最近在整理电脑里的文件,发现帮别人写过一个自动化处理excel的脚本,基本涉及了pansad操作excel的一些基本操作,读不通页,操作和遍历单元格这些,作为一个学习demo挺经典的,记录一下,说不定哪天自己忘记pandas怎么用,回来看一下就懂。
问题是这样,有一个excel,其中每一页都有一些信息,有一个key[n],和多个value (个数位 num(n)),我们要把这些信息聚合成一个大表,大表共有N个key,每个key和每个value的组合都要遍历列举出来,这样大表就总共有 num(1)*num(2)*…num(n) 个项:
\Pi_n(num(n))
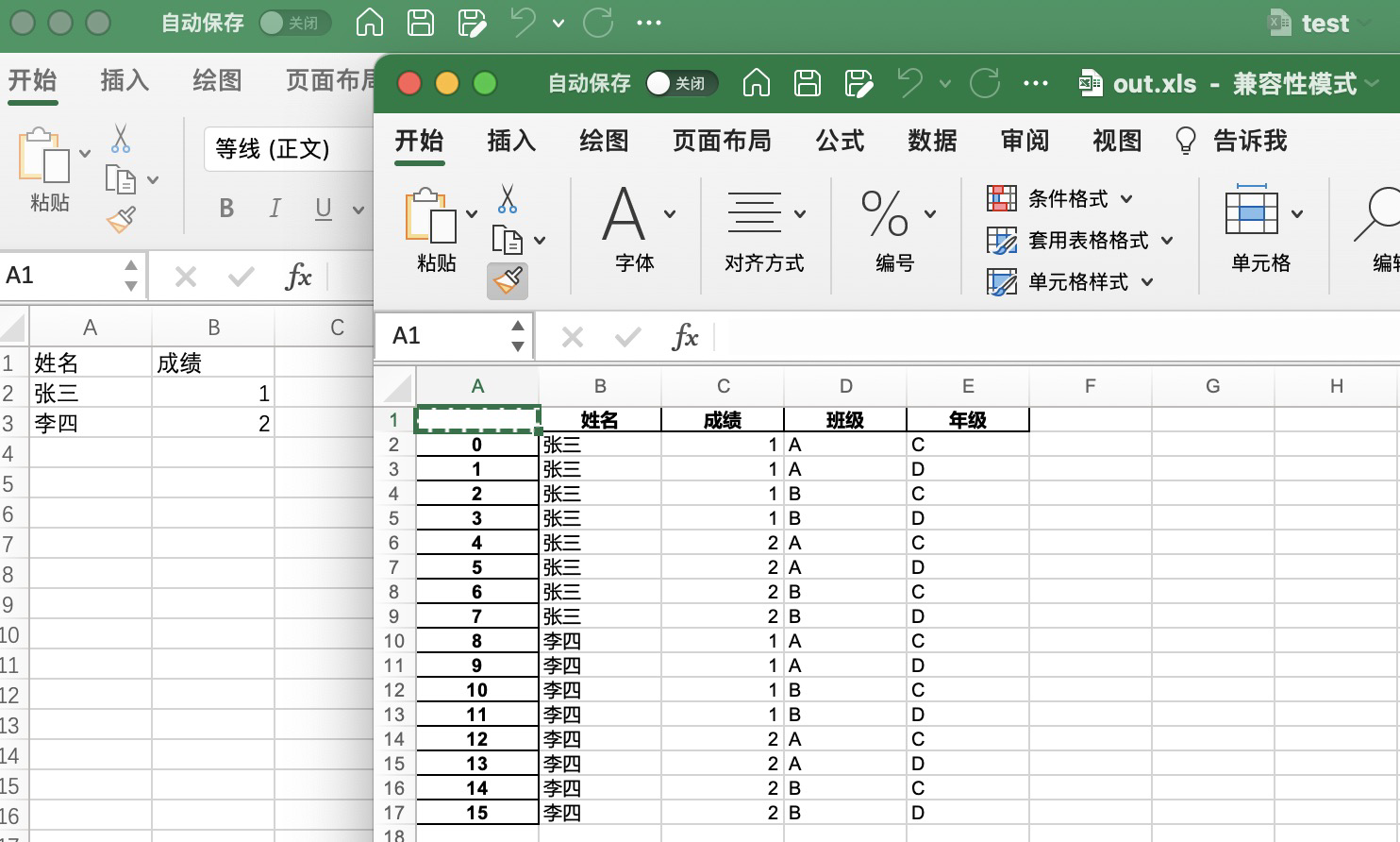
生成的表格长这个样子
import numpy as np
import pandas as pd
def xlsx_merge():
filename = './test.xlsx'
sheets = [0, 1]
# calc total colum
total_rows = 1
column_list = []
column_dict = dict()
out_shape = []
for i in range(len(sheets)):
sheet = pd.read_excel(io=filename, sheet_name=sheets[i])
for j in range(len(sheet.columns)):
column_list.append(sheet.columns[j])
column_dict[sheet.columns[j]] = sheet.values[:,j]
out_shape.append(len(sheet.values[:,j]))
total_rows = total_rows * len(sheet.columns)
# copy to new excel
map_idx = np.arange(total_rows)
map_idx = map_idx.reshape(tuple(out_shape))
out_array = np.empty((total_rows, len(column_list)), dtype=object)
for i in range(total_rows):
loc = np.argwhere(map_idx==i).flatten()
for j in range(len(column_list)):
out_array[i,j] = column_dict[column_list[j]][loc[j]]
df = pd.DataFrame(out_array, columns=column_list)
df.to_excel('./out.xls')
print('out_dict')
return
if __name__ == '__main__':
xlsx_merge()
好,整理完毕,本地代码可以清理掉了,耶~