Caffe的作者是贾扬清(伯克利大学博士期间成果),其在深度学习科学研究中有着非同一般的地位,尤其是其代码在github上开源,以及CUDA加速的使用,使得普通学者也可以较为轻松的进行训练,介绍就不多说了,作为Caffe的第一课,首先就是Caffe环境配置、编译以及导入IDE中方便调试了,我们开始吧。
跨平台的protobuf安装配置方案
现在有很多介绍protobuf的文章,而本篇博客与其它文章的不同在于,为不同平台及不同编译环境下适配protobuf提供一体化的解决方案,包括linux,windows系统,同时在Windows系统中控制台 MFC等框架下也会有不同的编译环境,比如你可以选择使用静态库还是动态库等,偶尔,我们还会需要google的其它库,比如glog,接下来将进行详细介绍。
MFC中显示Mat格式图像——Mat转CImage方法
Mat是opencv中的图像格式,如果想要图像在MFC中显示,将Mat格式转为MFC支持的CImage格式是一种较为优秀的解决方案,这篇博客就来介绍在MFC中显示Mat图像的方法。虽然原理相同,但博主还是要介绍两种方式:一种是通过子类化显示控件的方式进行显示,第二种是在父窗口中调用。如果你做的工程比较庞大,博主建议使用子类化控件的方法,当然,如果你是小工程,博主也依然建议你使用子类化的方法,这样不仅使代码结构简单封装良好,而且方便了控件的拓展。
在MFC中使用OpenGL
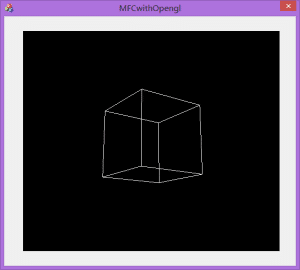 老外的教程果然还是非常赞的,强烈推荐原版,这篇博客简单介绍一下步骤:
老外的教程果然还是非常赞的,强烈推荐原版,这篇博客简单介绍一下步骤:
1.新建MFC工程
2.添加Picture Control控件
3.添加一个OpenGL控件类
4.在MFC中使用OpenGL控件
获取博主编译的测试工程(使用VS2013 X64平台,你还需要另外配置OpenGL相关环境),运行效果如左图所示,这个Demo还可以接受鼠标的控制,对模型进行操作。如果你需要多个OpenGL窗口,再实例化这个类,可以很轻易地实现多个窗口的绘制。这里就不翻译老外网站上的教程了,在上面给出了框架搭建的链接,这里就直接介绍该OpenGL类的使用方法吧。
VRML解析——使用OpenGL绘制wrl三维模型
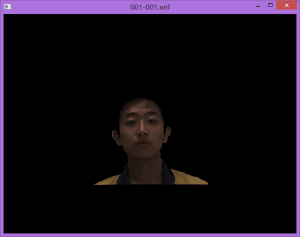 这里,我们首先释出编译好的读取wrl文件的程序,如左图所示,是打开的一个CASIA-3D-Face数据库的三维模型文件,使用Opengl进行了绘制。这个程序还提供了一些快捷键,使我们可以方便的移动模型和视角,如ASDW等。
这里,我们首先释出编译好的读取wrl文件的程序,如左图所示,是打开的一个CASIA-3D-Face数据库的三维模型文件,使用Opengl进行了绘制。这个程序还提供了一些快捷键,使我们可以方便的移动模型和视角,如ASDW等。
这里提供了一个编译好的demo的下载链接,请注意,程序必须运行在64位的Windows上,你需要打开prototxt文件,修改你需要打开的wrl文件的目录,由于使用静态库进行编译,你不需要相关环境(Opengl protobuf glog等),但是你可能需要安装VC2013Runtime X64。
当然,你也可以使用此博客中的代码,编译其它版本的程序,下面的内容会默认你已经了解了本博客前两节的内容,对wrl文件的格式和本文读取wrl文件的方式有所了解。在本程序的icp类中包含了OpenGL的相关内容,参考了 LeheOpenGL 的代码设计,如果你对OpenGL还不太了解,推荐经典入门教程:Nehe的OpenGL教程。不多说了,开始吧。
VRML解析——C++处理CASIA-3D-Face数据库wrl文件
虽然VRML语言已经被HTML5取代,但是仍有许多早期的三维模型文件采用wrl文件存储,并且偶尔会在转存成其它文件的过程中遇到问题,于是我们常常需要直接解析wrl文件。这里给需要解析wrl文件的同学指一条明路:Openvrml。
Openvrml本身调用了许多库,可以借助ARToolKit或者OGN进行安装,据说OGN比较容易一些,博主并没有使用过上述工具。而编译openvrml的过程极其痛苦,于是博主自己写了一个解析CASIA-3D-Face数据库中wrl文件的程序,仅供参考。这里附上中科院三维人脸数据库的链接,感谢中科院免费提供的资源。
VRML简介——虚拟现实构造语言
VRML是一种与互联网结合,用来描述三维交互世界的程序语言,VRML即Virtual-Reality Modeling Language。
SGI开发的Open Inventor软件的开放式三维文件格式被选定作为VRML的文件格式。1995年,VRML1.0版本正式推出,1996年推出了VRML2.0版本,添加了场景交互 多媒体支持 碰撞检测等功能,VRML2.0一直沿用,直到HTML5取代其地位。