通过视觉测量深度的方法目前分为如下几种,一种是双目立体匹配,该方法的好处是有一个明确的物理模型,存在视差的概念,深度信息是根据时差转换得到,另一种是单目运动,该方法也可以看成一种特殊的双目模型或者多目模型,只不过它是时间上的多目,还有一种方法是完全的单目深度估计,直接由网络端到端给出深度,单目网络在可解释性和可移植性上不如双目和单目运动,但是其效果没有比双目差太多。
随着近年来车载系统视觉方案不断完善,立体视觉问题不断收敛,学界出现了一批轻量级网络,效果还不差,这篇博客主要介绍一个轻量级双目立体匹配网络mobilestereonet,后文简称MSN。博主理解MSN主要贡献还是在与对网络模型的压缩,骨干和后面的特征提取大量使用深度可分离卷积,而论文中提及的一些网络结构,经过博主实验下来,这些并不重要(比如3d卷积用分组卷积替代,网络性能并没有明显降低),直接感受是,参数确实更少,计算也更少。
相关资料
首先,我们梳理一下已经公开的资料
- 开源代码
- WACV2022论文
- 论文补充材料
- 介绍ppt视频:本文大部分图是从这份ppt里面扣的
问题概述
双目立体匹配就是根据左图和右图匹配计算得到对应像素点在极线方向上偏移(即左右视差),进而得到深度的过程,这里有一个基础公式:z=bf/d。 (深度=基线*焦距/视差)
所以双目立体视觉问题的核心是求取视差,熟悉算法原理的同学应该很清楚,这里不过多概述。
网络结构
网络结构大概分成几部分,第一部分是特征提取,第二部分是视差代价结构的计算,第三部分是编解码器和视差回归。
论文中给出了两种网络结构,其主要区别在于视差代价的数据是3D还是4D,(cost volume),视差代价4D结构的网络计算量更大,效果也更好,视差代价是3D的网络也有一个地方需要3D卷积来进行处理,3D网络这里实际这里可以用分组卷积来替代而不会带来性能的降低,以利于硬件实现,而4D网络几乎处处都是3D卷积。
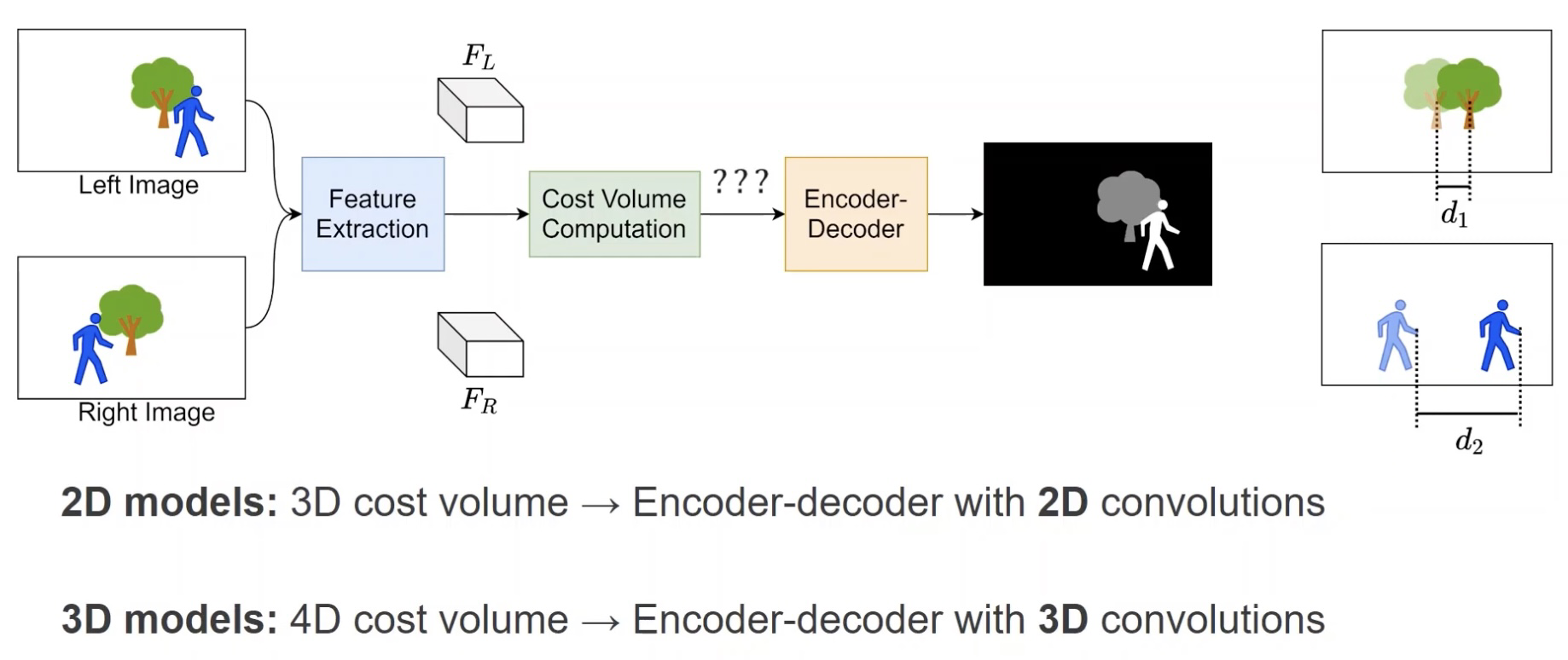
2D网络模型和3D网络模型相比,其在cost volume计算之前会进行特征通道减少,来压缩特征,减小后面的计算。通过下图可以看到其他部分网络的主题构成差不多。
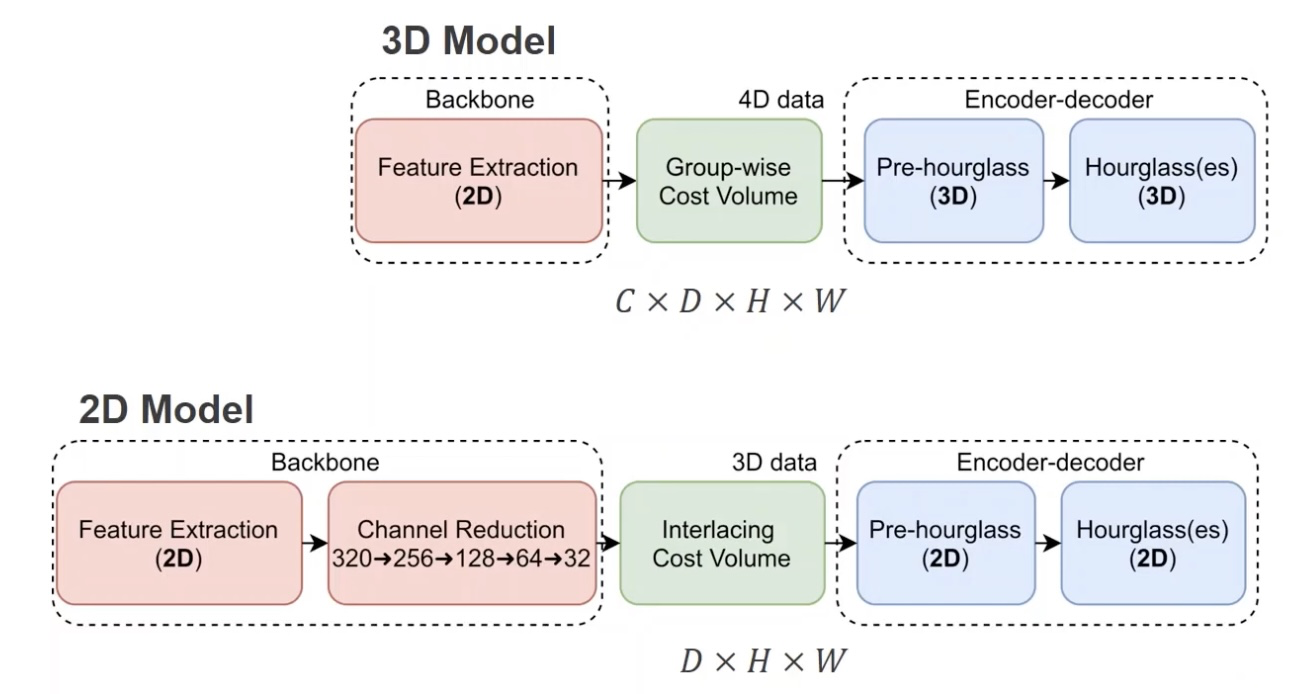
我们更细致的看官方给的网络模型中数据的形状,特征提取部分两个网络的数据是相同的,在后续Cost Volume计算开始,3D模型都比2D模型要多一个数据维度,可以明确的是3D网络的计算更加复杂,大量使用3D卷积。
从网络形状中,我们也可以发现网络给出的视差cost大小是48*64*128,最终需要的视差图是256*512, 最大视差支持到192。这里我们要理解视差cost在进行视差回归之前需要4倍上采样,softmax 得到 192*256*512的结构(其含义是每个像素点对应0到191视差的概率),然后来进行视差回归。
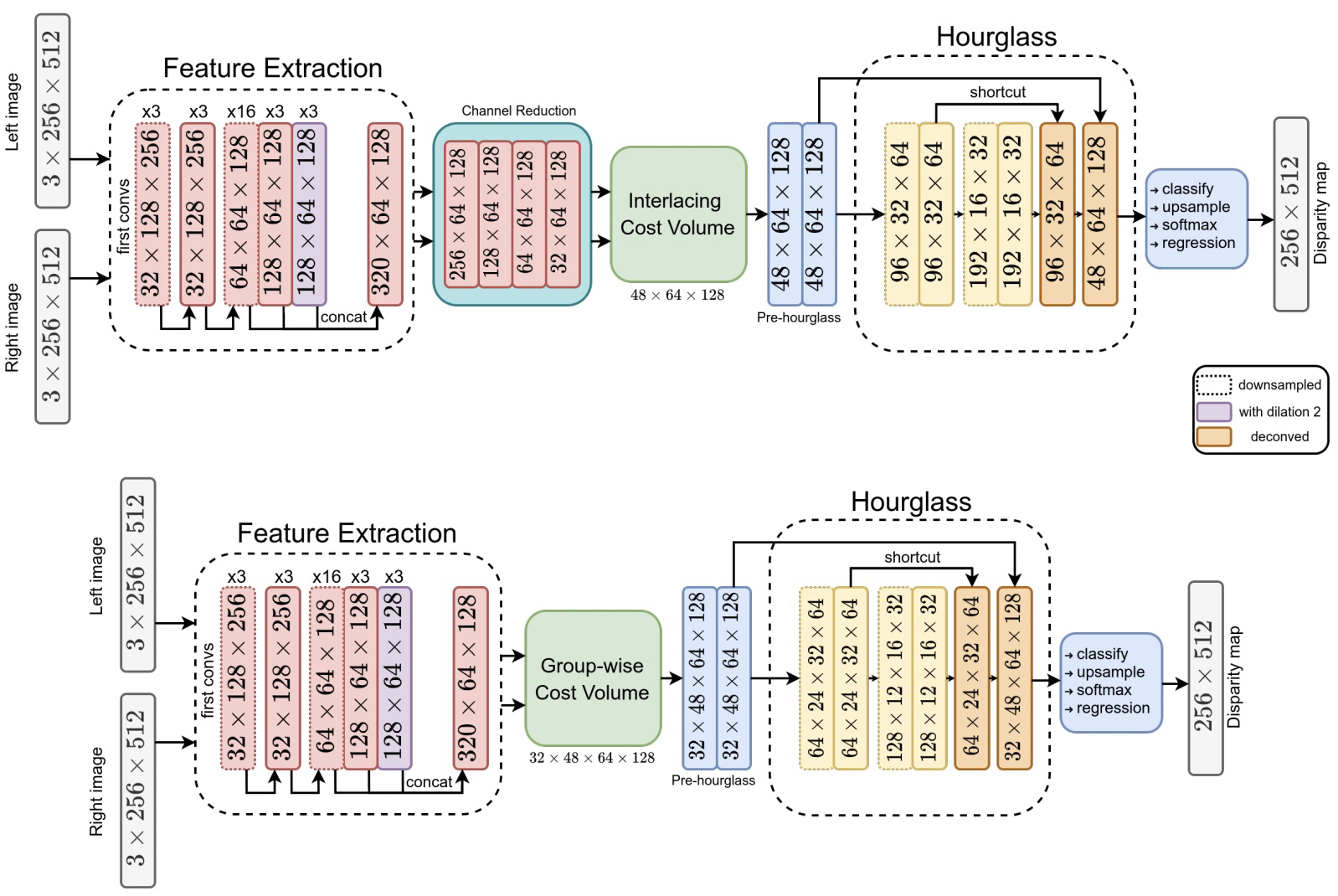
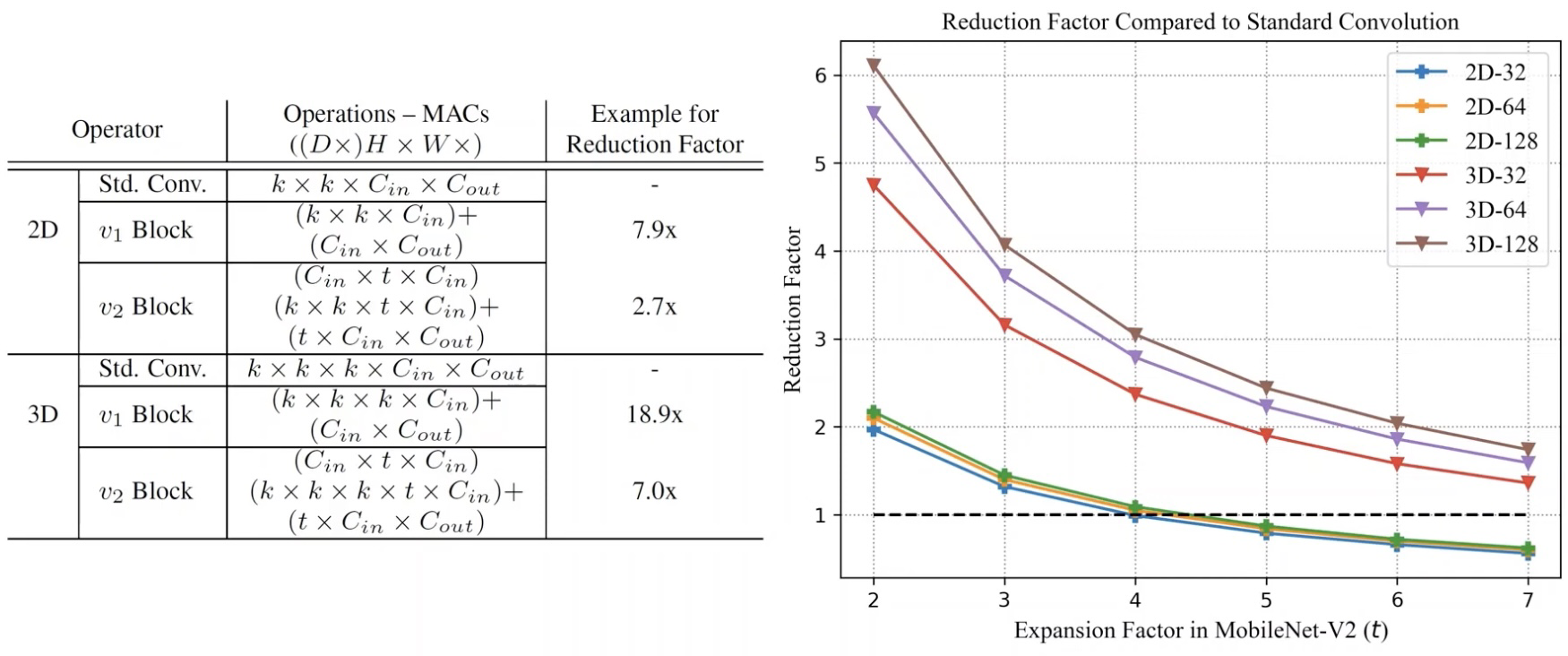
网络中大量使用深度可分离卷积,通过将mobilenetblock提升一个维度拓展得到3D形式,有效降低网络参数量和计算量。

下图明确告诉我们使用DepthWise结构参数减少了多少。
视差代价计算
视差代价是网络中最重要的部分,我们需要对这部分深刻理解。因为立体匹配中存在着极线约束,经过立体矫正之后,视差呈现为水平方向视差。我们网络的输入也是经过立体矫正的,所以我们视差也体现在水平方向。
下图红色是表示作图的特征,蓝色是表示右图的特征,我们在计算cost volume之前要将作图的特征和右图的特征组合起来,组合的方式是在水平的维度上进行交织interwave。
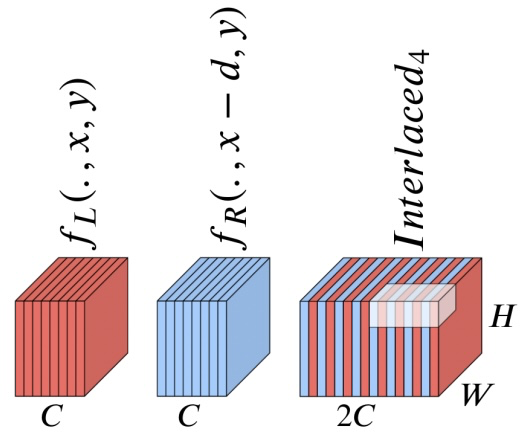
由于我们最终需要回归的视差范围(比如0到191)是对应于水平方向平移了0到191,所以我们在cost volume中每个通道都对应一个特定的视差值(下图最右侧)。
为了得到视差d所对应的平面,我们将左右特征在水平方向平移d进行特征组合,再通过3d卷积(或者2d分组卷积)得到一个通道的特征,作为cost volume中视差d所在的平面。
最终这个3D Cost Volume经过上采样后的大小为d*H*W,可以把它看作图像每个像素点H*W对应各个视差d的概率,可以用来进行视差回归
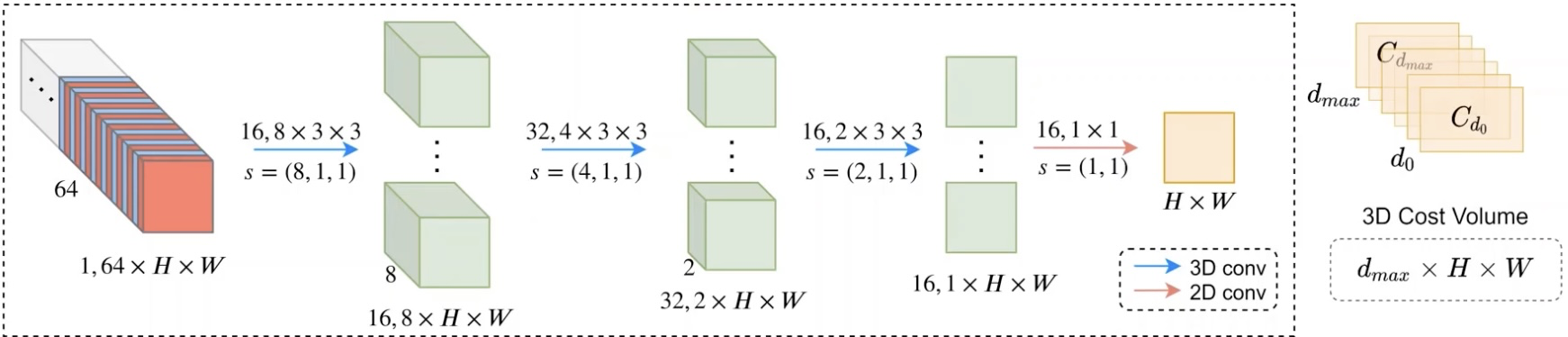
我们还可以在cost volume后面接入几个encoder-decoder结构进行细化,原文代码中接了3个encoder-decoder,再进行的视差回归。
下面是网络的性能对比(如果舍弃一些性能,网络可以被压缩到 零点几M,基本上很适合嵌入式系统实现了)

训练Loss
采用L1 loss,这里需要留意的是,测试时视差从第三个encoder-decoder输入,但是训练时,cost和三个encoder都有视差回归来输出视差图,各个视差图都参数了loss计算。
谢谢,希望能有帮助!