QAT(Quantization Aware Training)量化感知训练是神经网络优化模型容量的重要方法,关系到模型精度和性能。pytorch对模型量化支持有三种方式:模型训练完毕后的动态量化、模型训练完毕后的静态量化、模型训练中开启量化QAT。这篇博客主要基于pytorh介绍QAT的基本概念。
参考链接:https://zhuanlan.zhihu.com/p/164901397
参考链接:https://jishuin.proginn.com/p/763bfbd3aec8
在介绍QAT时我们先介绍下面几个概念:
网络推理:推理是指将一个预先训练好的神经网络模型部署到实际业务场景中,衡量推理性能的重要指标包括延迟(latency)和吞吐量(throughput)。延迟是指完成一次预测所需的时间,吞吐量是指单位时间内处理数据的数量。模型量化是加速神经网络推理的有效手段。
动态量化:网络在前向推理时动态量化float32类型的输入
对称量化:通过除以一个缩放因子delta,将原始浮点数量化到一个较小的区间[-127,127]
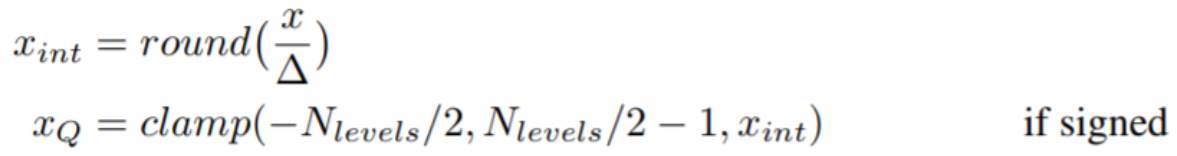
这里你有个trick,就是用[-127,127]区间可以避免后续操作溢出风险,所以不会使用[-128,127]
这里delta怎么取呢?公式如下
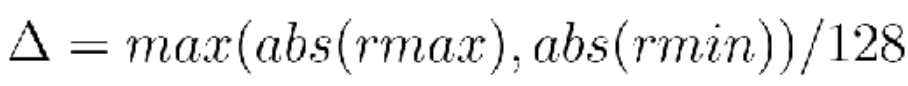
非对称量化:相比于对称量化多了一个零点偏移,可以选择量化到[-128,127]或者[0,255]。量化过程为 缩放、取整、零点偏移、溢出保护,如下所示:

缩放系数和零点偏移计算公式如下:
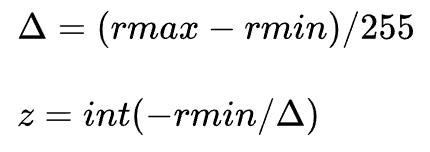
所以量化过程实际上是通过统计四元组(min_val, max_val, qmin, qmax)来计算两个量化参数:scale和zero_point。
后训练静态量化:
需要把训练集和训练集分布类似的数据喂给模型,然后通过每个op输入的分布特点来计算activation的量化参数(scale和zp)——称之为Calibration。静态量化包含有post process,就是在forward之后的后处理。静态量化的前向推理过程自始至终都是INT计算,activation需要确保一个op的输出符合下一个op的输入。
训练模拟量化:
在网络模型量化后,权重和激活值的计算方法现在不一样了。我们来模拟一下这个过程
我们可以用下面这段代码来模拟float32转int8,注意的是下面代码只验证算法有效性,不是真实的板端代码
class Quantizer(nn.Module):
def __init__(self, bits, range_tracker):
super().__init__()
self.bits = bits
self.range_tracker = range_tracker
self.register_buffer('scale', None) # 量化比例因子
self.register_buffer('zero_point', None) # 量化零点
def update_params(self):
raise NotImplementedError
# 量化
def quantize(self, input):
output = input * self.scale - self.zero_point
return output
def round(self, input):
output = Round.apply(input)
return output
# 截断
def clamp(self, input):
output = torch.clamp(input, self.min_val, self.max_val)
return output
# 反量化
def dequantize(self, input):
output = (input + self.zero_point) / self.scale
return output
def forward(self, input):
if self.bits == 32:
output = input
elif self.bits == 1:
print('!Binary quantization is not supported !')
assert self.bits != 1
else:
self.range_tracker(input)
self.update_params()
output = self.quantize(input) # 量化
output = self.round(output)
output = self.clamp(output) # 截断
output = self.dequantize(output)# 反量化
return output
# ********************* range_trackers(范围统计器,统计量化前范围) *********************
class RangeTracker(nn.Module):
def __init__(self, q_level):
super().__init__()
self.q_level = q_level
def update_range(self, min_val, max_val):
raise NotImplementedError
@torch.no_grad()
def forward(self, input):
if self.q_level == 'L': # A,min_max_shape=(1, 1, 1, 1),layer级
min_val = torch.min(input)
max_val = torch.max(input)
elif self.q_level == 'C': # W,min_max_shape=(N, 1, 1, 1),channel级
min_val = torch.min(torch.min(torch.min(input, 3, keepdim=True)[0], 2, keepdim=True)[0], 1, keepdim=True)[0]
max_val = torch.max(torch.max(torch.max(input, 3, keepdim=True)[0], 2, keepdim=True)[0], 1, keepdim=True)[0]
self.update_range(min_val, max_val)
class GlobalRangeTracker(RangeTracker): # W,min_max_shape=(N, 1, 1, 1),channel级,取本次和之前相比的min_max —— (N, C, W, H)
def __init__(self, q_level, out_channels):
super().__init__(q_level)
self.register_buffer('min_val', torch.zeros(out_channels, 1, 1, 1))
self.register_buffer('max_val', torch.zeros(out_channels, 1, 1, 1))
self.register_buffer('first_w', torch.zeros(1))
def update_range(self, min_val, max_val):
temp_minval = self.min_val
temp_maxval = self.max_val
if self.first_w == 0:
self.first_w.add_(1)
self.min_val.add_(min_val)
self.max_val.add_(max_val)
else:
self.min_val.add_(-temp_minval).add_(torch.min(temp_minval, min_val))
self.max_val.add_(-temp_maxval).add_(torch.max(temp_maxval, max_val))
class AveragedRangeTracker(RangeTracker): # A,min_max_shape=(1, 1, 1, 1),layer级,取running_min_max —— (N, C, W, H)
def __init__(self, q_level, momentum=0.1):
super().__init__(q_level)
self.momentum = momentum
self.register_buffer('min_val', torch.zeros(1))
self.register_buffer('max_val', torch.zeros(1))
self.register_buffer('first_a', torch.zeros(1))
def update_range(self, min_val, max_val):
if self.first_a == 0:
self.first_a.add_(1)
self.min_val.add_(min_val)
self.max_val.add_(max_val)
else:
self.min_val.mul_(1 - self.momentum).add_(min_val * self.momentum)
self.max_val.mul_(1 - self.momentum).add_(max_val * self.momentum)
另外,由于卷积层后面经常会接一个BN层,并且在前向推理时为了加速经常把BN层的参数融合到卷积层的参数中,所以训练模拟量化也要按照这个流程,把BN层参数和卷积层参数融合:

不融合BN时,量化卷积如下:
# ********************* 量化卷积(同时量化A/W,并做卷积) *********************
class Conv2d_Q(nn.Conv2d):
def __init__(
self,
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True,
a_bits=8,
w_bits=8,
q_type=1,
first_layer=0,
):
super().__init__(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=bias
)
# 实例化量化器(A-layer级,W-channel级)
if q_type == 0:
self.activation_quantizer = SymmetricQuantizer(bits=a_bits, range_tracker=AveragedRangeTracker(q_level='L'))
self.weight_quantizer = SymmetricQuantizer(bits=w_bits, range_tracker=GlobalRangeTracker(q_level='C', out_channels=out_channels))
else:
self.activation_quantizer = AsymmetricQuantizer(bits=a_bits, range_tracker=AveragedRangeTracker(q_level='L'))
self.weight_quantizer = AsymmetricQuantizer(bits=w_bits, range_tracker=GlobalRangeTracker(q_level='C', out_channels=out_channels))
self.first_layer = first_layer
def forward(self, input):
# 量化A和W
if not self.first_layer:
input = self.activation_quantizer(input)
q_input = input
q_weight = self.weight_quantizer(self.weight)
# 量化卷积
output = F.conv2d(
input=q_input,
weight=q_weight,
bias=self.bias,
stride=self.stride,
padding=self.padding,
dilation=self.dilation,
groups=self.groups
)
return output
import torch
import torch.nn as nn
import torch.nn.functional as F
from .util_wqaq import Conv2d_Q, BNFold_Conv2d_Q
class QuanConv2d(nn.Module):
def __init__(self, input_channels, output_channels,
kernel_size=-1, stride=-1, padding=-1, groups=1, last_relu=0, abits=8, wbits=8, bn_fold=0, q_type=1, first_layer=0):
super(QuanConv2d, self).__init__()
self.last_relu = last_relu
self.bn_fold = bn_fold
self.first_layer = first_layer
if self.bn_fold == 1:
self.bn_q_conv = BNFold_Conv2d_Q(input_channels, output_channels,
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups, a_bits=abits, w_bits=wbits, q_type=q_type, first_layer=first_layer)
else:
self.q_conv = Conv2d_Q(input_channels, output_channels,
kernel_size=kernel_size, stride=stride, padding=padding, groups=groups, a_bits=abits, w_bits=wbits, q_type=q_type, first_layer=first_layer)
self.bn = nn.BatchNorm2d(output_channels, momentum=0.01) # 考虑量化带来的抖动影响,对momentum进行调整(0.1 ——> 0.01),削弱batch统计参数占比,一定程度抑制抖动。经实验量化训练效果更好,acc提升1%左右
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
if not self.first_layer:
x = self.relu(x)
if self.bn_fold == 1:
x = self.bn_q_conv(x)
else:
x = self.q_conv(x)
x = self.bn(x)
if self.last_relu:
x = self.relu(x)
return x
class Net(nn.Module):
def __init__(self, cfg = None, abits=8, wbits=8, bn_fold=0, q_type=1):
super(Net, self).__init__()
if cfg is None:
cfg = [192, 160, 96, 192, 192, 192, 192, 192]
# model - A/W全量化(除输入、输出外)
self.quan_model = nn.Sequential(
QuanConv2d(3, cfg[0], kernel_size=5, stride=1, padding=2, abits=abits, wbits=wbits, bn_fold=bn_fold, q_type=q_type, first_layer=1),
QuanConv2d(cfg[0], cfg[1], kernel_size=1, stride=1, padding=0, abits=abits, wbits=wbits, bn_fold=bn_fold, q_type=q_type),
QuanConv2d(cfg[1], cfg[2], kernel_size=1, stride=1, padding=0, abits=abits, wbits=wbits, bn_fold=bn_fold, q_type=q_type),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
QuanConv2d(cfg[2], cfg[3], kernel_size=5, stride=1, padding=2, abits=abits, wbits=wbits, bn_fold=bn_fold, q_type=q_type),
QuanConv2d(cfg[3], cfg[4], kernel_size=1, stride=1, padding=0, abits=abits, wbits=wbits, bn_fold=bn_fold, q_type=q_type),
QuanConv2d(cfg[4], cfg[5], kernel_size=1, stride=1, padding=0, abits=abits, wbits=wbits, bn_fold=bn_fold, q_type=q_type),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
QuanConv2d(cfg[5], cfg[6], kernel_size=3, stride=1, padding=1, abits=abits, wbits=wbits, bn_fold=bn_fold, q_type=q_type),
QuanConv2d(cfg[6], cfg[7], kernel_size=1, stride=1, padding=0, abits=abits, wbits=wbits, bn_fold=bn_fold, q_type=q_type),
QuanConv2d(cfg[7], 10, kernel_size=1, stride=1, padding=0, last_relu=1, abits=abits, wbits=wbits, bn_fold=bn_fold, q_type=q_type),
nn.AvgPool2d(kernel_size=8, stride=1, padding=0),
)
def forward(self, x):
x = self.quan_model(x)
x = x.view(x.size(0), -1)
return x
后量化: