LeetCode的39和40两道题都是CombinationSum,它们都可以用深度优先搜索(DFS)来解决(当然也还有许多其它方法)。这篇博客就系统的来介绍DFS和CombinationSum这一类问题。
题目
LeetCode39:
Given a set of candidate numbers (C) (without duplicates) and a target number (T), find all unique combinations in C where the candidate numbers sums to T.
The same repeated number may be chosen from C unlimited number of times.
Note:
- All numbers (including target) will be positive integers.
- The solution set must not contain duplicate combinations.
For example, given candidate set
[2, 3, 6, 7]and target7,
A solution set is:[ [7], [2, 2, 3] ]
LeetCode40:
Given a collection of candidate numbers (C) and a target number (T), find all unique combinations in C where the candidate numbers sums to T.
Each number in C may only be used once in the combination.
Note:
- All numbers (including target) will be positive integers.
- The solution set must not contain duplicate combinations.
For example, given candidate set
[10, 1, 2, 7, 6, 1, 5]and target8,
A solution set is:[ [1, 7], [1, 2, 5], [2, 6], [1, 1, 6] ]
分析
39和40的区别在于,对于集合中的每个元素,39中每个元素可以取多次,40中每个元素只可取一次(但是元素的数值可重复)
深度优先搜索
形象的用下面的图像表示一个序列[a b c]在搜索时的搜索路径,对于第一个问题:
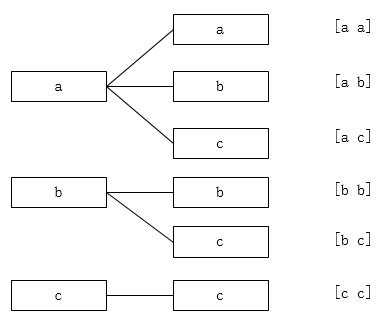
对于第二个问题:
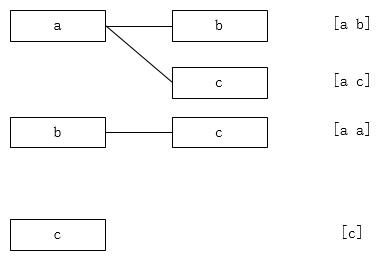
它们的剪枝条件都是: sum(selected) >= target
其中第二个问题,由于数字可能重复,所以需要先进行排序,然后通过一些方法去除排列组合引起的重复,具体方法在代码分析中会讲到。
代码
CombinationSum
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
class Solution {
public:
vector<vector<int> > combinationSum(vector<int> &candidates, int target) {
if (candidates.empty()) return res;
dfs(0, 0, target, candidates);
return res;
}
private
void dfs(int start, int sum, int target, vector<int>& candidates){
if (sum == target){
res.push_back(ans);
return;
} else if (sum > target){
return;
} else{
for (int i = start; i < candidates.size(); i++){
ans.push_back(candidates[i]);
dfs(i, sum + candidates[i], target, candidates);
ans.pop_back();
}
}
}
vector<vector<int>>res;
vector<int>ans;
};
int main(int argc, char *argv[]){
Solution s;
system("pause");
return 0;
}
CombinationSum2
class Solution {
public:
vector<vector<int>> combinationSum2(vector<int>& candidates, int target) {
sort(candidates.begin(), candidates.end());
vector<int>tmp;
dfs(candidates, target, tmp, 0);
return s;
}
private:
void dfs(vector<int>& candidates, int target, vector<int>&tmp,int cur){
if (target < 0) return;
if (target==0){
s.push_back(tmp);
return;
}
for (int i = cur; i < candidates.size(); i++){
if (cur != i&&candidates[i] == candidates[i-1]) continue;//i-1,i
tmp.push_back(candidates[i]);
dfs(candidates, target-candidates[i], tmp,i+1);
tmp.pop_back();
}
}
vector<vector<int> > s;
};
代码分析
第二份代码首先进行了排序,一方面是出于效率考虑,另一方面也是判断重复数字的需要。
由于每个数字不能重复,在每层cur时,第一份代码是由i开始的而第二份代码是从i+1开始的。同样是由于不能重复,所以有下面一行代码:
if (cur != i&&candidates[i] == candidates[i-1]) continue;
我们举一个例子来说明下:
如果一个序列是 1 1 1 1 6, target = 8
那么在扫面第一个1时,将后面的第2,3,4号,三个1都看做一个1,因为后面的1选择哪一个都是等价的,如果不加区分会出现重复,按照这样的规则进行搜索,就可以避免重复。这是第二个问题中最核心的一段代码。