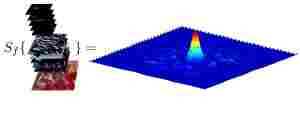
C-COT算法是DCF(KCF)算法的又一重要演进算法,该算法在VOT-16上取得了不错的成绩。C-COT使用深度神经网络VGG-net提取特征,通过立方插值,将不同分辨率的特征图插值到连续空间域,再应用Hessian矩阵可以求得亚像素精度的目标位置(就和SURF、SIFT里面获取亚像素精度特征点的思想类似)。确定插值方程之后,还解决了在连续空间域进行训练的问题。C-COT的代码结合了deepSRDCF、SRDCFdeno的样本进化,和C-COT进行插值等算法。这里面博主也有许多地方没有理解,毕竟Martin的数学功底大家都明白,这里就当时写一下自己的理解了。文章代码
目标跟踪
图像跟踪(九)FCNT语义跟踪
刚有一个idea,用语义分割来做图像跟踪,搜了一下发现已经有人做过了,细细的看了下Paper,和自己相当还不一样。FCN是深度学习语义分割的鼻祖,而这片Paper的名字叫做FCNT,看了之后发现我误会了,此FCN非彼FCN,由于是比较早的算法了,性能和MEEM处于同一层次,不过考虑到这是深度学习方法用于跟踪的重要实践,还是做个笔记好了。
博主认为图像跟踪过程的本质就是语义的跟踪(我是这么理解的),所以,使用语义分割来完成图像跟踪是自然而然想到的。事实上深度学习用于图像跟踪,也就是利用了其深层特征中的语义信息。这篇博客就主要介绍这篇文献:Visual Tracking with Fully Convolutional Networks。
目标跟踪VOT2016 BenchMark评价标准介绍
现在比较流行的跟踪Benckmark有OTB、VOT、KITTI-tracking,之前的算法测试都进行在OTB(Visual Tracker Benckmark)上,考虑到现在VOT的流行程度不亚于OTB,并且VOT每一年都会有更新。VOT16并没有更新图像数据,而是更新了标注的方法。这篇博客主要介绍VOT的评价方法,会结合实验数据介绍官方SDK的代码。
图像跟踪(八)结构化SVM:Struck与SSVM

结构化SVM方法用于跟踪,带来了速度和效果的提升。之前我有一篇讲Struck的博客,但是感觉这个算法没有讲透彻,决定捎带上SSVM再开一篇争取把问题讲清楚。结构化SVM和传统SVM方法相比,有着强大的判别能力,这篇博客将带大家一探结构化SVM在tracking上的应用。
同样是结构化SVM方法,Struck在2015年Pami中进一步加入尺度估计和GPU加速,使得Struck也具有相当的实用性。SSVM与Struck都是结构化预测框架,主要不同在于Struck采用SMO优化迭代求解,而SSVM采用DCD方法求闭式解,使得SSVM在速度上体现优势。

Object Visual Tracker Benchmark 使用教程

2013年Object Visual Tracker Benchmark的提出是视频图像跟踪另一的大事件,自此视频跟踪领域有了公认的Benchmark,跟踪方面的研究与以前已经完全不一样的。虽然下载源码,摸索之后都可以看懂,但是博主还是想系统的介绍其中的工具。官方的SDK可以极大的帮助我们评估算法,产生一些可以直接出现在Paper上的图表。
这篇博客主要介绍如何Visual Tracker Benchmark 中提供的Matlab代码,希望能有所帮助。Python的可以看那些开源的demo,差不多一样的思路。
图像跟踪(六)SRDCFdeno算法:样本净化

SRDCFdeno算法的论文中提出了一种净化样本的方法,虽然挂了SRDCF的名字,但是SRDCF只是BaseLine。这种样本净化的方法可推广性非常强,因为把样本权重融合进了Loss函数,直接在更新样本的时候更新其权重,相对于多专家系统的方法,我更推荐使用这种方法来净化样本。
图像跟踪中像素误差、重叠率、AUC的计算:Matlab实现
![]() 视频图像跟踪算法的评估常常需要计算重叠率(Overlap Rate)、像素误差(Pixel Error)还有AUC(Area Under Curve)。这些技术指标都比较好理解,如果不理解的话可以参见我之前的博客。这篇博客主要就是贴上Matlab的代码,使用Matlab计算这些参数,并绘制出曲线图。
视频图像跟踪算法的评估常常需要计算重叠率(Overlap Rate)、像素误差(Pixel Error)还有AUC(Area Under Curve)。这些技术指标都比较好理解,如果不理解的话可以参见我之前的博客。这篇博客主要就是贴上Matlab的代码,使用Matlab计算这些参数,并绘制出曲线图。
如果你是想放在Paper中的话,可以下载Visual Track BenchMark中提供的代码,可以画出和Paper上一样的样式,这篇博客只是博主对单个视频自己写的小demo,便于自己分析实验的,如果要在Paper使用还需要做样式的修改。
图像跟踪(五)SRDCF的数学推导

SRDCF是在DCF/KCF的基础上,对目标函数正则化项进行改进,使用空间正则化惩罚来改进效果。SRDCF的Paper上关于数学推导部分非常多,但是其中仍有许多细节影响我们阅读代码。本来自己做了一份ppt,但是Google了下,发现有作者本人presentation的ppt关于细节部分非常详尽,于是直接用作者的ppt了,下面开始学习吧。
图像跟踪(四)KCF算法
KCF算法是目标跟踪领域最重要的算法(之一),为什么敢说最重要呢?KCF的特点:实现简洁、效果好、速度快。并且博主认为,KCF算法扣住了跟踪问题的一个难点,就是样本过少,通过循环矩阵位移产生大量样本来解决问题,并且通过离散傅里叶变换的推导,在频域计算速度极快。总之,KCF设计非常精妙,以至于现在许多跟踪算法都以KCF为基石来构建。
图像跟踪(三)MEEM算法

在长时间视频目标跟踪过程中,由于遮挡、形变、旋转等原因,常常发生样本被污染的情况,MEEM算法通过多专家模型来解决样本被污染的问题。MEEM算法的核心思想是,对当前帧应用多个检测器,根据多个预测值来判断可信,这多个检测器就是从过去储存的分类器中选取。是一种典型的多专家模型
应对样本污染,博主个人不是很推荐这种方法,毕竟解法偏暴力,个人比较推崇denoSRDCF中处理样本污染的方法,实际上效果也是更好的。不过该算法MEEM也是很经典的多专家模型,不妨学习一下。
图像跟踪(二)Struck算法

Struck算法提出于2011年,同样是一种track-by-detection的方法,与其它算法相比,它具有如下特点:使用的是Online-SVM,不直接给样本正负标签,文中称之为Structured Output Prediction。受益于SVM的拟合能力和速度,该算法是当时的state-of-the-art,并且效果和速度都优于其它算法。下面就来详细介绍。
图像跟踪(一)MIL多实例在线学习算法
最近看了一些图像跟踪的Paper,于是图像跟踪系列开更了。开篇介绍的是一种经典的图像跟踪算法MIL(多实例在线学习),提出于2009年,该算法将track-by-detection推向了新高潮。
2006年以来,使用目标检测的方法来处理图像跟踪问题取得了良好的效果,这种方法处理图像跟踪问题相对于处理目标检测问题是有所不同的,处理目标检测问题要求使用的样本量很少,并且实时性要求较高,也就是需要在线学习,快速检测。MIL算法就是在目标周围选取正负样本,通过一种多实例在线学习的方法,训练弱分类器,并且选择合适的特征进行组合,形成强分类器。由于MILBoost的特点,该算法速度较快,并具备抗遮挡能力。
视频图像跟踪算法综述
 图像跟踪一直都是计算机视觉领域的难题,事先知道第一帧中的目标位置,然后需要在后续帧中找到目标。先验知识少,目标被遮挡、目标消失、运动模糊、目标和环境的剧烈变化、目标的高速运动、相机的抖动都会对目标跟踪造成影响,图像跟踪一直都是CV领域的难题。
图像跟踪一直都是计算机视觉领域的难题,事先知道第一帧中的目标位置,然后需要在后续帧中找到目标。先验知识少,目标被遮挡、目标消失、运动模糊、目标和环境的剧烈变化、目标的高速运动、相机的抖动都会对目标跟踪造成影响,图像跟踪一直都是CV领域的难题。
深度学习用于图像跟踪有两大要解决的问题,一是图像跟踪一般使用在线学习,很难提供大量样本集,二是深度学习使用CNN时,由于卷积池化,最后一层的输出丢失了位置信息,而图像跟踪就是要输出目标的位置。
2013年以来,深度学习开始用于目标跟踪,并且为这些问题提供了一些解决思路。这篇博客首先阐述图像跟踪今年来的研究进展,然后再介绍深度学习用于图像跟踪近年来的研究,最后附上一些学习资料和相关网站。
目标跟踪的评价指标(OTB与VOT)
目标识别的评价指标主要有ROC曲线,missrate(MR,其实就是FALSE Positive)、FPPI、FPPW等。单图像跟踪的评价指标主要有两个,一个是pixel error,一般是算中心距离,另一个是overlap rate,区域重叠率,用重叠区域除以两个矩形所占的总面积Aoverlap /(A1+A2-Aoverlap),常常用pixel error绘制帧误差曲线,用重叠率绘制误差曲线。除此之外,还有针对多目标图像跟踪的评价指标。在VOT中,目标跟踪的评价指标又多了EOA和EOF图,这篇博客都会介绍。