京东方的一篇论文,主打轻量级网络做Real-Time SR,只有一层,对标传统bicubic上采样,因为轻量,所以实用,同时一层网络的可解释性也更强。
论文地址:Edge-SR:Super-Resolution For The Masses
代码:https://github.com/pnavarre/eSR
一、介绍
文章说他们有下面几个贡献:
- 提出了一层网络结构,介于经典方法和NN方法之间的单层网络用语超分
- 搜索了1185个网络模型,给出了特定情况下的质量比较和性能比较
- 解释和分析self-attention单层网络结构在上采样问题上的一些规律
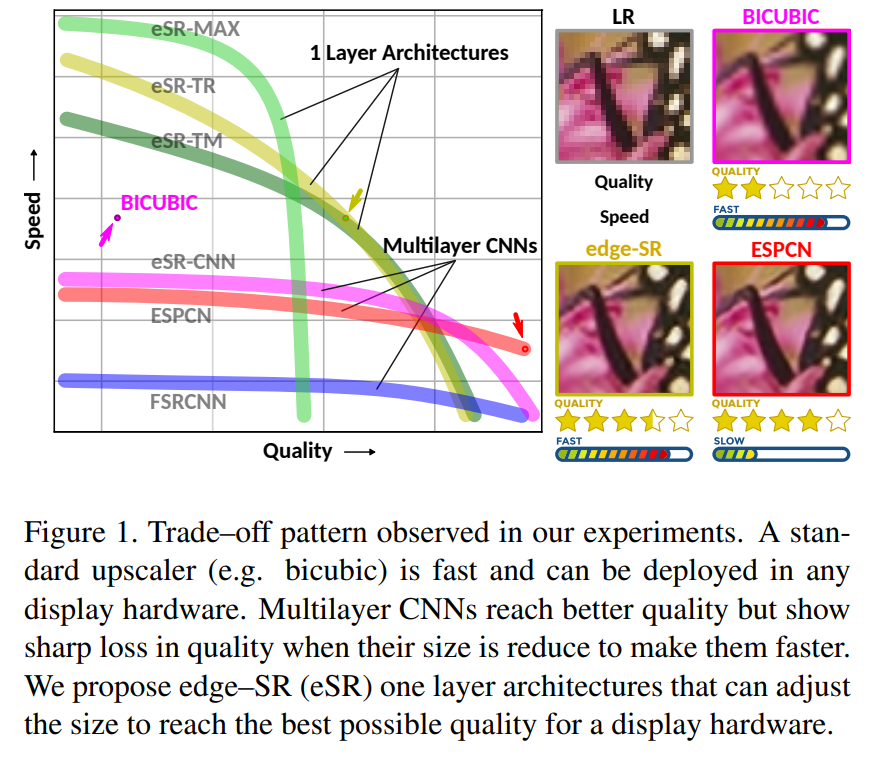
Bicubic本质是是一个4×4卷积,可以在硬件上很快实现,并且具有不错的推理速度。多层CNN网络具有较好的结果质量,但是推理速度较慢。文章中给出两种单层网络结构(eSR-TR、eSR-TM),在推理速度较快的情况下,结果质量可以和多层网络比较。
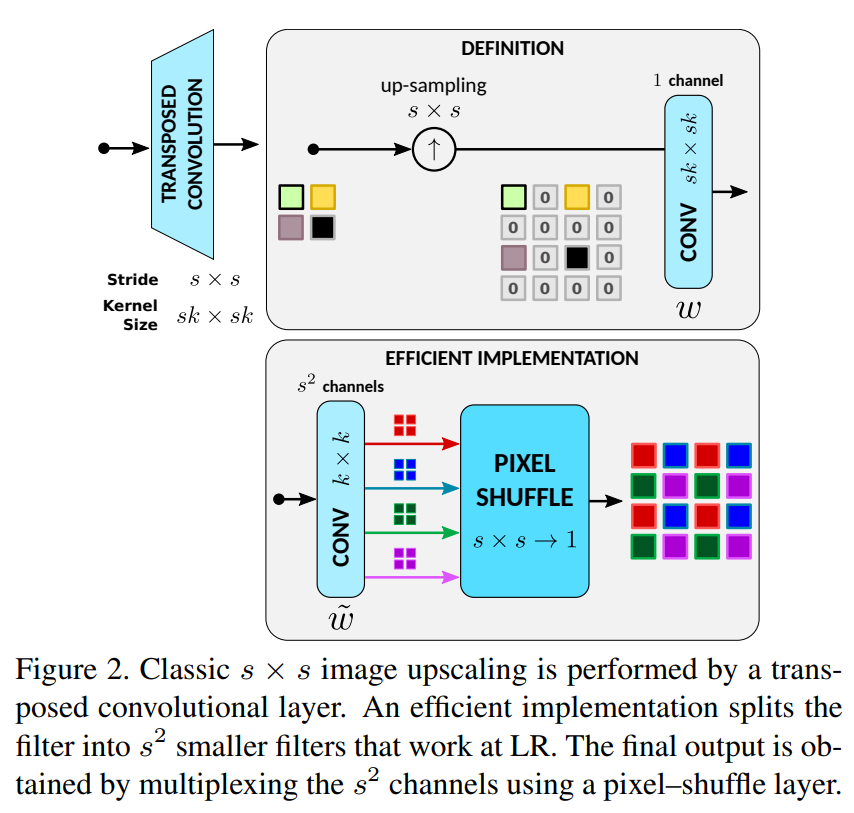
文章讨论了是先上采样再滤波还是先滤波再上采样,认为先滤波再上采样效率更高,用滤波生成k*k个通道,然后通过pixel shuffle上采样上来。这样的实现和标准bicubic具有等价性(滤波上采样)。
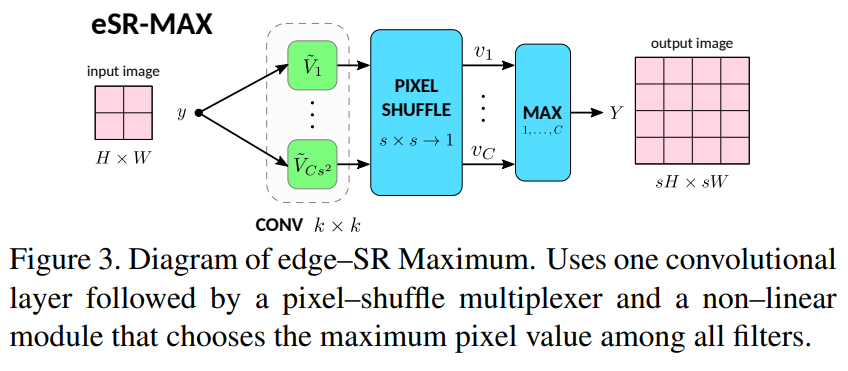
二、eSR-MAX网络
基于上面的实现,文章提出了一个单层网络eSR-MAX,第一步先用前面所述的方式上采样出C张图(大小为s*s*C),然后通过MAX选择器,从C个通道中选择最大像素值作为最终的输出。
可以看下面的代码实现,以方便理解:
class edgeSR_MAX(nn.Module):
def __init__(self, C, k, s):
super().__init__()
self.pixel_shuffle = nn.PixelShuffle(s)
self.filter = nn.Conv2d(1,s*s*C,k,1,(k-1)//2,bias=False)
def forward(self, x):
return self.pixel_shuffle(self.filter(x)).max(dim=1, keepdim=True)[0]
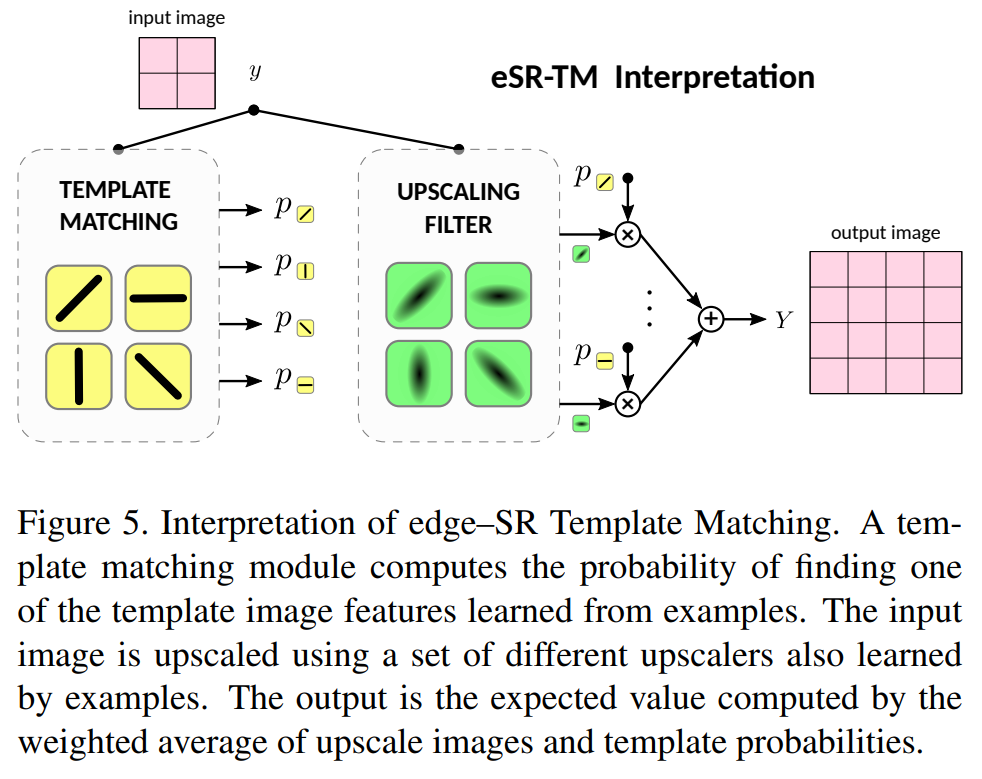
三、eSR-TM网络
文章提出的第二个网络eSR-TM,它采用了self-attention,具有模板匹配的思想
可以直观的可视化attention到的模板,以及模板对应的滤波器kernel,可解释性比较好。
class edgeSR_TM(nn.Module):
def __init__(self, C, k, s):
super().__init__()
self.pixel_shuffle = nn.PixelShuffle(s)
self.softmax = nn.Softmax(dim=1)
self.filter = nn.Conv2d(1,2*s*s*C,k,1,(k-1)//2,bias=False)
def forward(self, x):
filtered = self.pixel_shuffle(self.filter(x))
B,C,H,W = filtered.shape
filtered = filtered.view(B,2,C,H,W)
upscaling= filtered[:,0]
matching = filtered[:,1]
return torch.sum(upscaling * self.softmax(matching), dim=1, keepdim=True)
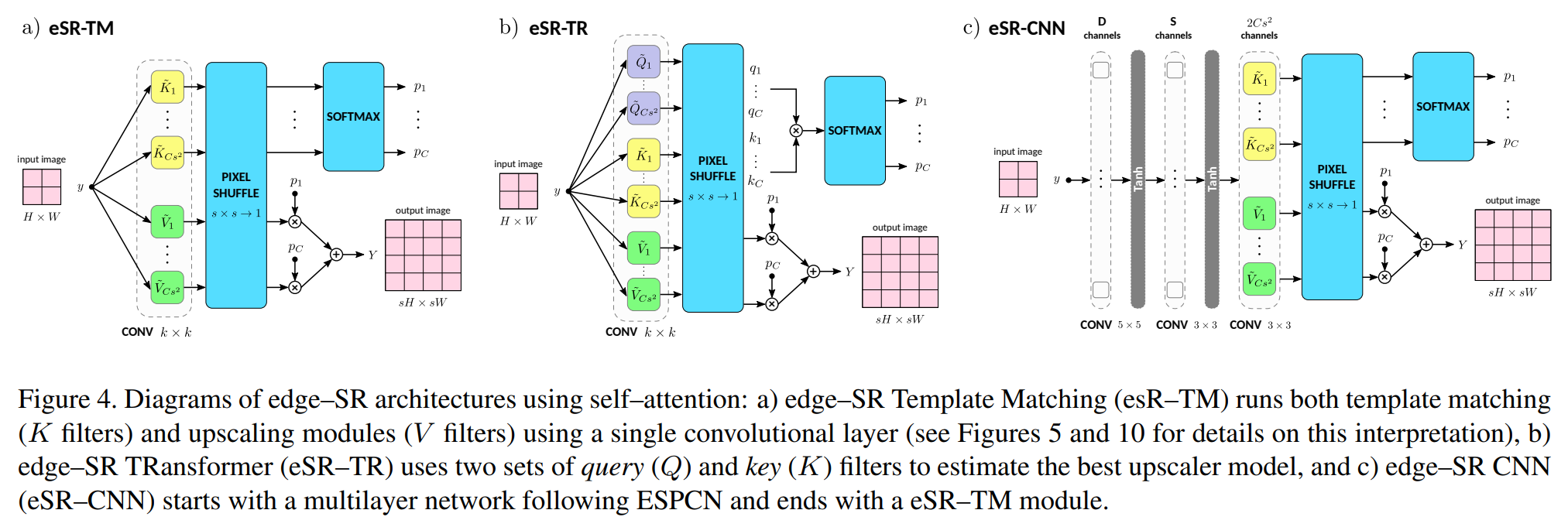

四、eSR-TR网络
文档提出的第三个方案是 edge-SR Transformer,它采用了transformer的子注意力机制,某种程度上简化了eSR-TM。
与eSR-TM的不同之处在于,filter之后得到的不是matching、upscale两个变量,Transformer得到的时V、Q、K,直接attention输出就可以了
class edgeSR_TR(nn.Module):
def __init__(self, C, k, s):
self.pixel_shuffle = nn.PixelShuffle(s)
self.softmax = nn.Softmax(dim=1)
self.filter = nn.Conv2d(1,3*s*s*C,k,1,(k-1)//2,bias=False)
def forward(self, x):
filtered = self.pixel_shuffle(self.filter(x))
B,C,H,W = filtered.shape
filtered = filtered.view(B,3,C,H,W)
value = filtered[:,0]
query = filtered[:,1]
key = filtered[:,2]
return torch.sum(value*self.softmax(query*key),dim=1,keepdim=True)
五、eSR-CNN网络
eSR-CNN版本是一个前面self-attention版本的变形,输入通过两层卷积之后,再attention一下。直接看代码比较清楚。
class edgeSR_CNN(nn.Module):
def __init__(self, C, D, S, s):
super().__init__()
self.softmax = nn.Softmax(dim=1)
if D == 0:
self.filter = nn.Sequential(
nn.Conv2d(D, S, 3, 1, 1),
nn.Tanh(),
nn.Conv2d(S,2*s*s*C,3,1,1,bias=False),
nn.PixelShuffle(s))
else:
self.filter = nn.Sequential(
nn.Conv2d(1, D, 5, 1, 2),
nn.Tanh(),
nn.Conv2d(D, S, 3, 1, 1),
nn.Tanh(),
nn.Conv2d(S,2*s*s*C,3,1,1,bias=False),
nn.PixelShuffle(s))
def forward(self, input):
filtered = self.filter(input)
B, C, H, W = filtered.shape
filtered = filtered.view(B, 2, C, H, W)
upscaling = filtered[:, 0]
matching = filtered[:, 1]
return torch.sum(upscaling * self.softmax(matching), dim=1, keepdim=True)