级联CNN提出与2015年,在目标检测领域有着很成功的应用。好久好久好久没看过目标检测了,今天被问到这个,临时翻论文到源码,发现还是很容易理解的。只是好久好久好久没玩Caffe,发现Caffe现在丰富了太多。这篇博客介绍的MTCNN人脸检测,就是基于Caffe平台的,与级联CNN有关,清楚所有技术细节之后,决定写一篇博客记录一下。
1.方法概述
基于深度学习的目标检测一般分为两种:基于滑动窗口的分类 和 基于目标显著性的方法。
基于滑动窗口的分类需要对每一个滑窗进行判断,速度可能会比较慢,在CNN中,卷积有一个显著的优点就是权值共享,它可以很好的进行计算结果的重复利用,所以基于CNN的网络速度也不会特别慢。
在基于目标显著性的方法中,例如R-CNN,主要方法是快速检测可能的目标区域块,然后用训练好的深度网络模型进行特征提取,之后再进行分类。它主要解决滑动窗口目标检测方法中窗口过多的问题。
2. 级联CNN
CascadeCNN出自2015年CVPR《A Convolutional Neural Network Cascade for Face Detection》。这篇论文对经典的Viola jones方法的CNN进行实现,下图是流程示意图。

级联的工作原理和好处:
- 最初阶段的网络可以比较简单,判别阈值可以设得宽松一点,这样就可以在保持较高召回率的同时排除掉大量的非人脸窗口;
- 最后阶段网络为了保证足够的性能,因此一般设计的比较复杂,但由于只需要处理前面剩下的窗口,因此可以保证足够的效率;
- 级联的思想可以帮助我们去组合利用性能较差的分类器,同时又可以获得一定的效率保证。
每一阶段,不断筛选窗口,下图展示该网络三阶段平均剩余窗口及召回率
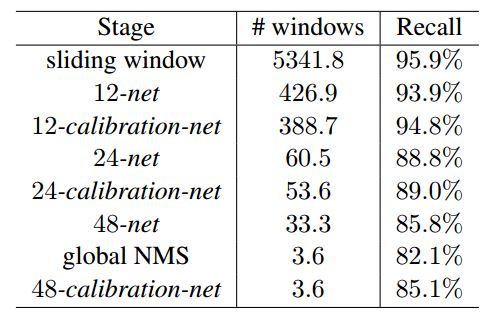
3.多尺度特征
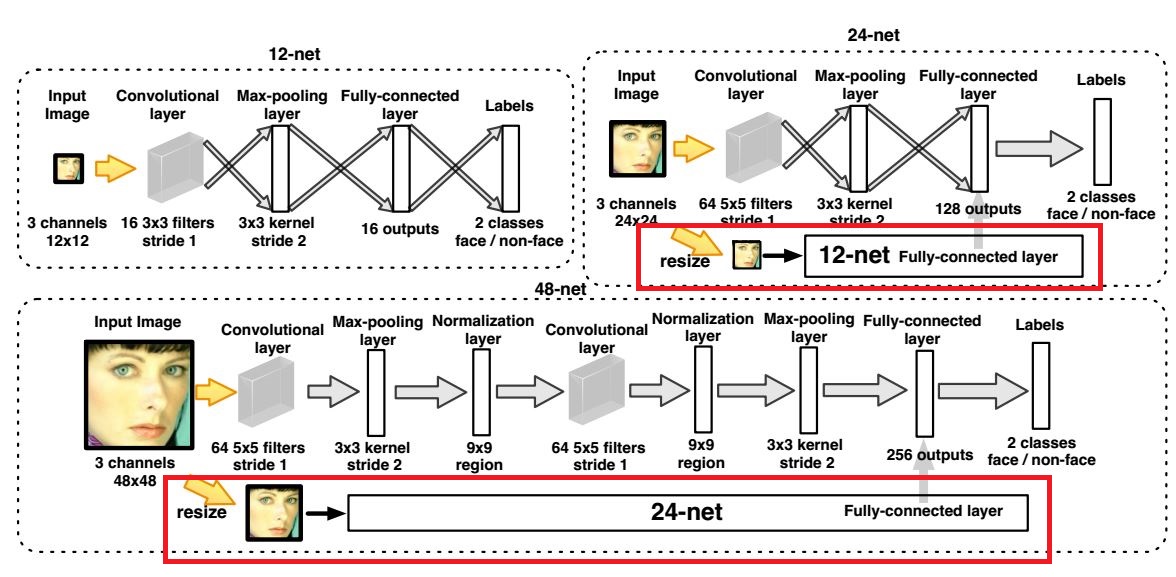
上图可以看出,前两阶段的网络都非常简单,只有第三阶段比较复杂。这里以第2阶段的24-net为例,首先把上一阶段剩下的窗口resize为24*24大小,然后送入网络,得到全连接层的特征。同时,将之前12-net的全连接层特征去除并与之凭借在一起,最后对组合后的特征进行Softmax分类。这就是CascadeCNN实现多尺度特征组合的方式。

上图可见,采用多尺度特征可以相同条件下获得相对较高的召回率,即提升了网络的分类能力。
4.矫正网络
每一个分类网络的输出都会经过一个对应的矫正网络之后,才会被送到下一阶段。矫正过程就是需要回归三个参数:缩放比例sn,水平平移xn,垂直平移yn,然后根据回归得到的量来矫正矩形框。
5.人脸检测MTCNN

stage1: 在构建图像金字塔的基础上,利用fully convolutional network来进行检测,同时利用boundingbox regression 和 NMS来进行修正。(注意:这里的全卷积网络与R-CNN里面带反卷积的网络是不一样的,这里只是指只有卷积层,可以接受任意尺寸的输入,靠网络stride来自动完成滑窗)
stage2: 将通过stage1的所有窗口输入作进一步判断,同时也要做boundingbox regression 和 NMS。
stage3: 和stage2相似,只不过增加了更强的约束:5个人脸关键点。
补充:
(1) 文中训练使用了Online Hard sample mining策略,即在一个batch中只选择loss占前70%的样本进行BP;
(2) 不同阶段,classifier、boundingbox regression 和 landmarks detection在计算Loss时的权重是不一样的;
(3) 训练数据共4类,比例3:1:1:2,分别是negative,IOU<0.3; positive,IOU>0.65; part face,0.4
看了源码,首先,由Slice层提出候选区域,参见Caffe源码,Slice层的作用就是产生滑动窗口。然后,P网络初步筛选,R网络细化进一步筛选,O网络最终输出,总之就是一层一层的筛选。
速度表现,CPU越15fps

Post几个链接:
Cascade CNN: http://blog.csdn.net/shuzfan/article/details/50358809
MTCNN: http://blog.csdn.net/shuzfan/article/details/52668935
Code: https://github.com/kpzhang93/MTCNN_face_detection_alignment