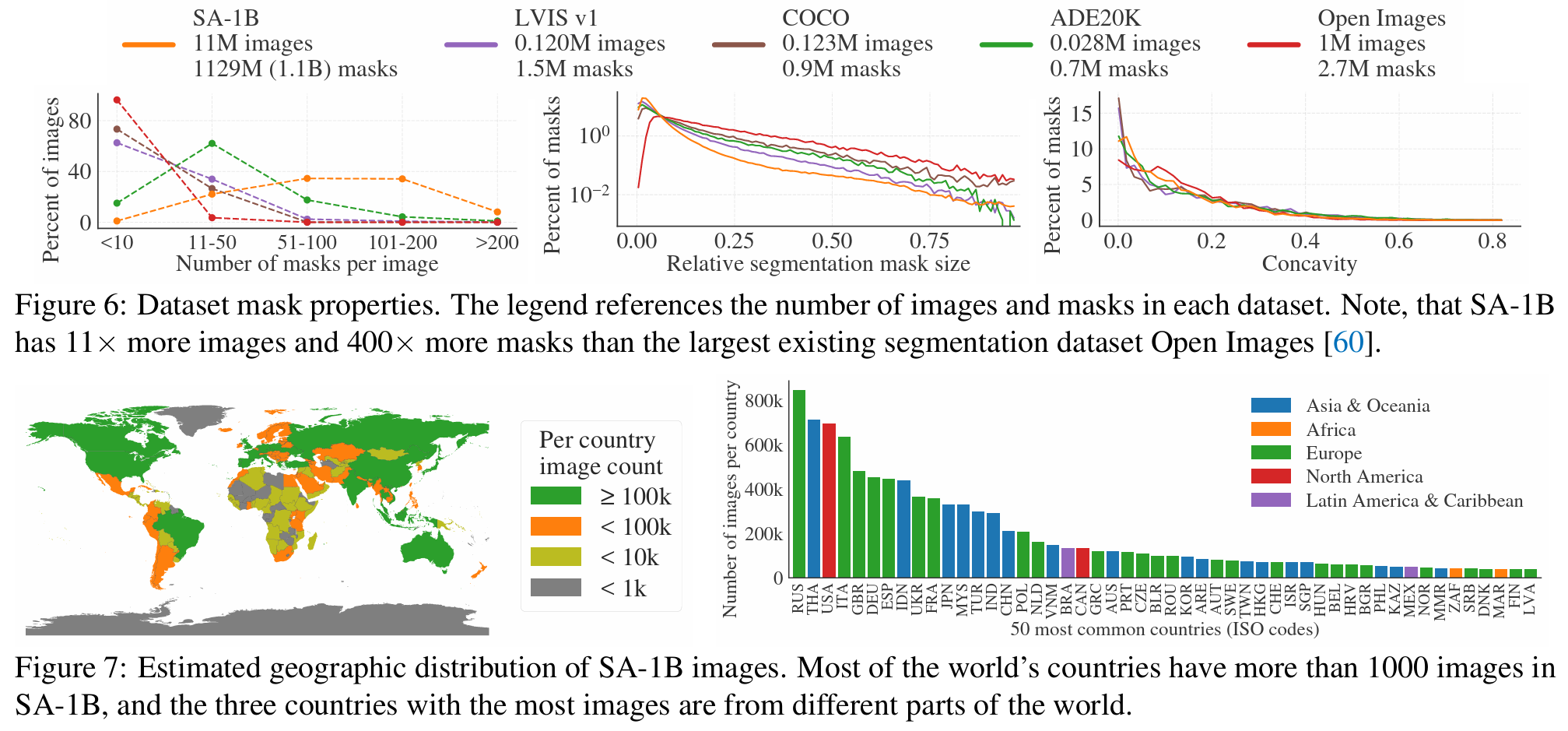
论文对数据集的特点和分布做了统计
- 高分辨率,平均有3k*5k
- Mask 99.1%是机器生成的,实验说只用机器生成和添加手工标注数据的效果相当,所以SA-1B最后只包含机器生成的mask
- Mask质量,与专业标注人员精细标注对比,IOU 90%以上,比其它手工标注的数据集质量更好(其它85%-91%)

不同数据集的特性对比:
- mask数量
- mask尺寸、SA-B1小框比例较高
- concavity,和外接矩形算overlap比例,体现mask形状的多样性
图7也分析了Responsible AI(数据集是否由偏见),说明数据集相对比较均衡
五、Zero-Shot实验
1. 分割任务
SAM算法和RITM算法的比较(输入点的情况下),在23个数据集的结果比较。在只有一个输入点的情况下,SAM显著优于其它算法

2. 边界检测

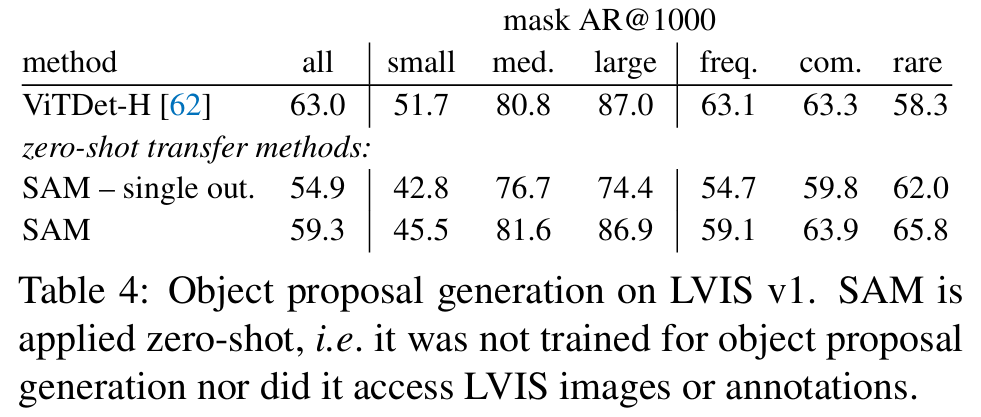
3. Proposals提取(目标检测)
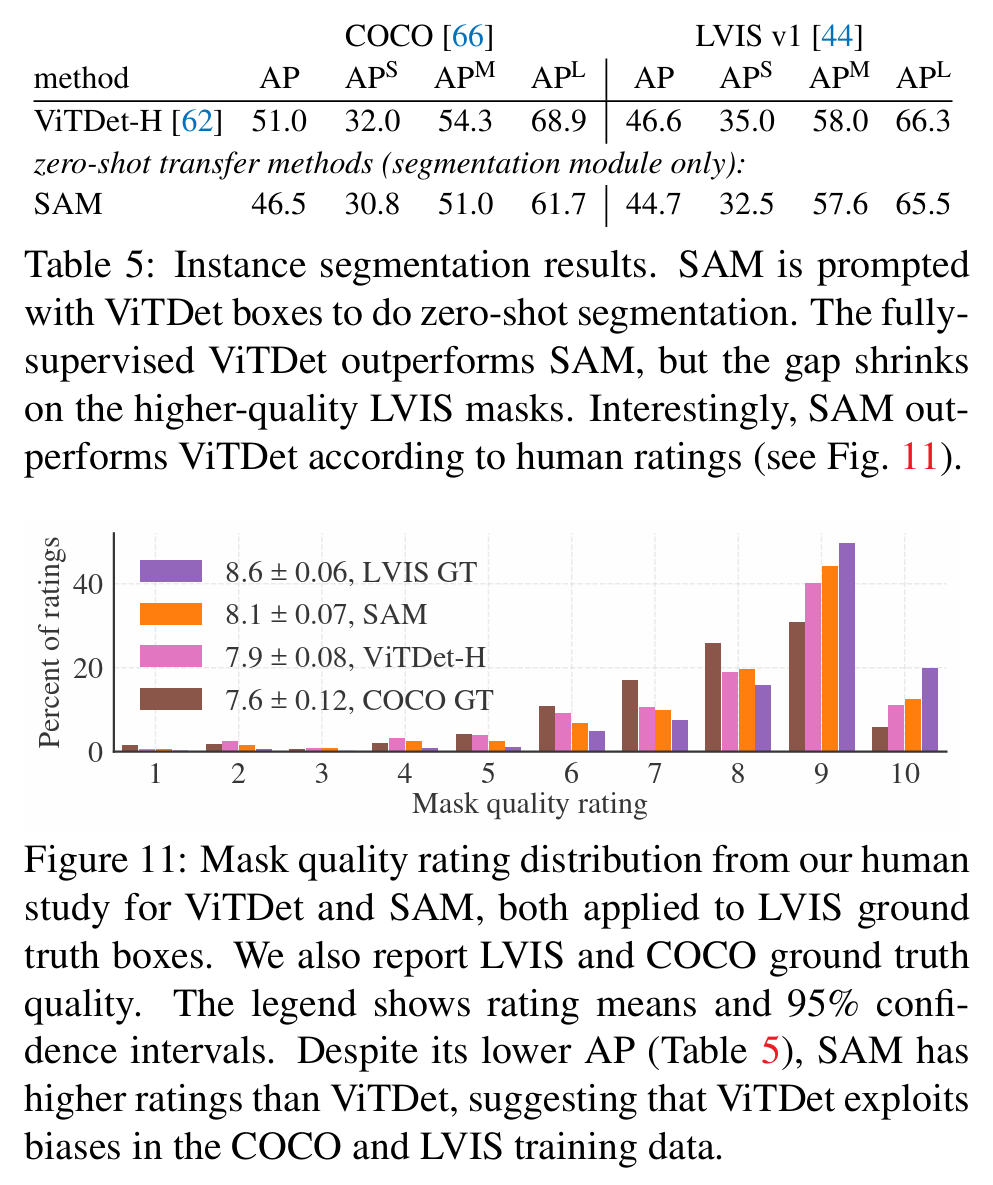
4. 实例分割
5. Text2Mask

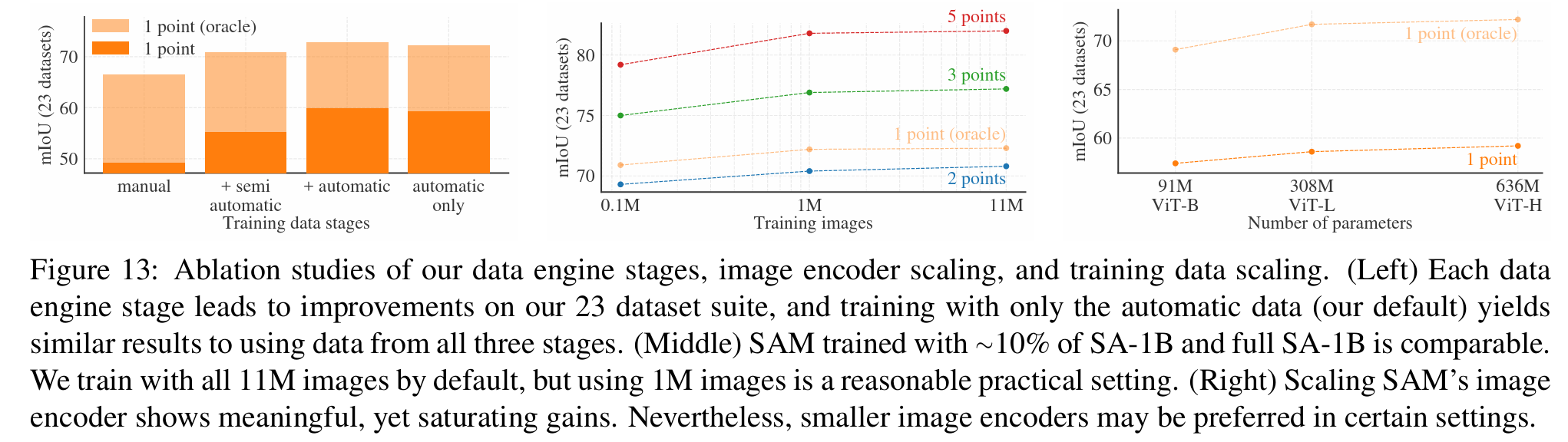
6. 消融实验(Ablations)