前排参考链接:
我们都知道人工神经网络的基本结构是:输入层、隐藏层、输出层,没一层都由神经元构成,神经元包含权重矩阵和激活函数,有对应的反向传播来迭代。
如果我们一个个单独处理输入,前一个输入和后一个输入是完全没有关系的,那么我们就不能很好利用任务中输入的序列信息,即丢失了前面输入和后面输入的关系。为了解决这个问题,RNN就出现了。
比如,我们不能单靠一个个孤立的词汇来理解意思,我们必须把词汇形成语句,对语句进行分析,才能意会。
RNN
我们看一下一个简单RNN的结构:
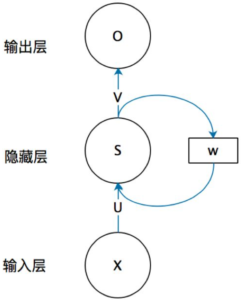
X为输入层,U为输入层权重矩阵,O为输出层,V为输出层权重矩阵,这两部分和其它类型的人工神经网络一样。重点在于S和W,RNN的隐藏值S不仅区别于这次的输入x,还区别于上一次隐藏层的值S。权重矩阵W就是上一次的值作为这一次输入的权重。

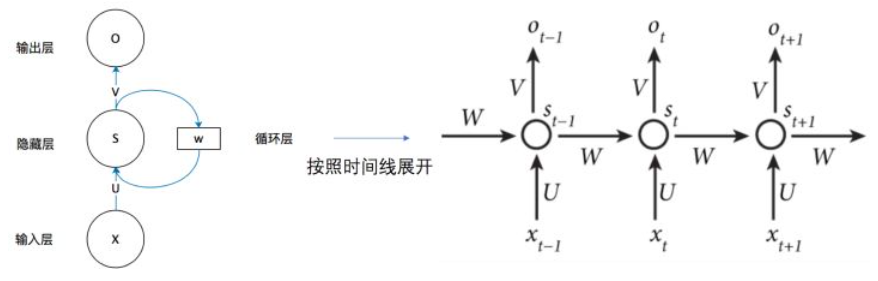
我们在时域上简单展开,就可以看到网络结构是这样的:
Sequence to Sequence
RNN时域展开后的结构是这样的,每个时域输入对应于一个时域输出
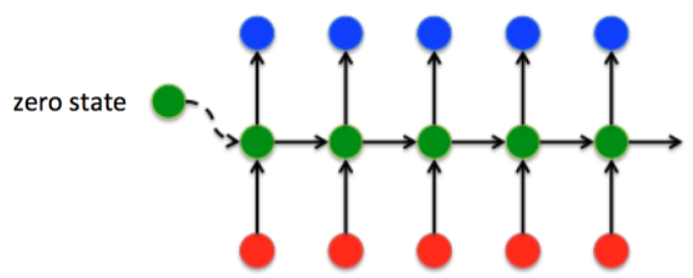
我们先看下Seq2Seq的网络结构
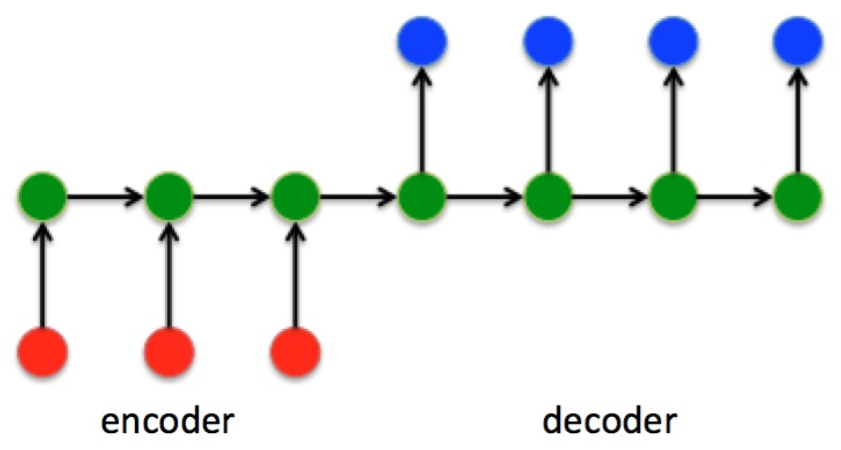
在Seq2Seq结构中,编码器Encoder把所有输入序列都编码成一个统一的语义向量Context,然后再由解码器Decoder解码。在解码器Decoder解码过程中,不断将前一时刻t-1的输出作为后一时刻t的输出,循环解码,直到输出停止符为止。

与RNN结构不同,Seq2Seq结构不再要求输入和输出序列有相同的时间长度。
我们再看下Decoder端数据流:

RNN的输入为[ni,1]的向量,输出为[no,1]的向量,接着使用全连接fc将yt变为大小为[nc,1]的向量yt’,其中nc代表类别数量,然后我们通过softamx和argmax获取类别index,再通过int2str获取输出字符,最后将类别index输入到下一状态,知道收到stop标识符停止。
Embedding
这时Seq2Seq中的一点细节,就是如何将前一时刻输出类别index(数值)送入下一时刻输入(向量)进行编码。我们使用嵌入(embedding)的方法
假设我们使用one-hot编码,则词表如下:
'<start>' : 0 <-----> label('<start>')=[1, 0, 0, 0, 0,..., 0]
'<stop>' : 1 <-----> label('<stop>') =[0, 1, 0, 0, 0,..., 0]
'hello': 2 <-----> label('hello') =[0, 0, 1, 0, 0,..., 0]
'good' : 3 <-----> label('good') =[0, 0, 0, 1, 0,..., 0]
'morning' : 4 <-----> label('morning')=[0, 0, 0, 0, 1,..., 0]
.......
但是使用one-hot编码,嵌入就会过于系数,所以我们使用一种更加优雅的方法:
首先随机生成一个大小为[nc, ni] 的embedding随机矩阵,然后通过start标志的one-hot编码诚意embedding矩阵(即获取emdding矩阵第i_label 行)作为向量输入网络,循环解码。
除Embedding外,我们还可以使用word2vec/glove/elmo/bert等嵌入方法,参考:开苏入门词嵌入之word2vec。
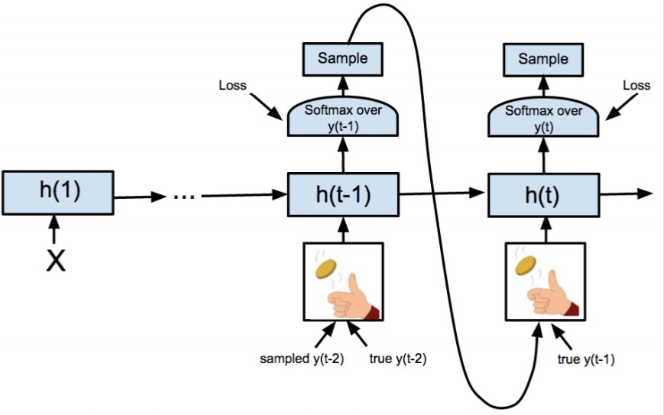
Seq2Seq的训练问题
由于Seq2Seq网络结构的特点,t时刻结构出错,将导致后面y的结果全部出错,为解决这个问题,Google提出了Scheduled Sampling(在训练中xt按照一定概率选择输入y_t-1 或 t-1时间对应的真实标签),既能加快训练速度,也能提高训练精度。
Attention注意力机制
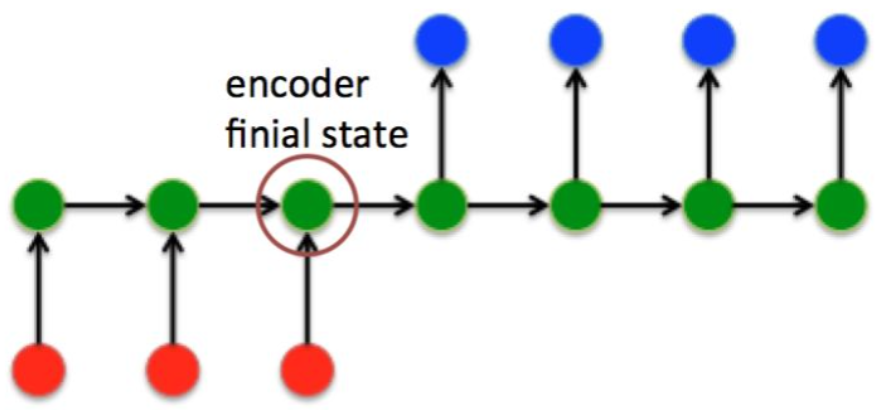
在Seq2Seq结构中,encoder把所有的输入序列都编码成一个统一的语义向量Context,然后再由decoder解码。由于context包含原始序列中所有信息,它的长度就成了限制模型性能的瓶颈。如机器翻译问题,当要翻译的句子较长时,一个Context可能存不下那么多信息,就会造成精度的下降。除此之外,如果按照上述方式实现,只用到了编码器的最后一个隐藏状态,信息利用率就会下降。
如果要改进Seq2Seq结构,最好的切入角度就是:利用Encoder所有隐藏层状态ht解决Context长度限制问题。
接下来了解一下Attention注意力机制基本思路
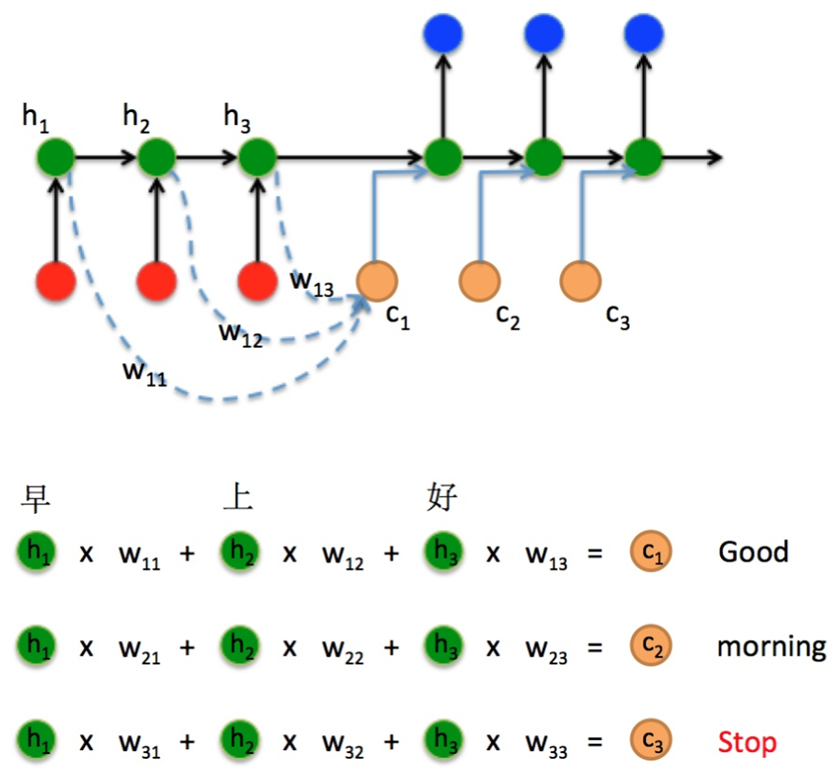
考虑这样一个问题:对于输入序列“早”“上”“好”,由于Encoder隐藏层h1 h2 h3 分别对应不同时刻输入xt的编码结果。我们Decoder在t1时刻,计算出一个向量c1,将这个向量与前一个状态concat 拼接在一起形成一个新的向量输入到隐藏层计算结果:
![]()
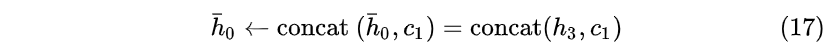
之后每个隐藏层也都将对应输入xt的ht编码进来,形成一种注意力机制,这样就解决Context的长度限制问题了。
LuongAttention注意力机制
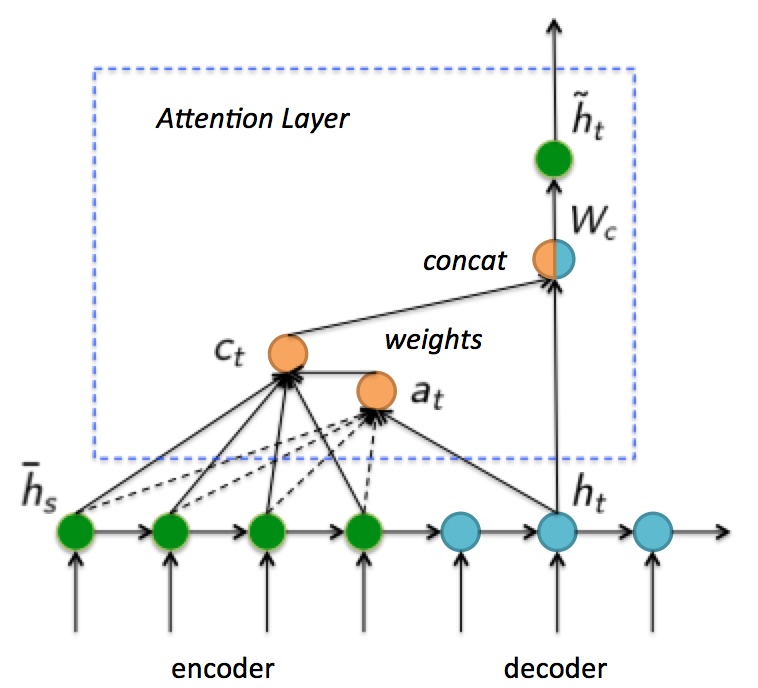
这里说明下上图中符号的含义:
hs代表encoder状态,ht代表decoder状态,ht~ 代表attention layer最终输出的decoder状态。hs 和 ht 时 [nh, 1]的向量。接下来我们看注意力机制具体实现方式。
首先,计算Decoder的t时刻状态ht对应的Encoder隐含层状态hs,权重为at(s)
score可以通过如下三种方式计算:内积、Wa权重计算,Concat方法:(一般认为General方法好于内积方法)
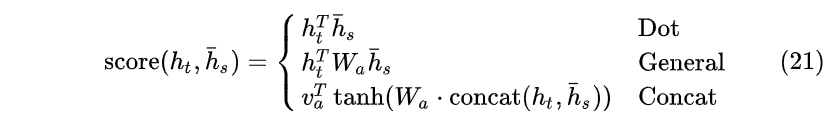

利用at计算所有隐藏层状态的加权之和ct,用ct进行concat得到新的隐藏层,

由于拼接之后ht会变大,要恢复ht为原来的大小,需要乘以全连接矩阵Wc。(不恢复大小也可以,但是decoder cell会变大)。
最后加入注意力的Decoder状态诚意Who矩阵进行输出,把新生成的ht~送入RNN继续学习。
在实际应用中,可以把注意力权重画出来,可以看到时刻t注意力机制到底注意到了什么。
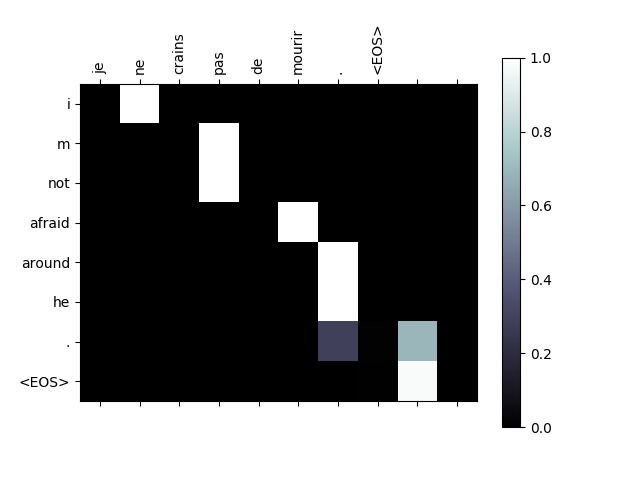
Attention机制对Seq2Seq结构有很大提升。
向RNN加入额外信息
Attention机制其实就是将Encoder RNN隐藏层状态得到的加权向量ct额外加入到decoder中,给Decoder RNN网络添加额外信息,从而适得网络有更完整的信息流, 这里有三种添加额外信息的方式, ADD , CONCAT, MLP(新添加一个对encoder隐藏层的感知单元)
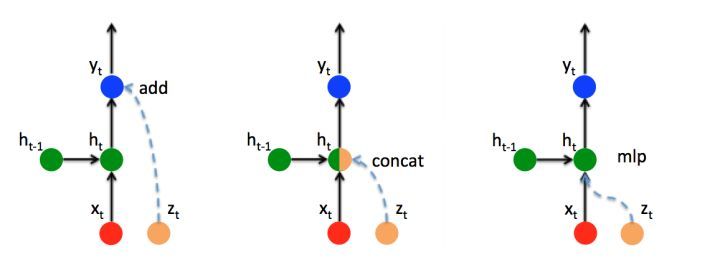
Attention的实现机制有很多种, 本文只时拿一种典型case距离, 这是本文浅显之处。