视频插帧是计算机视觉许多应用中的一个传统问题,splatting transformer network 技术已被广泛用于两幅图像之间的新图像合成:非监督深度估计,非监督光流预测,光流预测,新视角合成,视频插帧,视频增强,视频编辑、视频压缩、去除视频运动模糊中。视频插帧方法被分为flow-based、kernel-based、phase-based。这些方法都是估计出两帧之间的光流场,一般通过warp前一帧来得到中间帧。视频插帧在某些场景下特别困难,比如场景和物体在不断运动和变化,或者存在遮挡时,插帧问题会同时存在多个解。
这篇博客介绍CVPR2020的一篇论文,是flow-based的方法。这篇文章主要贡献有两个,一是使用了softmax splatting的方法来处理不同源像素warp之后到同一点的问题,二是使用了特征金字塔,应该是对大位移有更鲁棒。
一、参考资料
主页:http://sniklaus.com/papers/softsplat
论文:https://arxiv.org/abs/2003.05534
代码:https://github.com/sniklaus/softmax-splatting
二、softmax splatting
论文提出了使用softermax splatting来做前向warp,并使用另一种方式处理了不同源像素映射到同一点时的问题,论文中定义了四个运算符,summation splatting 、average splatting、linear splatting、softmax splatting,各运算符表述如下:

- summation splatting,就是用bilinear kernel直接采样对应映射点的值,将前一帧和后一帧的映射值求和相加。
- averate splatting,顾名思义就是求取平均,在运动区域前景和背景重叠时会产生artifacts。
- linear splatting,引入了一个mask Z,mask Z 中包含了像素深度信息,运动的前景有较高权重,不动较远的背景权重较低,这样artifacts就弱一些。
- softmax splatting,为了更好的根据mask Z分割出运动重叠区域,对Z进行softmax计算,然后再做end-to-end trainning就可以较少很多artifacts。
- Mask Z,和深度有关,但是计算像素的深度开销太高了,显然我们不需要也不可能精确知道每个pixel的depth是多少,于是我们使用亮度恒常性来判断遮挡就行,对背景进行warp之后相减,来得到遮挡区域的mask Z。论文中做的更细致,使用了一个神经网络来refine Z

三、算法流程
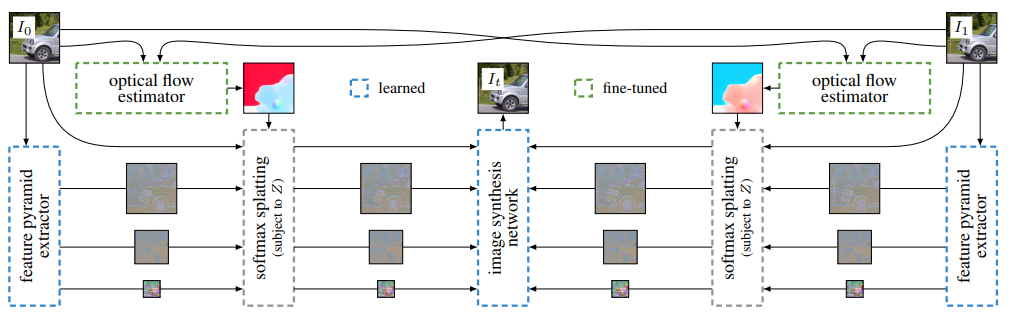
这个插帧算法的框架如上图,计算大致分为几部:
- 1. 输入是两帧图像,计算帧间光流。光流估计使用的是作者fine-tune之后的PWC-Net,作者说FlowNet2和FlowNet也具有比较好的效果。
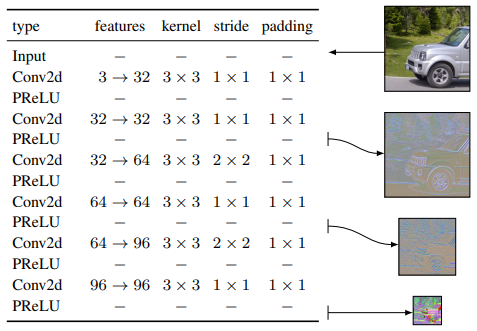
- 2. 计算特征金字塔 。特征金字塔提取使用的是下图所示的网络,右边的可视化结果是使用PCA得到的。
- 3. 把光流和特征金字塔在Z的约束下进行softmax splatting。Mask Z也使用了一个小的三层U-Net来refine。整个过程还是端到端的训练。
- 4. 将特征金字塔和原始图像一起送入图像合成网络,生成插帧后的图像。文正介绍这个网络特点的时候,也是表示监督纹理抽取和特征金字塔对预测结果很重要。图像生成网络使用了一种GridNet架构的网络(酷似U-Net)。作者还提到,为了避免棋盘格状的artifacts,作者修改了Niklaus的网络(这个要对比下pytorch的源码)。
最终训练好的网络在TitanX上跑720p视频能到0.357s,在1080p视频上能跑道0.807s,参数大小为31M
四、实验结果
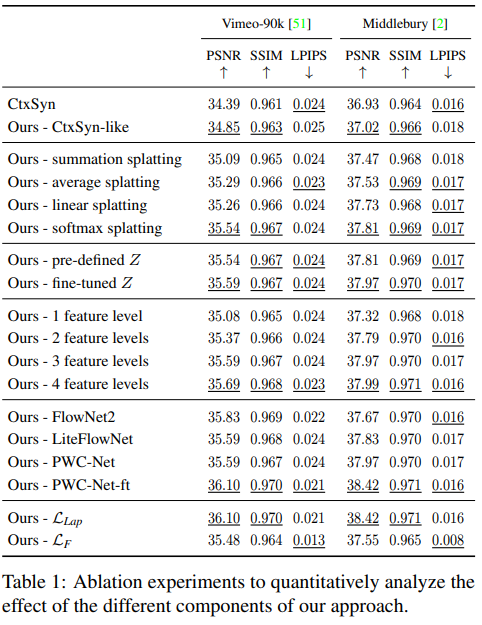
醉着公布的数据,看最好使用fine-tuned Z 、 4 feature levels、fine-tuned PWC-Net、Loss使用Llap
作者用一张可视化的图表示,特征金字塔在大位移场景下比较重要,效果更好。

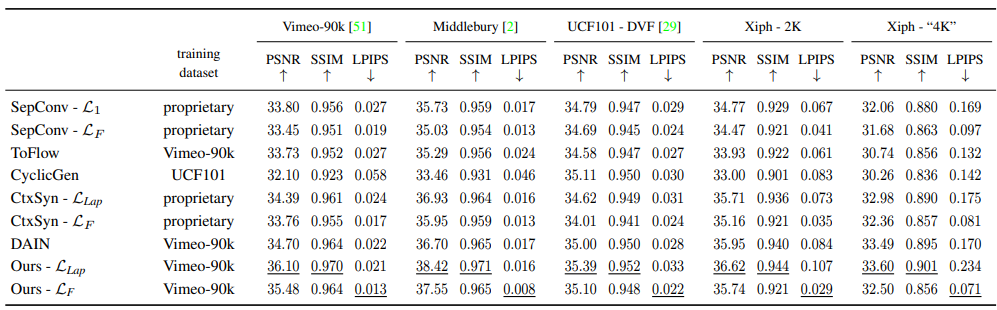
最后是一些横向方法的对比
附录一:Niklaus的Paper
论文大量介绍和这篇文章的不同,可以看出流程是以Niklaus Paper里面的流程为基础的,这里挂一下这篇paper: Context-Aware Synthesis for Video Frame Interpolation
更多的视频插帧方法可以在:Paper With Code 中查看
附录二:Splatting
在介绍论文之后,我们再了解下splatting(抛雪球):(这部分本身和论文关系不密切,主要是文章标题中出现了这个名字,拓展一下)
splatting算法,也称为足迹法,最初由Westover提出,以物体工件为序的直接体绘制算法。该方法把数据场中每个体素看作一个能量源,当每个体素投向图像平面时,用以体素的投影点为中心的重建核将体素的能量扩散到图像像素上。这个过程中,用一个称为足迹的函数计算每一体素投影的影响范围,用高斯函数定义点或者小区域像素的强度分布,从而计算出其对图像的总体贡献,并加以合成,形成最后的图像。由于这个方法模仿了雪球被抛到墙壁上所留下的一个扩散状痕迹的现象,因而取名为“抛雪球法”。
你好,我不太明白这里的,如何使用亮度恒常性来判断遮挡?
用F0->1的光流将I1重新warp回I0然后和原始的I0做差只是残差而已,残差如何能代表遮挡呢?
我理解亮度恒常性就是像素亮度差大于噪声的时候就判定成遮挡了
遮挡Z是softmax splatting时候使用的,train 图像合成网络的时候输入是没有遮挡的
大神你好,想问下您是如何理解对提取不同尺度特征作softmax splatting的,因为feature map的大小逐步减小,无法match光流和mask Z的大小,图像一旦缩小,点是对不上的。您知道对于feature是怎么作splatting的吗?谢谢