曝光图像融合通常的应用场景是HDR,传统的图像融合算法分为两类,一类是像素级的图像融合,通过将图像不同频段分离,在像素层及进行融合,另一类是基于变换域的方法,把图像变换到频率、小波域进行图像融合,最后再反变换回来,有些类似于同态滤波的形式。博主之前介绍过Mertens Exposure Fusion、Pyramid Blending、Possion Blending等都是经典的传统图像融合算法。
传统图像融合算法在融合曝光程度差异小的图像时非常有效,但是图像之间曝光差异程度大的时候融合结果就会出现瑕疵,事实上极端曝光情况下的图像融合具有非常大的挑战,这篇博客介绍一种基于无监督的图片融合算法DeepFuse,看名字就知道这是一种CNN的算法实现。
论文地址:https://arxiv.org/abs/1712.07384
我们掏出CNN分析三板斧:structure、loss、data
网络结构
首先,网络的输入图像是YCbCr,因为曝光融合主要是图像亮度的融合,所以对Y使用DeepFuse CNN进行融合,CbCr使用加权融合。自然论文的核心就是DeepFuse CNN了。
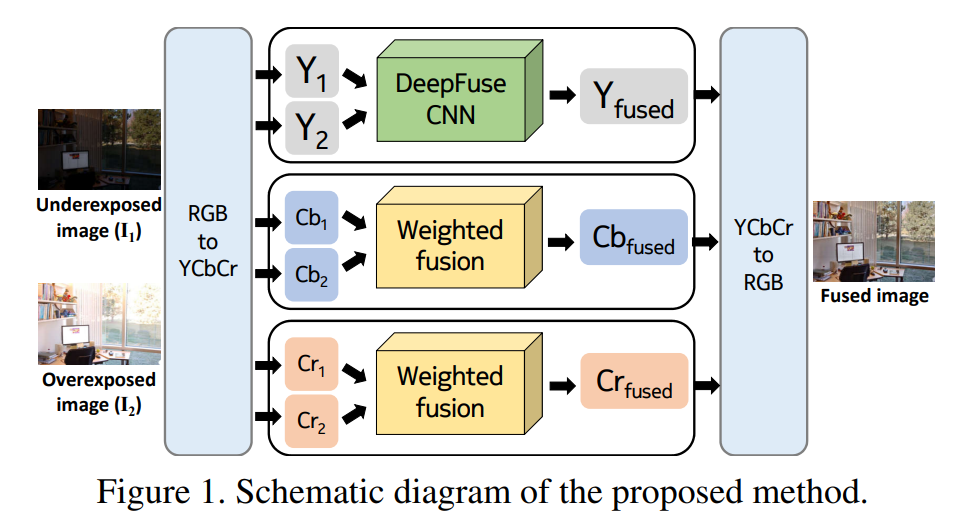
然后我们看网络结构图,网络结构包含三个层:特征提取层、特征融合层、图像重建层
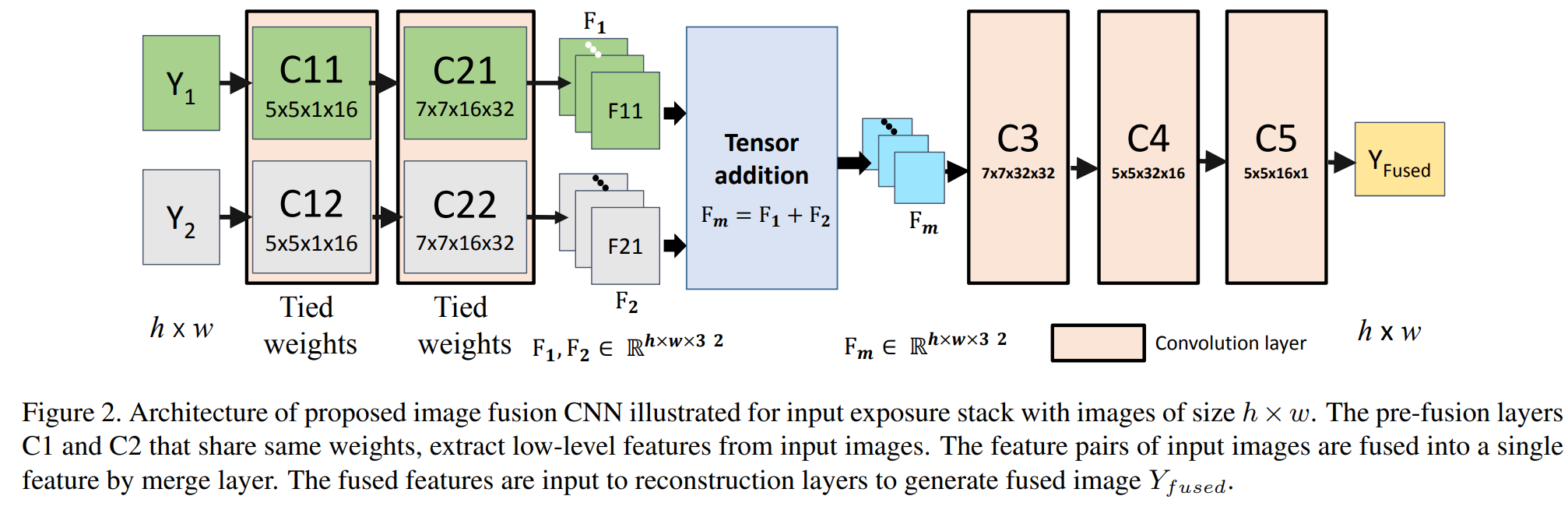
特征提取层(C11\C21 和 C12\C22)通过5×5卷积核来提取低层特征,C11\C21 C12\C22分别采用共同的权重信息,两张输入图像各产生32张特征图。特征融合层直接将这些特征的权重相加。图像重建层由三个卷积层组成,特征融合层的32通道图像最终被融合到一个通道,该网络使用MEF SSIM loss训练,
论文中说,(捆绑权重)这种结构的优势有三:
- 没有必要分离图像权重,捆绑权重可以满足需求(比组合特征有更好的性能,比,级联权重需要更多迭代次数,捆绑权重可以更有效的学习到亮度不变特征)
- 可学习的卷积核数量减少了一半
- 网络参数数量较少,收敛速度很快
文章着重强调了loss函数,DeepFuse CNN采用MEF SSIM loss,使用这种loss可以在无监督的时候取得较好的效果,这部分可以查阅原文。
训练过程
论文使用标准三脚架拍摄曝光堆栈,图像间具有±2ev的差异,使用64×64的30000个patches进行训练,迭代周期100次,学习率10^-4,最终收敛。
特征融合结果
因为两张图ev差异太大,达到4ev,所以大多数算法都挂掉了,因为CNN本来train的就是ev差别比较大的,在该类型的一些数据集上更好表现也可以理解。

这里博主认为这里有必要把其它算法ev_step<2ev的正常的效果也拿出来,这样更容易发现CNN算法的问题(瑕疵、丢细节之类的),毕竟使用曝光差这么多的数据,不足以体现其它算法的极致效果。不过这里也确实证明在大ev间隔时候cnn更有效。
DenseFuse
DeepFuse发布于2017年,另外还有一个结构类似的网络,可以算作对DeepFuse的改进,DenseFuse:
hli1221 / imagefusion_densefuse
DenseFuse (IEEE TIP 2019, Highly Cited Paper) - Python 3.6, TensorFlow 1.8.0
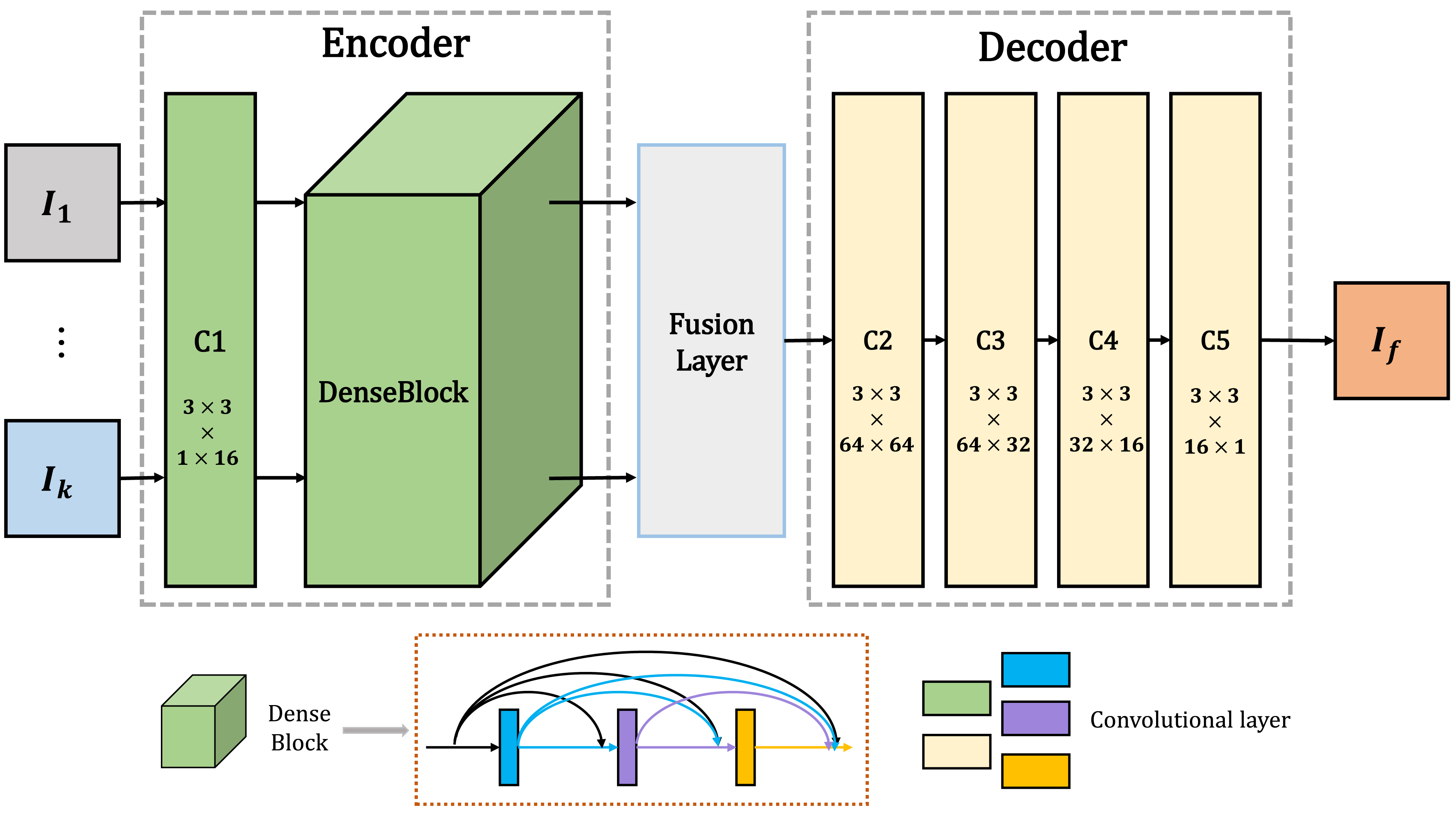
有一片知乎讲了这两者的对比,博主就不摘抄了:融合算法-DeepFuse,DenseFuse
DeepFuse和DenseFuse网络结构都比较简单,博主有空再看下DenseFuse的新花样。