 图像跟踪一直都是计算机视觉领域的难题,事先知道第一帧中的目标位置,然后需要在后续帧中找到目标。先验知识少,目标被遮挡、目标消失、运动模糊、目标和环境的剧烈变化、目标的高速运动、相机的抖动都会对目标跟踪造成影响,图像跟踪一直都是CV领域的难题。
图像跟踪一直都是计算机视觉领域的难题,事先知道第一帧中的目标位置,然后需要在后续帧中找到目标。先验知识少,目标被遮挡、目标消失、运动模糊、目标和环境的剧烈变化、目标的高速运动、相机的抖动都会对目标跟踪造成影响,图像跟踪一直都是CV领域的难题。
深度学习用于图像跟踪有两大要解决的问题,一是图像跟踪一般使用在线学习,很难提供大量样本集,二是深度学习使用CNN时,由于卷积池化,最后一层的输出丢失了位置信息,而图像跟踪就是要输出目标的位置。
2013年以来,深度学习开始用于目标跟踪,并且为这些问题提供了一些解决思路。这篇博客首先阐述图像跟踪今年来的研究进展,然后再介绍深度学习用于图像跟踪近年来的研究,最后附上一些学习资料和相关网站。
一、图像目标跟踪概述
1. 图像目标跟踪
图像目标跟踪问题是图像视频处理中一个热门问题,因为目标的多样性,条件的复杂性,目标跟踪问题到现在还没有彻底解决。目标跟踪就是在视频图像中初始化第一帧,第一帧中勾选出了需要跟踪的目标,在后续图像帧序列中,需要找到待跟踪目标。
跟踪过程中的 光照变化、目标尺度变化、目标被遮挡、目标的形变、运动模糊、目标的快速运动、目标的旋转、目标逃离视差、背景杂波、低分辨率 等现象,都是目标跟踪问题的挑战。
2. Online Visual Tracker BenchMark
在早期,图像目标跟踪有一些公共的BenchMark,但是一直以来都没有形成统一的评价标准,各个跟踪算法都无法直接比较。直到2013年,终于出现了统一的评价标准,OTB将49段视频,50个目标整合为TB-50数据集,并且发表在2013年CVPR上,该BenchMark后来扩充到100个跟踪目标,发表在2015年TPAMI上,该BenchMark极大的促进了视频跟踪方面的研究。
Visual Tracker BenchMark, Another From Google Site 。
3. VOT
在图像分类领域,每年都有VOC比赛,同样,在图像跟踪领域,每年都有VOT比赛,通过VOT测试算法也成为了图像跟踪算法比较的方式。我再后面有一篇介绍VOT评价标准的博客,点击跳转。
4. 现代图像跟踪算法的分类
这个名词是博主创造的,因为在早年,Camshift、光流、背景差等图像跟踪算法比较流行,在静态背景条件下成功应用,大致在2008年以后,这类方法逐渐被淘汰,人们更多的研究动态背景、复杂场景环境下的图像跟踪,为了区别于原先几乎被淘汰的方法,博主将这一类算法归为现代图像跟踪算法,并做如下分类
(1)判别式:track-by-detection
判别式的图像跟踪算法将目标检测的思路用于目标跟踪。在线产生样本,在线学习,在线检测,找到目标出现概率最大的位置,然后重复这样的步骤,跟踪目标位置,这也是当下最流行的方法。
(2)产生式
产生式就是在跟踪过程中,根据跟踪结果在参数空间产生样本(而非直接从图像空间采样),然后在这些样本中寻找最优可能的目标作为跟踪结果。粒子滤波框架是最常用的产生式目标检测模型。
(3)深度学习用于图像跟踪
深度学习的方法主要分为两类,一类是使用预先训练好的深度神经网络,CNN或RNN部分不做在线训练,使用另外的算法输出目标位置,另一类是在线训练的神经网络,由神经网络输出目标位置。
目前(2016年12月),图像跟踪处于百家争鸣的状态,深度学习方法在目标跟踪方面并没有预期的凶猛,主要是体现在速度方面。在检测效果方面深度学习方法微微占优,但是速度上深度学习方法完全无法和传统方法相比较。
5. 效果评价
![]() 汇总结果的地址[持续更新]:
汇总结果的地址[持续更新]:
foolwood / benchmark_results
Visual Tracking Paper List
二、图像目标跟踪方法
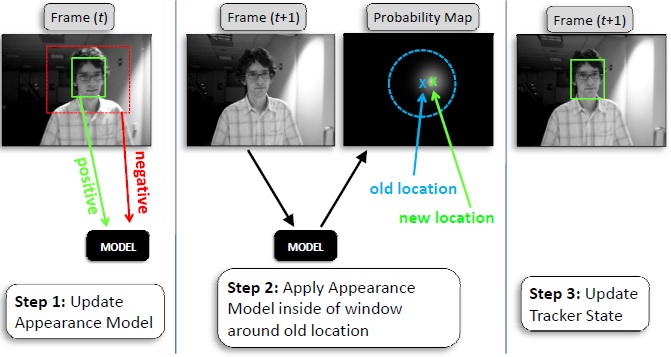
1. MIL
MIL,多实例在线学习,是一种典型的track-by-detection的方法。在MIL之前有OAB,OAB算法采用Online Adaboost算法进行在线学习,而MIL采用Online MILBoost进行在线学习,速度上更快, 并且可以抵抗遮挡。直观的感受下:
[1]. Babenko, B., M. Yang and S. Belongie. Visual tracking with online multiple instance learning. in Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on. 2009: IEEE.
[2]. Babenko, B., M. Yang and S. Belongie, Robust object tracking with online multiple instance learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011. 33(8): p. 1619-1632.
2. Struck
一般的track-by-detection在做完检测之后,会把周围的图像小块分为两类,给上正负样本标签,而Struck不这样做,Struck通过在线SVM直接输出Score。
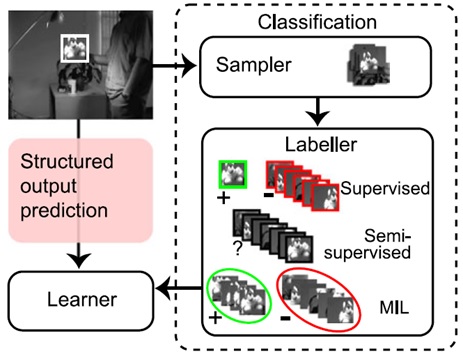
SVM的输出空间就是Score空间,每个patch块提取完特征,直接经过核函数乘以W,就可以得到Score空间下的值了。Online-SVM通过SMO进行训练,速度较快。一下是pipline,可以感受一下:
[1]. Hare, S., A. Saffari and P.H. Torr. Struck: Structured output tracking with kernels. in 2011 International Conference on Computer Vision. 2011: IEEE.
[2]. Hare, S., et al., Struck: Structured output tracking with kernels. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015. 38(10): p. 2096-2109.
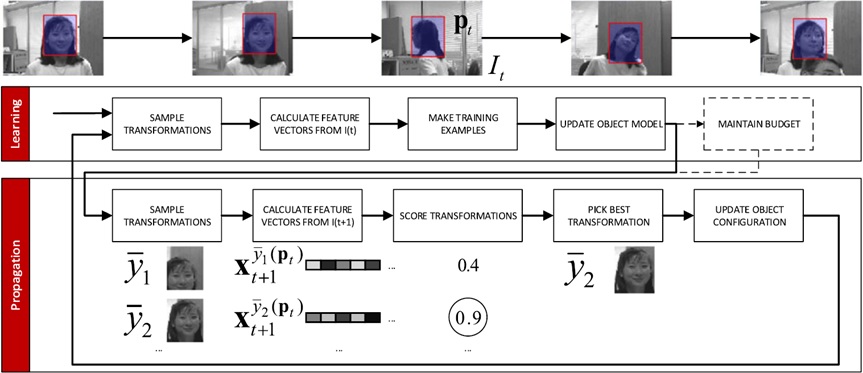
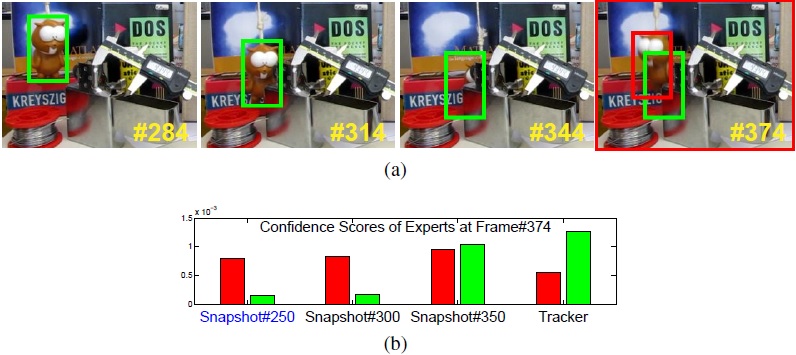
3. MEEM
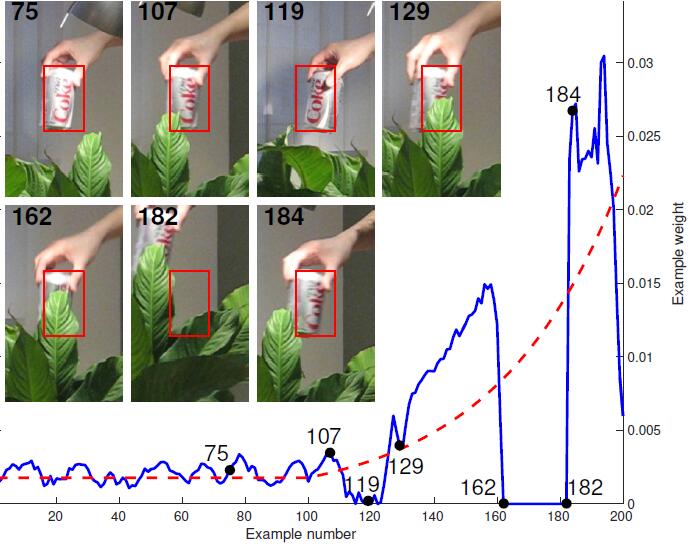
图像跟踪常常受模型漂移的影响,可能某次检测失败就会导致后续的图像帧跟踪出现误差,并且误差会不断积累。于是这篇paper提出采用一种多专家模型,维护一个固定数量的专家集合,每当来新样本时,各个专家费别给出评价,然后挑选最优的专家给出的结果。这里的专家直接来自过去某个时间段内的分类器状态。MEEM也是采用的Online-SVM。
[1]. Zhang, J., S. Ma and S. Sclaroff. MEEM: robust tracking via multiple experts using entropy minimization. in European Conference on Computer Vision. 2014: Springer.
4. KCF
KCF是很重要的算法,后面我会单独开一篇博客讲,这里简单介绍下。
相关滤波被用于图像跟踪领域始于2010年的MOSSE算法,而KCF算法将相关滤波的方法用到极致,其核心思想是利用循环矩阵乘以图片,使图像产生位移,从而得到大量样本。把位移的样本存在一个矩阵中会组成一个循环矩阵。
DFT中,循环矩阵具有一系列美好的性质,根据一系列推导,将样本空间变换到DFT空间内,可以实现大量样本的快速训练和学习。循环卷积在DFT变换后变成了矩阵元素的点积,这样就将算法的时间复杂度从O(n^3)减少到O(n*log(n)),KCF算法不仅速度快、效果好,被后来许多图像跟踪算法采用,产生了许多变种。
更细节的说,KCF通过平移产生大量样本,并且给每个样本赋予一个标签,这个标签根据离中心的距离,使用高斯分布描述,可以理解为置信度。另外,样本在做平移之前需要通过cos窗口加权,这样做的目的是避免在平移过程中,边缘太过强烈,引发不必要的麻烦。

关于DFT(离散傅里叶变换)和循环矩阵部分的推导是这个算法的核心,在Paper后面也有推导,这篇paper一定要多看几遍,后面很多方法都和这个有关。
作者主页。
[1]. Henriques, J.F., et al. Exploiting the circulant structure of tracking-by-detection with kernels. in European conference on computer vision. 2012: Springer.
[2]. Henriques, J.F., et al., High-speed tracking with kernelized correlation filters. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015. 37(3): p. 583-596.
5. SRDCF/deepSRDCF
该算法是对KCF算法的改进,因为KCF算法在截取目标区域时选取了2.5倍的padding,这就导致非目标部分也被纳入到相关滤波器的预测中了,边界部分带来的影响降低了模型的质量。
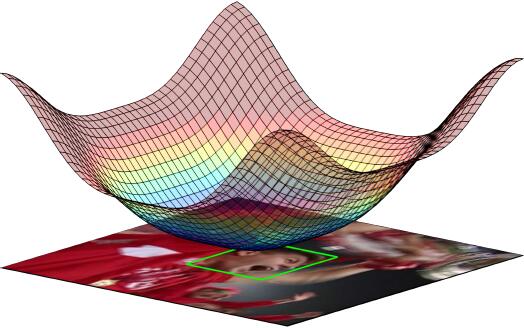
改算法通过空间正则化来提高跟踪模型的质量。通过一个高斯分布的空间惩罚因子,对不同位置加入不同权重的惩罚,这就是空间正则化。对空间正则化和输出进行可视化,在边界处的输出被明显抑制了。SRDCF将空间正则化的表达融合进loss里面,然后直接最小二乘回归就可以了,很方便。
第二篇paper,deepSRDCF就是把特征提取部分换成CNN来做,其余部分和SRDCF一样。这篇paper着重分析了使用各层特征带来的影响,发现使用第一层的特征就可以了,后面的层并不重要。这点和有些文献中的结论不一致,这条结论博主也持保留态度。
[1]. Danelljan, M., et al. Learning spatially regularized correlation filters for visual tracking. in Proceedings of the IEEE International Conference on Computer Vision. 2015.
[2]. Danelljan, M., et al. Convolutional features for correlation filter based visual tracking. in Proceedings of the IEEE International Conference on Computer Vision Workshops. 2015.
6. SRDCFdecon
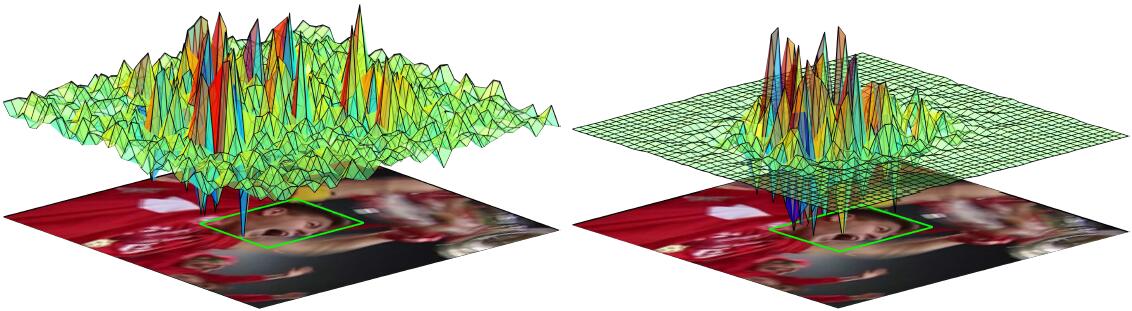
该方法是对SRDCF算法的改进,同样是为了解决样本污染问题。以往的模型学习过程在样本被遮挡时也一直在学习,这样就会导致模型被污染。之前提出过多专家的方案和boost泛化的方案,但是样本污染问题一直无法得到有效的解决。这篇paper提出的方法应该是目前解决的最好的,并且可以推广到很多方法上面,具有很高的价值。
[1]. Danelljan, M., et al. Adaptive decontamination of the training set: A unified formulation for discriminative visual tracking. 2016: CVPR.
7. Staple
Staple考虑了两种方法的结合:Hog特征+颜色直方图。因为相关滤波用Hog特征时对运动模糊和照度很鲁棒,但是对形变不够鲁棒。而颜色直方图对形变非常鲁棒。一个目标有了形变后,整个目标的颜色分布是基本不会变得。另一方面,颜色直方图对光照变化不鲁棒,这一点又可以由Hog特征进行补充。Staple同时考虑这两种特征,分成两个通道来做,形成优势互补。
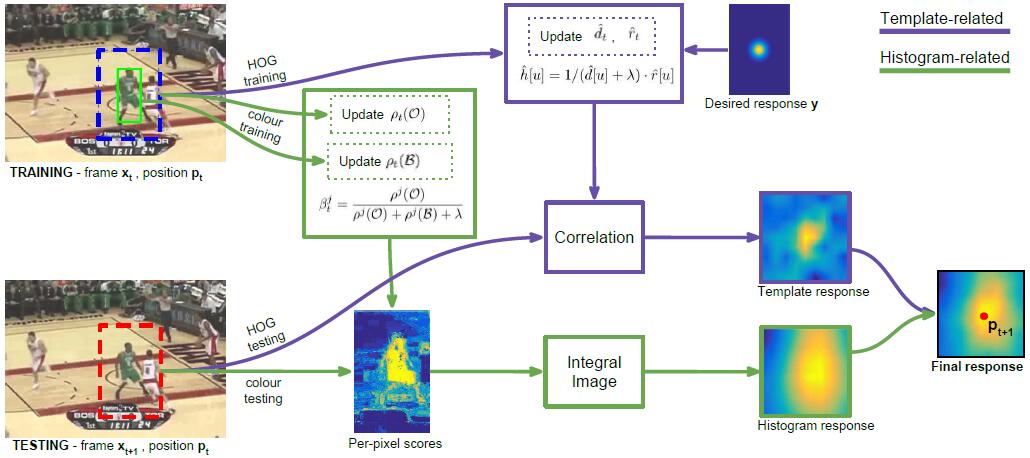
[1]. Bertinetto, L., et al. Staple: Complementary learners for real-time tracking. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
8. EBT
EBT是一种proposal方法,可与Struck等算法联合使用。在proposal阶段使用边缘特征(文中使用的是一个10维特征向量)进行全局检测,以此来应对物体运动过快的情况。

[1]. Zhu, G., F. Porikli and H. Li. Beyond local search: Tracking objects everywhere with instance-specific proposals. in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016.
三、深度学习用于目标跟踪
1. DLT
Deep Learning Tracker, DLT提出于2013年,是第一个深度学习目标跟踪算法,大体上还是粒子滤波的框架,只是采用SDAE(栈式抑噪自编码器)提取特征。下乳就是SDAE的结构,SDAE是预先训练好的,不需要在线学习,然后后面跟着粒子滤波的一套东西。
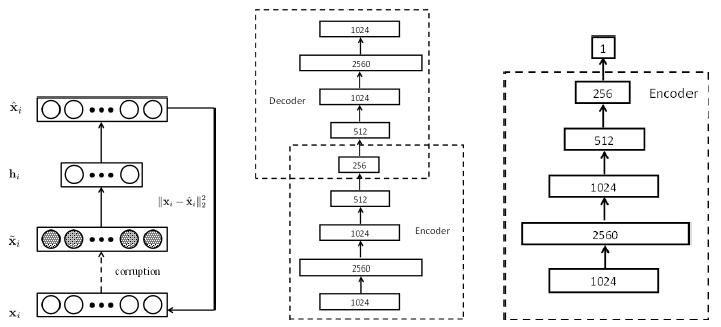
[1]. Wang, N. and D. Yeung. Learning a deep compact image representation for visual tracking. in Advances in neural information processing systems. 2013.
2. HDCF
这篇Paper和后面的HDT算法有着很大关系,如果不是速度原因,HDCF算法将会是我相当推崇的,其思想简单,就是通过预先训练好的深度神经网络来提取特征,利用多个层的特征来共同定位,浅层特征位置准确,深层特征包含语义信息,在线学习部分当然是使用当下最受欢迎,又快又好又简洁的Correlation Filter了。这种思想其实是相当不错的,只是用了深度学习就不得不面对庞大的参数和GPU加速处理。
博主测试了原文中的算法,在博主的GTX1070上跑到23fps,如果只用CPU的话6600k超频到4.24GHz也只有6fps,远未达到实时要求。另外,博主修改了下代码,分别只使用Conv3、Conv4、Conv5层,发现准确率下降的并不多。博主在想是否一定要这么多层的特征呢?这个问题目前是存在争论的,不过介绍这篇Paper是为了介绍接下来一篇Paper的。
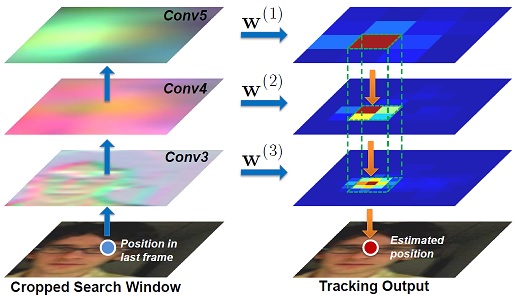
[1]. Ma, C., et al. Hierarchical convolutional features for visual tracking. in Proceedings of the IEEE International Conference on Computer Vision. 2015.
3. HDT
Hedged Deep Tracking的缩写,上面一篇Paper提到,既然深层特征包含语义信息,浅层特征包含位置信息,那么如何将这些特征有效的结合起来呢?Hedge就是本文利用的方法,每一层特征训练出来的Correlation Filter作为一个弱分类器,通过Hedge的方法,平衡各个结果,给出预测位置(其实就是给每个层的位置结果一个权重,然后加权平均,主要问题是权重怎么算,Paper就是讲这个了)。
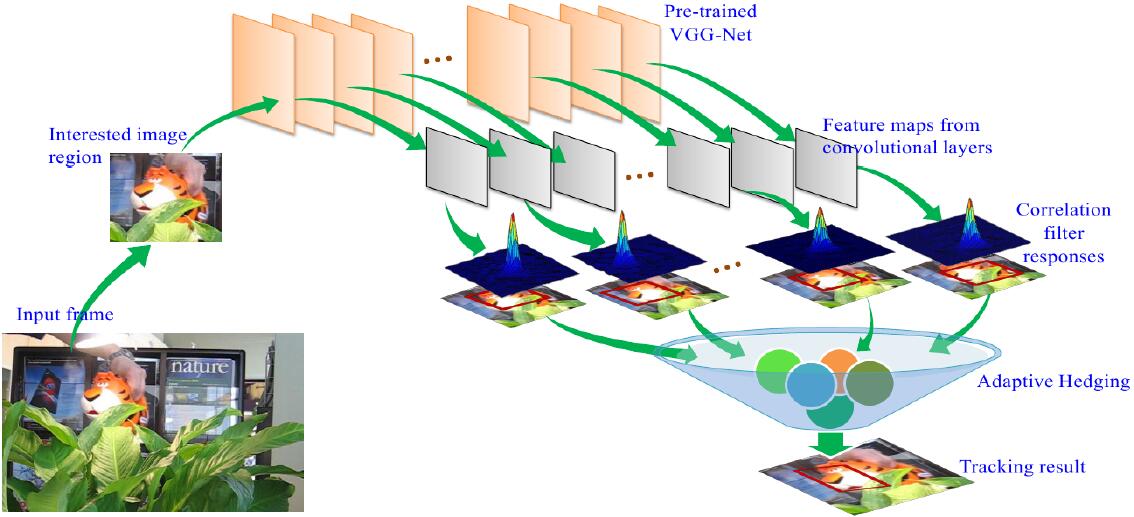
[1]. Qi, Y., et al. Hedged Deep Tracking. in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. 2016.
4. STCT
因为跟踪算法需要在线学习,深度学习采用预训练的方式训练一个网络CNN-E提取特征,然后分层的特征再送到另一个网络CNN-A里面训练,每一层训练得到一个弱分类器,然后使用类似boost方法在顶端建立一个SPN网络预测结果,预测loss小的话就作为正样本来更新网络实现在线跟踪。

[1]. Wang, L., et al. Stct: Sequentially training convolutional networks for visual tracking. in Computer Vision and Pattern Recognition (CVPR), 2016 IEEE Conference on. 2016.
5. C-COT
C-COT和TCNN是VOT-16中表现最好的算法。C-COT、后面的ECO都出自Danelljan,也就是前面SRDCF系列、DSST系列的作者。从越来越复杂的数学表达可以看出Danelljan对DCF的研究已经非常深入了。
由于传统DCF算法在目标尺度和分辨率方面适应性太差,而考虑到CNN深层特征的语义表达能力,想法就是将多尺度和深层语义信息结合起来。根据不同空间分辨率的响应,在频域进行插值,得到连续空间分辨率的响应图,通过高斯赛德尔方法迭代求得最佳位置和尺度。这样成功的对抗了DCF在目标尺度变化时引起的模型漂移。在实践中使用了原始彩色图像三个通道和CNN两个特征层,五种分辨率(0.98,0.99,1.0,1.1,1.2),分别学习这些层的卷积滤波器(下图第二列),然后将它们综合起来,得到最后的位置和尺度,因为是插值方式得到的,所以空间和尺度都是连续的。至于更多细节,就是其采用了样本净化技术(之前提到过的)、SRDCF等。由于C-COT算法在CPU上速度大概1fps,所以后面的ECO算法主要是进行速度的优化。

[1]. Danelljan, M., et al. Beyond correlation filters: Learning continuous convolution operators for visual tracking. in European Conference on Computer Vision. 2016: Springer.
6. ECO
ECO是在C-COT基础上的改进,要知道一个实用的算法不光要有好的性能,还要有好的实时性。ECO算法在效果比C-COT好的情况下,在CPU上可以到达60fps的高速,可以说是目前(2017年4月)最牛的算法了。
ECO算法的主要思想有三点,一是通过提出的卷积因式分解操作来降低C-COT提取出特征的维度,二是通过样本分组来归类训练集,一方面避免相同样本重复训练引起的过拟合,另一方面提高速度,三是在训练过程中模型每隔N帧更新一次,而不是每帧更新,这主要是考虑到相邻样本有着相同的表现,而更新过程太过耗时。
这篇论文已经被CVPR17接受了,下面的参考文献没有指向CVPR17
[1]. Danelljan, M., et al., ECO: Efficient Convolution Operators for Tracking. arXiv preprint arXiv:1611.09224, 2016.
啊,这篇介绍前前后后拖了两个多月,收个尾吧==0.0==
OK,See You Next Chapter!
其实我很好奇摩托车那个视频,那个能一直跟上的红色的tracker到底是什么算法,莫非是groundtruth?
HDCF算法,我当时也是被这个图吸引了
博主这个综述表达的很清晰,超赞!
请问博主,benchmark_results-master中的图是用什么软件画的啊?
博主你好- -最近在做追踪相关的东西,看了你的文章感觉了解了很多。想和你更深入地交流一下- – 有些问题想要请教
博主您好,我最近也在研究目标跟踪的深度学习方向。现已研究速度比较快的goturn代码,想必您肯定是了解过。它这个算法里面用到了alov300+数据集做训练集,您对这个数据集有何见解,而且我主要的问题就是这个数据集有一点和vot2016不一样。比如它第一个短视频有356张图片(帧),而对应的gt文件里仅仅有十几行坐标(每行一个数字+8个坐标)。所以这样我就搞不懂了。坐标行数远比图片数少,而且每行第一个数字算起来还是等差的。这与vot2016数据集大不相同。vot2016数据集每张图片都对应一行坐标,所以十分好用。
博主这个综述表达的很清晰,超赞!
请问博主,benchmark_results-master中的图是用什么软件画的啊?
这个图不是我画的,git仓库里原来有画图的代码,好像是用python画的。
超赞!博主可以合作吗?我公司现有产品嵌入你的跟踪算法,欢迎加入QQ137427423