CLIP(Contrastive Language-Image Pre-training),OpenAI给的title:Connecting text and images,被用作文本监督信号来训练可迁移的视觉模型。CLIP是一种基于对比学习的多模态模型,训练数据是文本-图像对(一张图像和其对应的文本描述),模型能够学习到文本-图像对的匹配关系。以下内容搜集自论文、知乎、OpenAI Blog Page (一手资料参阅以下链接的openai blog)
论文:https://arxiv.org/abs/2103.00020
BLOG:https://openai.com/blog/clip/
Github:https://github.com/openai/CLIP
知乎:(https://zhuanlan.zhihu.com/p/493489688)
如下图所示,CLIP包括两个模型Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像特征,可以用常用的CNN模型或者vision transformer。
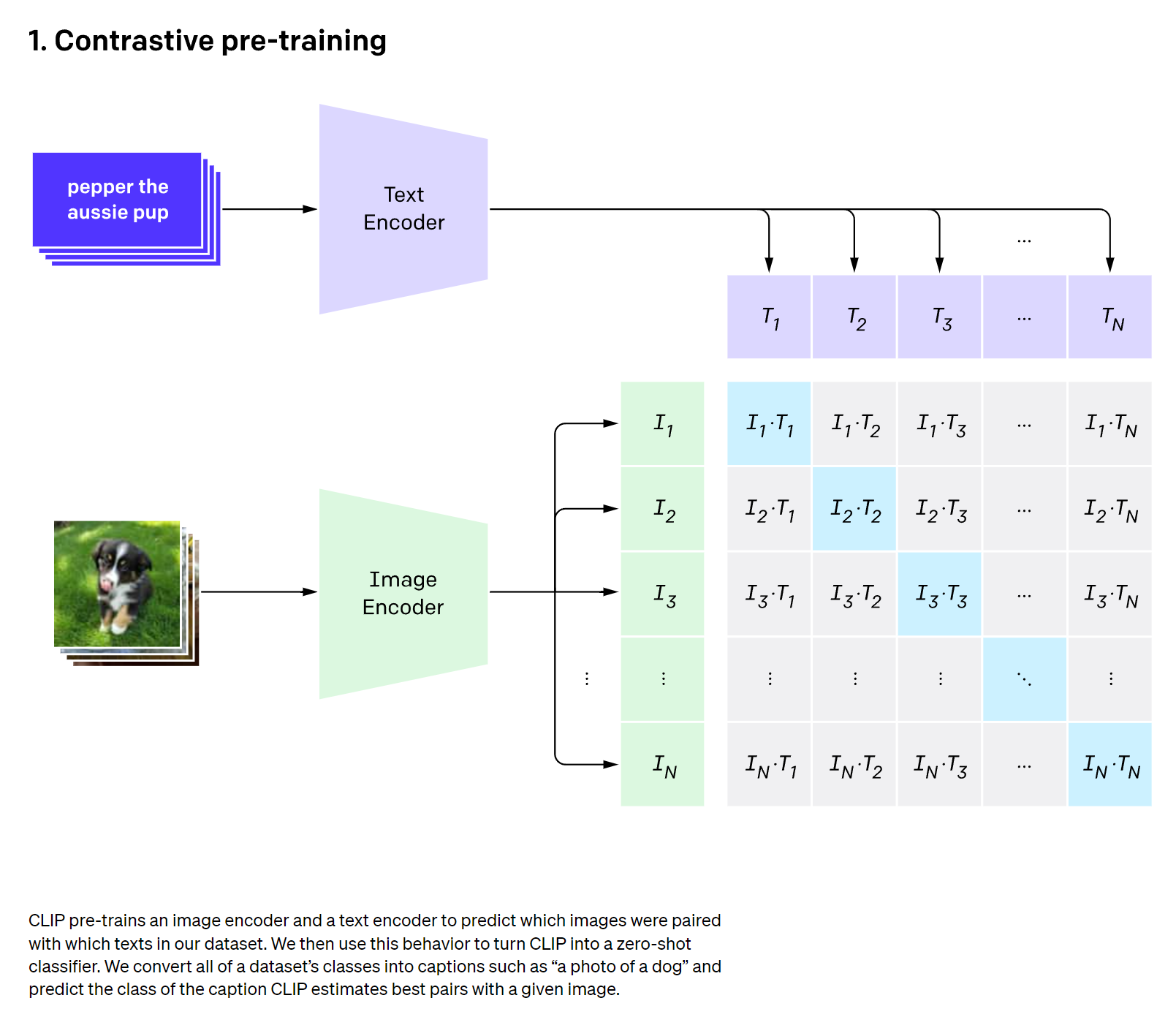
这里对提取的文本特征和图像特征进行对比学习。对于一个包含N个文本=图像对的训练batch,将N个文本特征和N个图像特征两两组合,CLIP模型会预测出N^2个可能的文本-图像对的相似度,这里的相似度计算直接使用文本特征和图像特征的余弦相似性(cosine similarity),即上图所示的矩阵。这里共有N个正样本(对角线元素),剩余N^2-N个负样本,那么CLIP的训练目标就是最大N个正样本的相似度,同时最小化N^2-N个负样本的相似度。
伪代码实现:
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# 分别提取图像特征和文本特征
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# 对两个特征进行线性投射,得到相同维度的特征,并进行l2归一化
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# 计算缩放的余弦相似度:[n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# 对称的对比学习损失:等价于N个类别的cross_entropy_loss
labels = np.arange(n) # 对角线元素的labels
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2为了训练CLIP,OpenAI从互联网收集了共4亿个文本-图像对,论文称之为WebImageText。
CLIP虽然是多模态模型,但它主要是用来训练可迁移的视觉模型。论文中的Text Encoder固定选择一个包含63M参数的text transformer模型,而Image Encoder采用两种不同的架构,一种是CNN架构ResNet,另一种是transformer架构的ViT,论文对比了这两类不同大小的模型的效果。训练的batch size为32768,AdamW优化器训练32个epochs,Vit需要在592个V100卡上训练18填,Vit-L需要在256张V100卡上训练12天,最终发现效果最佳的模型为ViT-L/14@336, 论文中精选对比实验的CLIP模型也采用这个。
使用CLIP实现zero-shot分类
论文利用CLIP的多模态特性为具体任务构建了动态的分类器,其中Text Encoder提取的文本特征可以堪称分类器的weights,而Image Encoder提取的图像特征是分类器的输入。
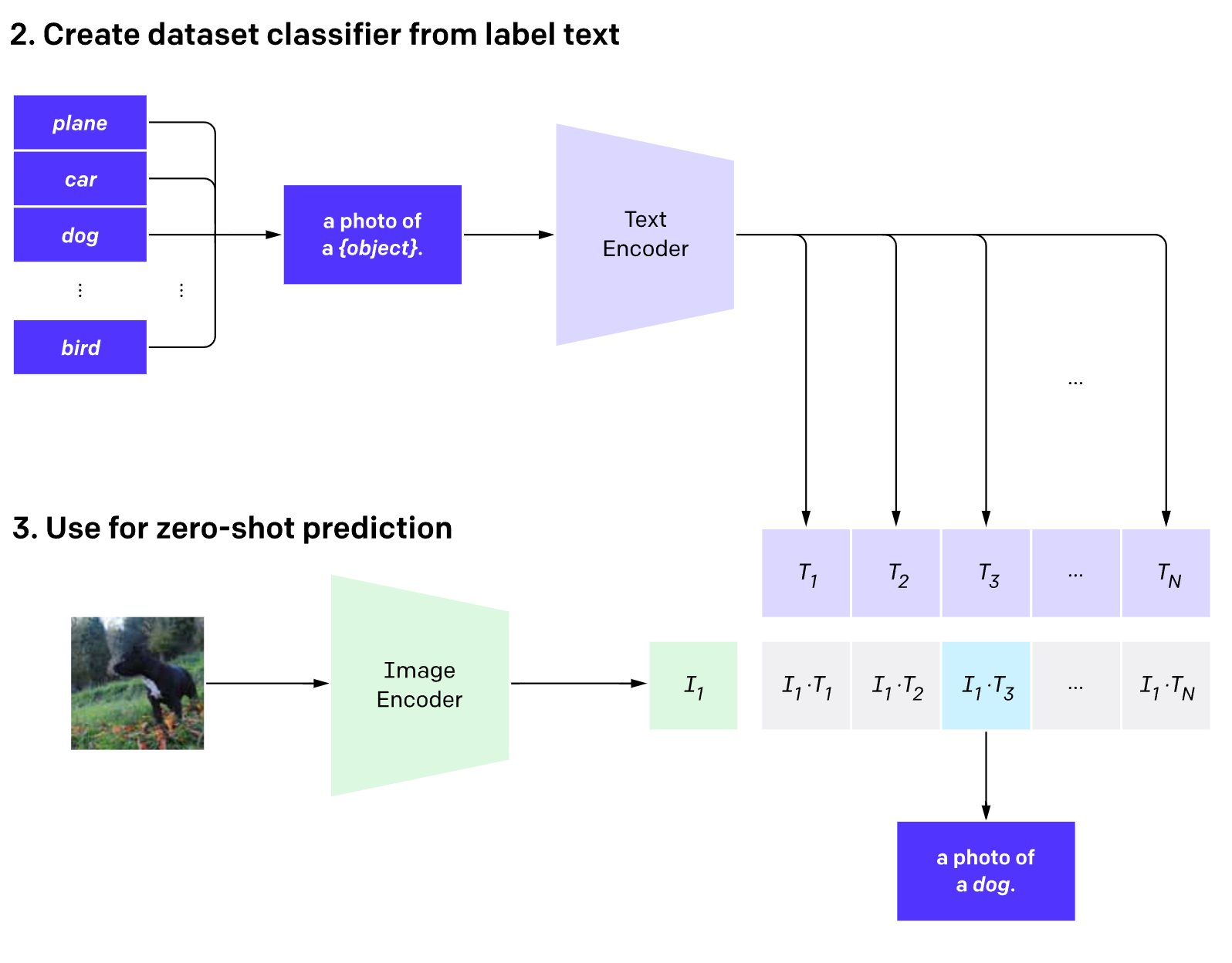
OpenAI的notebook给了一个例子(https://github.com/openai/CLIP/blob/main/notebooks/Interacting_with_CLIP.ipynb),我们构建一个具有6个类别的分类任务:”dog”, “cat”, “bird”, “person”, “mushroom”, “cup”, 首先我们创建文本描述,然后提取文本特征:
# 首先生成每个类别的文本描述
labels = ["dog", "cat", "bird", "person", "mushroom", "cup"]
text_descriptions = [f"A photo of a {label}" for label in labels]
text_tokens = clip.tokenize(text_descriptions).cuda()
# 提取文本特征
with torch.no_grad():
text_features = model.encode_text(text_tokens).float()
text_features /= text_features.norm(dim=-1, keepdim=True)然后读取要预测的图像,输入Image Encoder提取图像特征,并计算与文本特征的余弦相似度:
# 读取图像
original_images = []
images = []
texts = []
for label in labels:
image_file = os.path.join("images", label+".jpg")
name = os.path.basename(image_file).split('.')[0]
image = Image.open(image_file).convert("RGB")
original_images.append(image)
images.append(preprocess(image))
texts.append(name)
image_input = torch.tensor(np.stack(images)).cuda()
# 提取图像特征
with torch.no_grad():
image_features = model.encode_image(image_input).float()
image_features /= image_features.norm(dim=-1, keepdim=True)
# 计算余弦相似度(未缩放)
similarity = text_features.cpu().numpy() @ image_features.cpu().numpy().T相似度如下所示,可以看到对于要预测的6个图像,按照最大相似度,其均能匹配到正确的文本标签
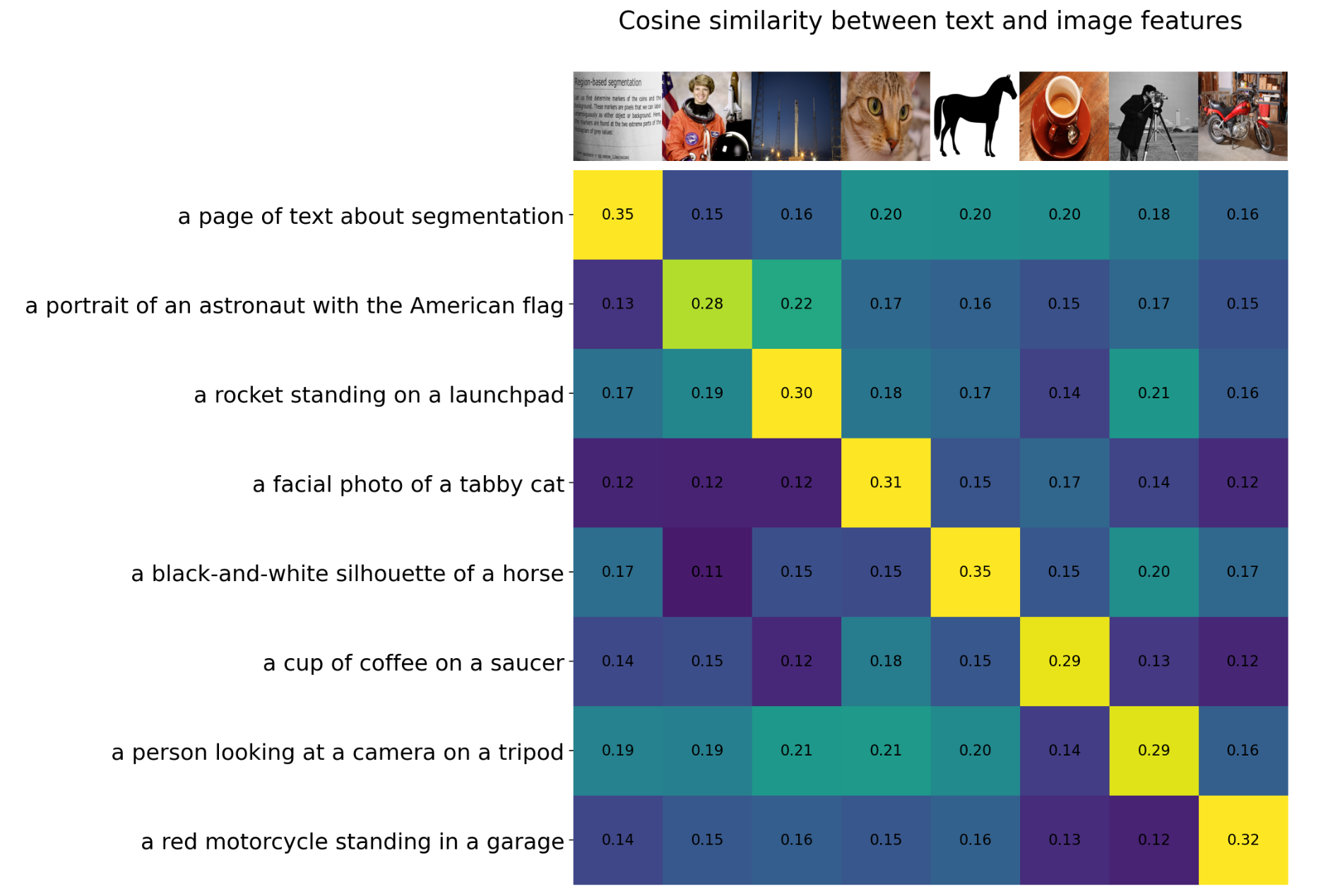
进一步,我们也可以对余弦相似度计算softmax,得到每个预测类别的最大概率值,这样就是CLIP进行了zero-shot分类。
CLIP另一个比较重要的应用是文本描述的生成,比如我们可以用上述类别标签,构建合适的prompt给到下游任务,CLIP给出的为类别的描述文本,类别描述文本比起单个字符的类别标签对下游任务提升更大。
CLIP用在分类任务上表现优秀,但是在一些特别的,复杂的或者抽象的数据集上表现较差,比如卫星图像分类、淋巴结转移检测,在合成场景中计数等。CLIP域外泛化性较差(比如MINIST数据集分类准确度只有88%,作者发现4亿的数据集中基本没有和MNIST比较相似的数据,这对CLIP来说属于域外数据了)
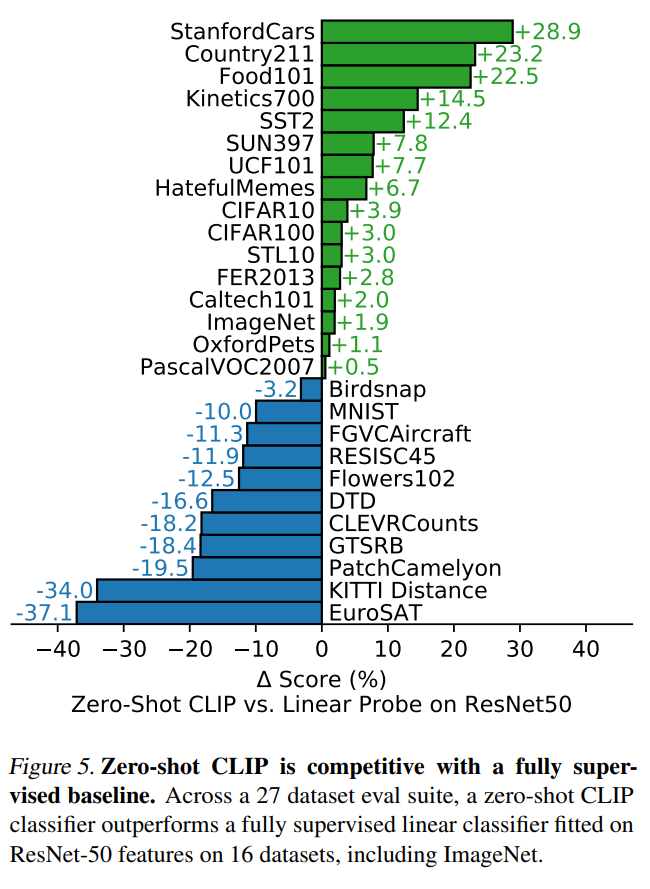
除了zero-shot对比,论嗯还对比few-shot性能,即只用少量样本来微调模型,这里对比了3个模型:在ImageNet21K上训练的BiT-M ResNet-152×2,基于SimCLRv2训练的ResNet50,以及有监督训练的ResNet50。可以看到CLIP的zero-shot和最好的模型(BiT-M)在16-shot下的性能相当,而CLIP在16-shot下效果有进一步的提升。另外一个比较有意思的结果是:虽然CLIP在few-shot实验中随着样本量增加性能有提升,但是1-shot和2-shot性能比zero-shot还差,这个作者认为主要是CLIP的训练和常规的有监督训练存在一定的差异造成的。
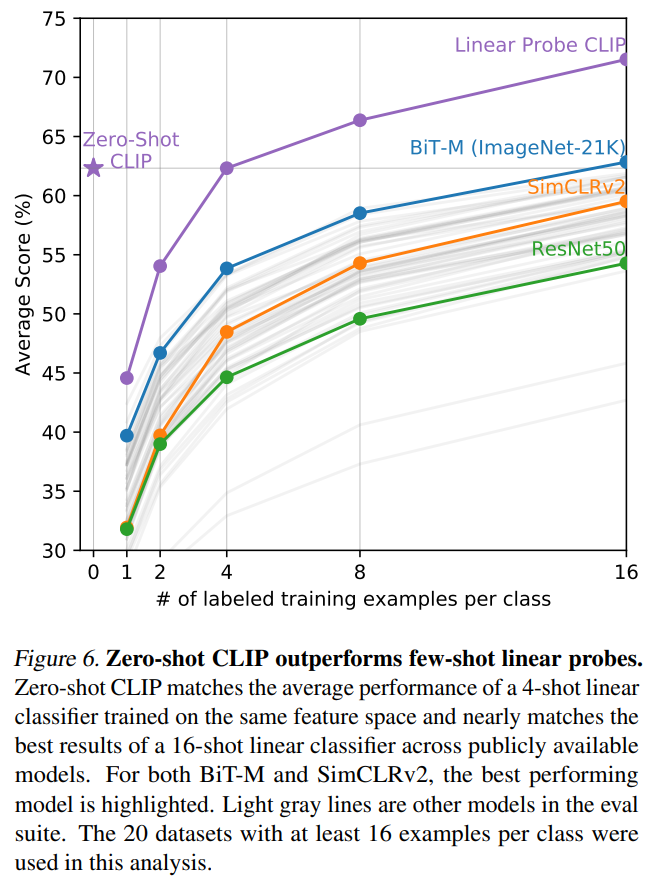
除此之外,论文还进行了表征学习(representation Learning)实验,即子监督学习中常用的linear probe:用与训练好的模型先提取特征,然后用一个线性分类器来进行有监督训练。下图为不同模型在27个数据集上的average linear probe score对比,可以看到CLIP模型在性能上超过其它模型
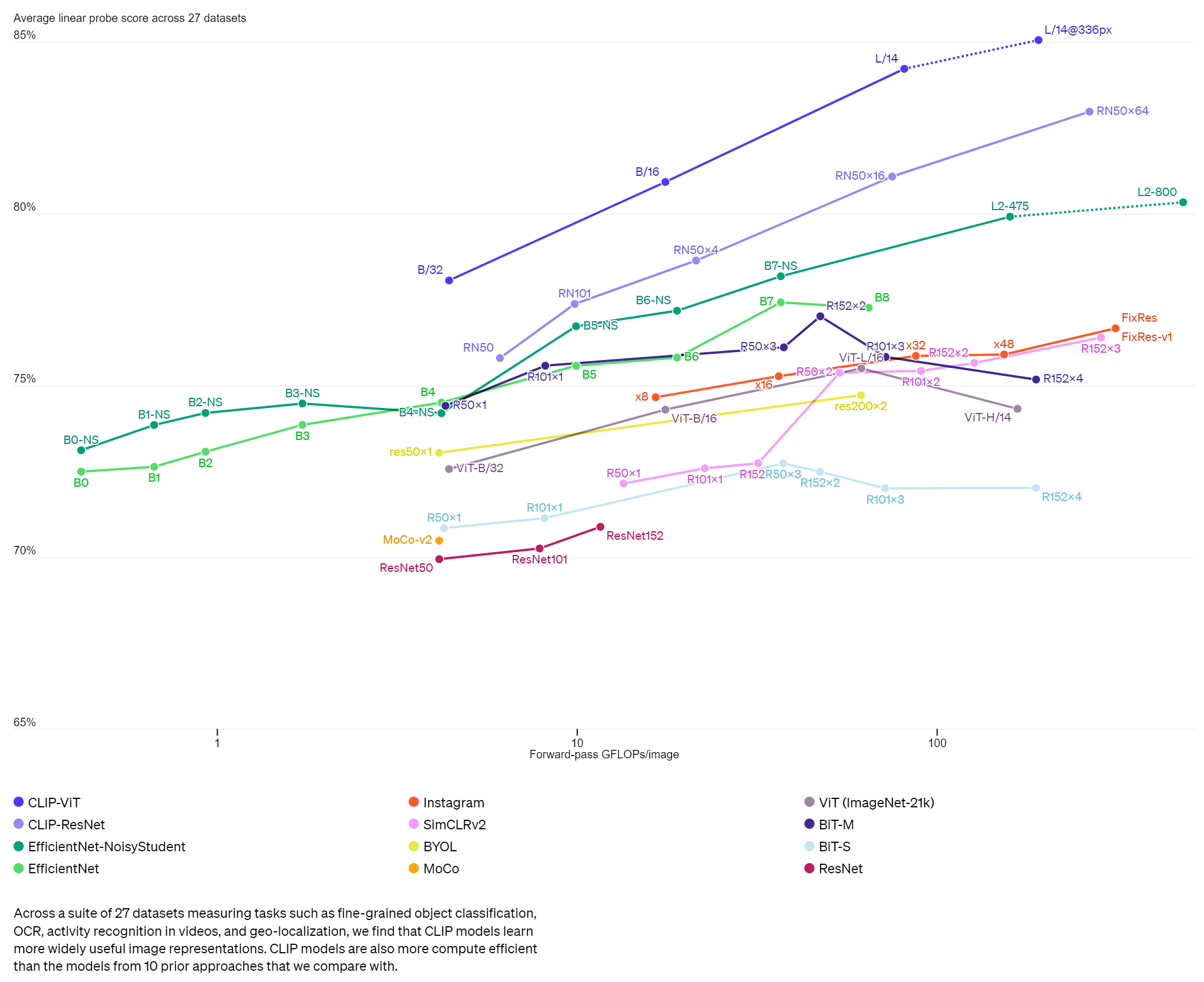
论文还测试了CLIP的自然分布漂移上表现更鲁棒

CLIP能实现这么好的zero-shot性能,大家很可能质疑CLIP的训练数据集可能包含一些测试数据集中的样例,即所谓的数据泄漏。关于这点,论文也采用一个重复检测器对评测的数据集重合做了检查,发现重合率的中位数为2.2%,而平均值在3.2%,去重前后大部分数据集的性能没有太大的变化。
论文的最后也对CLIP的局限性做了讨论,这里简单总结其中比较重要的几点:
- CLIP的zero-shot性能虽然和有监督的ResNet50相当,但是还不是SOTA,作者估计要达到SOTA的效果,CLIP还需要增加1000x的计算量,这是难以想象的;
- CLIP的zero-shot在某些数据集上表现较差,如细粒度分类,抽象任务等;
- CLIP在自然分布漂移上表现鲁棒,但是依然存在域外泛化问题,即如果测试数据集的分布和训练集相差较大,CLIP会表现较差;
- CLIP并没有解决深度学习的数据效率低下难题,训练CLIP需要大量的数据;
关于CLIP Score,CLIP Score使用与训练的CLIP,可以测量图像和文字的相似程度,在文生图等应用中被用来作为评估相似性的客观指标。CLIP Score 分为CLIP-I 和 CLIP-T
CLIP-I is the average pairwise cosine similarity between CLIP embeddings of generated and real images.
计算一下生成图像和真实图像的image emb的平均余弦相似度。
CLIP-T, The second important aspect to evaluate is prompt fidelity, measured as the average cosine similarity between prompt and image CLIP embeddings. We denote this as CLIP-T
计算生成图像的image emb和text emb的平均余弦相似度
E_I=CLIP_{Img}(I) \\ E_T=CLIP_{Text}(T)使用预训练CLIP计算CLIP Score的步骤:将图像、文字,分別送入CLIP的图像编码器和文本编码器,得到图像特征向量、文本特征向量,然后计算两个向量的余弦相似度:
Sim_{CLIP}(I,T)=\frac{E_I E_t}{||E_I||_2||E_T||_2}同时考虑负面提示词的影响,计算过程可以阅读代码: https://github.com/Taited/clip-score
下面贴一下上面仓库的核心代码
def calculate_clip_score(dataloader, model, real_flag, fake_flag):
score_acc = 0.
sample_num = 0.
logit_scale = model.logit_scale.exp()
for batch_data in tqdm(dataloader):
real = batch_data['real']
real_features = forward_modality(model, real, real_flag)
fake = batch_data['fake']
fake_features = forward_modality(model, fake, fake_flag)
# normalize features
real_features = real_features / real_features.norm(dim=1, keepdim=True).to(torch.float32)
fake_features = fake_features / fake_features.norm(dim=1, keepdim=True).to(torch.float32)
# calculate scores
# score = logit_scale * real_features @ fake_features.t()
# score_acc += torch.diag(score).sum()
score = logit_scale * (fake_features * real_features).sum()
score_acc += score
sample_num += real.shape[0]
return score_acc / sample_num