目标识别、目标检测、目标分割、目标跟踪是计算机视觉领域最热门的方向之一。传统机器学习方法中较为常见的做法是在滑动窗口中手工提取特征(例如Hog、SIFT等),然后将提取的特征送入分类器(例如SVM、Adaboost等)中,训练分类器预测输出。而每一类物体都有不同的特征,我们也很难提前知道哪种特征更加优秀,于是近年来目标识别的研究方向转向了深度学习。
目标识别(检测)问题与分类问题不同,识别或检测要求精准定位目标。一种解决问题的思路是将其看作一个回归问题,这种思路解决问题的效果可能并不理想,另一种更为普遍的做法还是使用滑动窗口进行检测。
深度学习综述(二)深度学习用于目标检测
R-CNN(Region Proposal CNN)
2012年之后,CNN在分类问题上的良好表现使得CNN很快流行起来,Szegedy尝试将识别问题转化为回归问题,但效果差强人意。由于CNN卷积层和池化层具有降采样的效果,较大的感受野影响了boundingbox的位置的精准程度。既然CNN在分类问题上效果很好,那为什么不把Detection问题转化为分类问题呢?
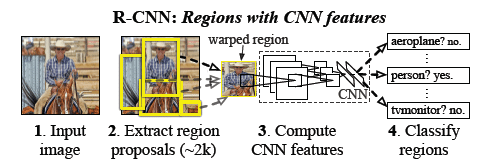
2014年,Ross Cirshick提出了R-CNN(Regions with CNN features)的方法。该方法在测试阶段先提取约2K数量的预选框,对于每个预选框通过CNN计算特征,然后将就算得到的特征送入svm分类器中,然后再对boundingbox进行回归以强化定位。其中CNN采用了对2012年AlexNet进行fine-tuning的架构,在PASCAL VOC 2010上的MAP达到57.3%,在ILSVRC2013 detection dataset达到31.4%,几乎全面优于传统的目标检测方法。
参考论文:RCNN , Selective Search , Unsupervised Search based Structured Prediction
SPP-net
R-CNN方法的主要缺陷在于计算的时间成本很大,根本达不到real-time的要求,SPP-net去除了R-CNN中预处理部分的crop与wrap操作,使得原始图像得到保护,再运行新提出的SPP代替最后一个卷基层的max-poolong层。
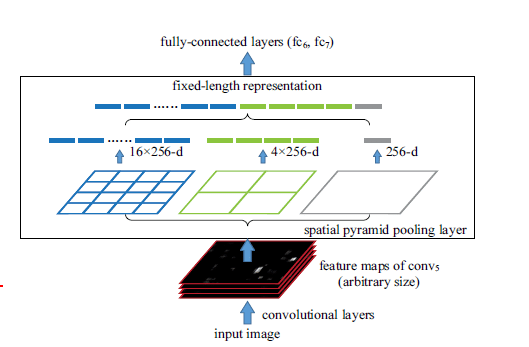

SPP即为金字塔池化,文中提出使用金字塔池化的方法完成对图像区域大小和长宽比的剪裁和缩放操作,这种方法产生的网络叫做SPP-net。将SPP层接到最后一个卷积层后面,SPP层池化特征并且产生固定大小的输出,然后将它的输出送到第一个全连接层。
SPP-net对输入图像尺度无限制,同时输出固定大小的特征。SPP中无需像R-CNN一样对每个Region提取特征,只需要对原始图像计算一次CNN,然后对不同region计算pooling,这种方法极大的提高了处理速度。
参考论文:SPP-in-DCN
Fast R-CNN
SPP-net虽然提高了R-CNN的速度,但和RCNN一样,他们的训练过程都是一个多阶段过程:包含着特征抽取,网络微调,SVM分类器训练,以及最后对BB回归的匹配,另外,SPP-net的卷积层是在线下计算的,所以微调技术只能更新全连接层,这无疑限制了深度CNN的潜力。
在此基础上,MSRA又提出了Fast R-CNN。相较于RCNN和SPP-net,Fast R-CNN的训练过程运用多任务损失,实现单步骤完成,在训练过程中所有层都可以得到更新,比RCNN的训练时间快9倍,测试时间快213倍,在PASCAL VOC 2012上的获得MAP也更高。与SPP-net相比,训练时间快3倍,测试时间快10倍,MAP也有提升。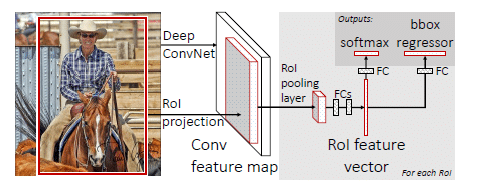
Fast R-CNN为双通道输入,引入ROI pooling层,在FC层后有两个输入。输入除了batch大小为N的图像外,还有R大小的ROI序列,这种多任务训练机制避免了对顺序训练任务的pipeline的管理,同事也对MAP的提高起到一定作用。fast R-CNN通过image-centric sampling提高了卷积层特征的抽取速度,从而保证了梯度的反向传播。将svm分类器换成softmax后MAP效果更为突出,并且不使用svm就可以让特征存在显存中,而不必存储特征到磁盘,这也提高了检测速度。
参考文献:fast RCNN
faster R-CNN
在之前的R-CNN采用selective search算法来获取预选框,而这种算法是cpu实现,速度较慢。2015年,一种对fast R-CNN的改进算法faster R-CNN被提出,
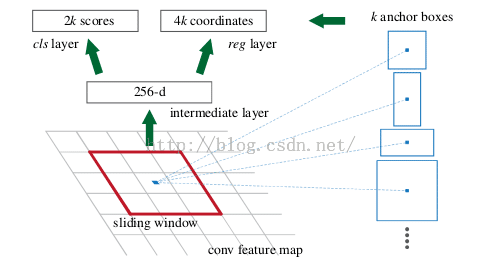
Faster-RCNN最大的贡献在于将proposal部分嵌入到网络中来,从此一个网络模型即可完成end-to-end的检测任务而不需要在执行算法前手动执行一遍proposal的搜索算法。RPN可以算作一个全图搜索的粗检测器,图片在输入网络后,一次经过一些卷积、池化层,然后得到的feature map被手动划分为n×n个矩形窗口(论文中n=3),准备后续用来选取proposal,并且此时坐标依然可以映射回原图。然后将每个矩形窗口的中心当成一个基准点,然后围绕这个基准点选取k个不同的scale、aspect ratio的anchor,对每个anchor后面接一个二类分类器softmax,有2个score输出用以表示其实一个物体的概率和不是一个物体的概率。
Faster RCNN在最后一个卷积层使用滑动窗口来代替原图中的滑动窗口,将selective search这样的算法整合到深度网络中,不光解决了selective search这样的算法是gpu实现,速度慢的问题,而且与深度网络相结合,共享前面的卷积计算,提高了算法效率,使得算法达到了real-time级别。
参考论文:Faster R-CNN
YOLO(You Only Look Once)
YOLO准确率和RCNN差不多,着重在于提升速度。Faster RCNN需要对20k个anchor box判断是否存在物体,然后再进行物体识别。而YOLO则把物体框的选择和识别进行了结合,一步输出,即变成“You Only Look Once”。识别速度非常快,达到每秒45帧,而快速版YOLO(Fast YOLO,卷基层更少)中,可以达到每秒155帧。
加快速度的YOLO带来了一定的局限性,由于出事图片需要被缩放到固定大小,可能对不同缩放比例的物体覆盖不全,每一个单元格只能用来选择一个物体框,并只预测一个类别,所以当多个物体中心落入一个单元格使,YOLO无法识别到小物体。
参考论文:YOLO
感谢以下博客:
RCNN, Fast-RCNN, Faster-RCNN的一些事
如何评鉴RCNN、FastRCNN、FasterRCNN等一系列方法
SSD&So on…
事物的发展是不断演进的,遵从螺旋式发展的规律:RNN、MultiBox、SPP-Net、DeepID-Net、Fast R-CNN、DeepBox、MR-CNN、Faster R-CNN、YOLO、DenseBox、SSD、Inside-Outside Net、G-CNN
目前SSD采用回归的方法,取得了state-of-art,也就是说,本篇博客最开头关于回归方法的描述已经过时,研究本身就是不断推翻前人结论的过程,技术本身就是风水轮流转,所有的论断都受限于所处的时代。
最后这一节是我后来追加的,不做更多方法的介绍,只是罗列出研究的步伐。
选择这样一个研究日新月异的领域就要不断跟进最前言的研究,并不被其束缚,既然技术本身是风水轮流转,何不坚持自己,争取到自己时代的到来呢。
OK, See You Next Chapter!