这篇博客介绍 Google 近年来在Photography方面一篇具有代表性的论文,Deep Bilateral Learning for Real-Time Image Enhancement
HDRNET的主要特征数数据分成两路,低分辨率偏向high level语义,这一路学习到的是一系列参数(分mesh的3×4 color matrix),学习参数需要的计算资源相对于学习输出图需要的资源更少,移动端部署更加方便。高分辨率一路更偏向low-level引导,学些引导图和参数apply。
首先看下网络结构,总体分成两路,上面这一路是低分辨率图像的处理,通过一张降采样的图,学习到一些low level 的feature,之后又会分成两路,一路学习local feature,另一路学习global feature,这两路特征在生成参数之前会合并起来。高分辨率这一路首先学习引导图,结合引导图将特征参数上采样,然后再逐像素的apply特征变换。
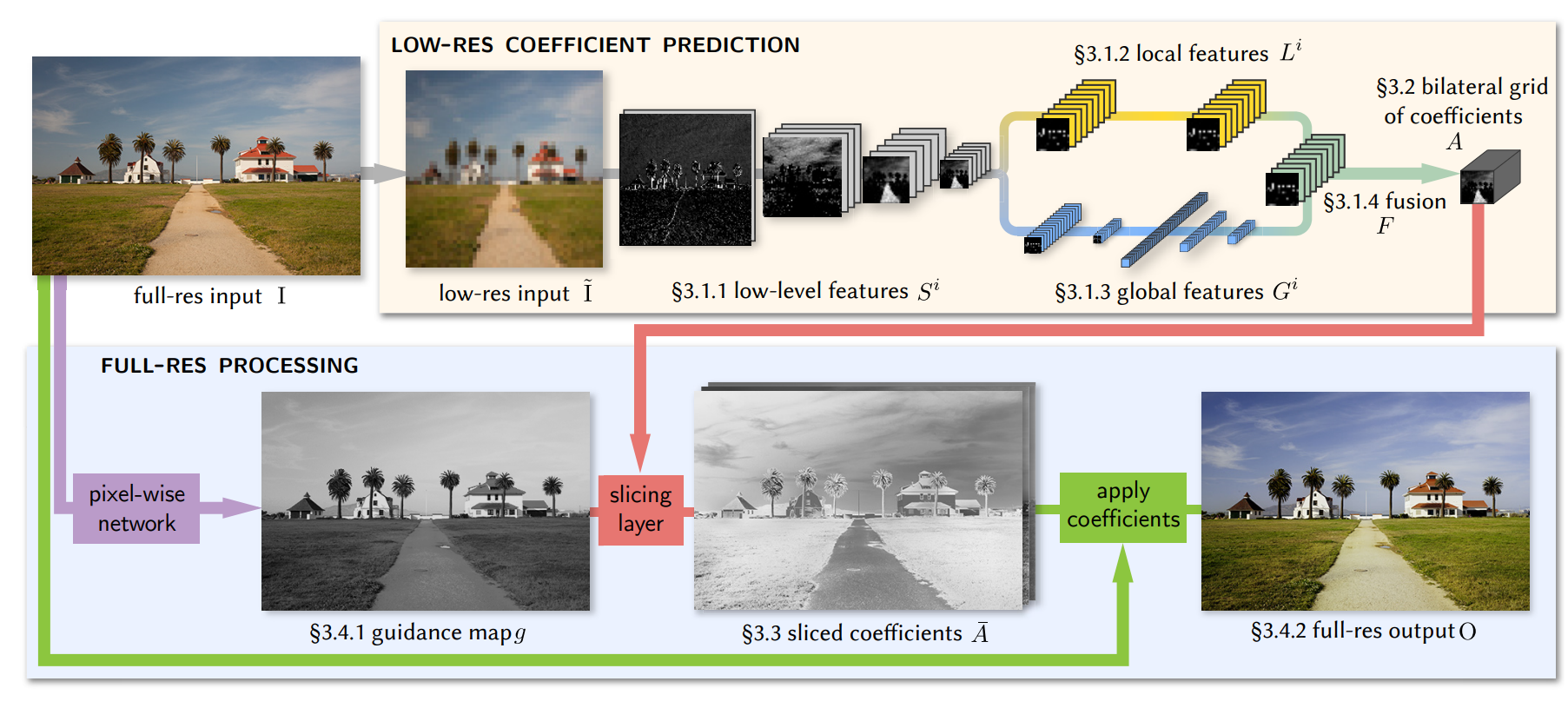
一、Bilatral Grid
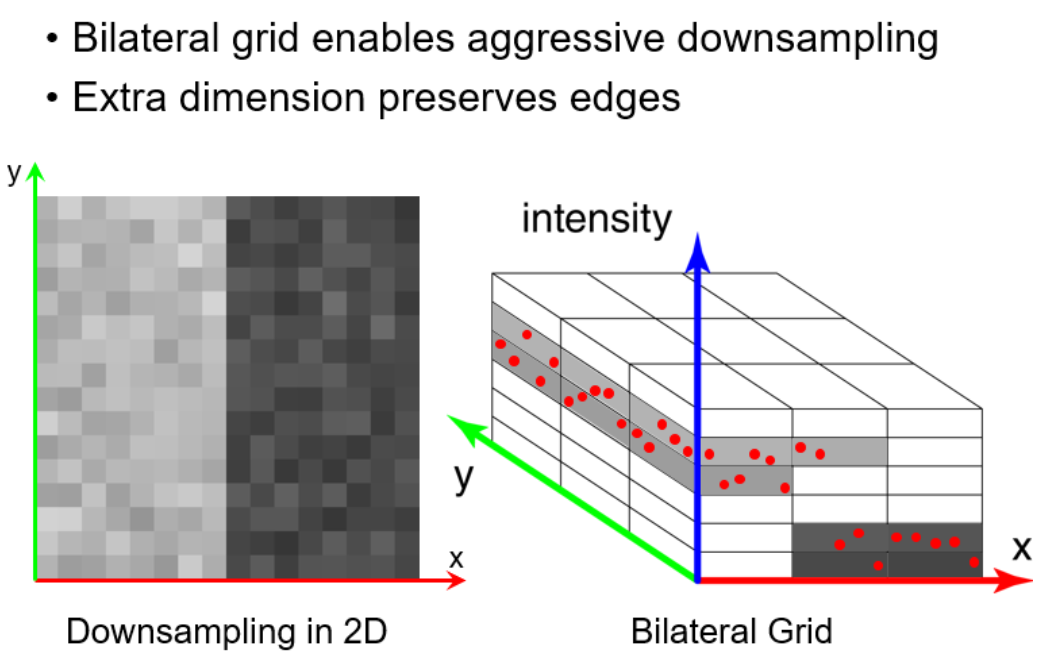
网络中学习的一个重要参数是bilatetral grid 参数,我们首先看下什么是bilatral grid。参考连接:https://zhuanlan.zhihu.com/p/365874538
bilatral grid 要追根溯源到 bilatral filter,bilatetral filter是说,一个滤波位置的权重和像素位置、像素值(滤波点像素值与中心像素值的差值)都有关系。
w(p,q)=g_{\sigma s} (||p-q||)*g_{\sigma r}(||I(p)-I(q)||)bilatral filter的计算复杂度很高,Durand发现可以通过如下方法来简化bilatral filter的计算。https://dspace.mit.edu/bitstream/handle/1721.1/34876/MIT-CSAIL-TR-2006-073.pdf?sequence=1
- 将像素值作为一个额外维度,使得weight计算变成了第三个维度的卷积,提高data locality利用率。
- 离散化,利用额外channel记录滤波器系数累加和
- 使用slicing操作重新得到原数据空间的值
我们首先将2D图像,离散化到一个3D的grid中,这个3D grid是一个低分辨率的网络,我们的滤波可以转化到这个3D网络中来进行。

具体滤波过程我们拿论文的几张一维表示图来说明,1D的bilatral filter,经过grid操作后数据变成2D,可以直观画出来,方便我们理解
下图一维情况中,横轴是图像空间,纵轴是升维后的值域空间。即先对空间做下采样,然后过一遍高斯核得到滤波后的分子和分母(滤波中心点是当前x所在的grid),然后把分子除以分母,最后再上采样映射回去,得到去噪后的结果。
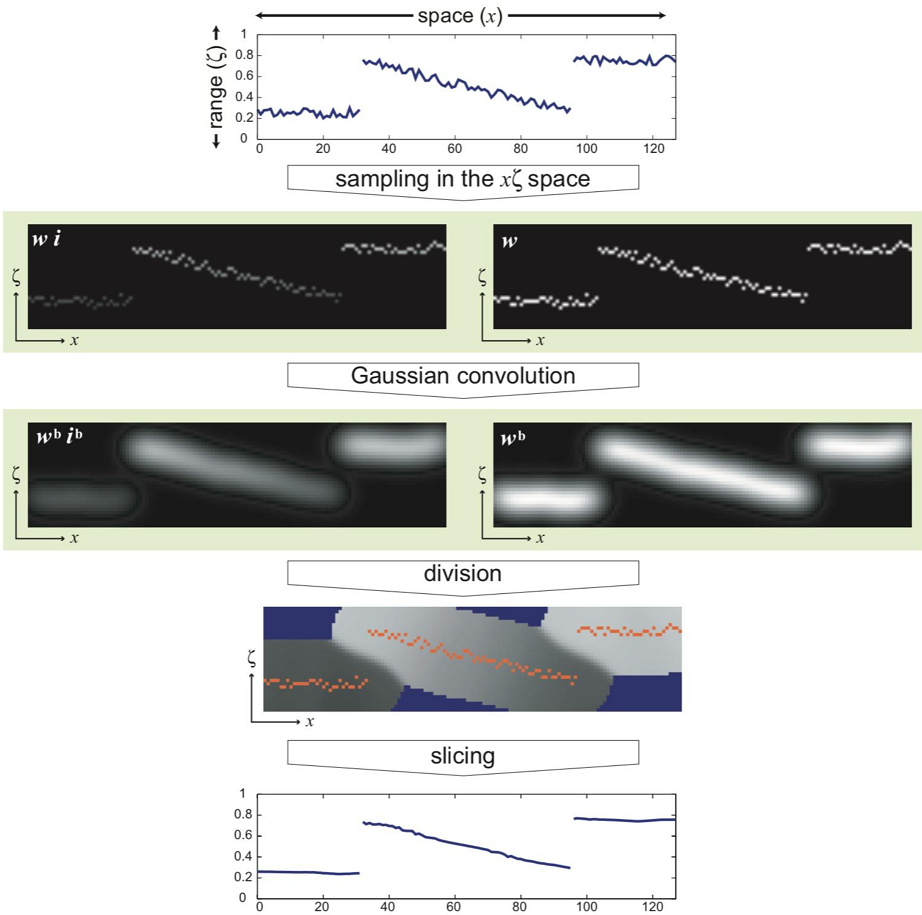
bilatral grid是在这篇论文中提出。https://groups.csail.mit.edu/graphics/bilagrid/bilagrid_web.pdf
另外,bilatral grid还有很多妙用,可以调制边缘blur或者sharpen,可以控制上采样等,可以查阅文件检索。

对于理解论文来说,我们需要知道bilatral grid将2D图像离散化到3D网格中进行卷积滤波,得到输出图像。
二、Network Pytorch
我们对着代码继续理解下网络结构和参数规模:
因为原始论文比较早,google当时用tensorflow比较多,官方link的连接是tensorflow版本 https://github.com/mgharbi/hdrnet, 后来也有很多pytorch版本,我们用这个版本的pytorch源码来理解过程https://github.com/creotiv/hdrnet-pytorch/tree/master
我们先关注模型参数的初始化
class HDRPointwiseNN(nn.Module):
def __init__(self, params):
super(HDRPointwiseNN, self).__init__()
self.coeffs = Coeffs(params=params)
self.guide = GuideNN(params=params)
self.slice = Slice()
self.apply_coeffs = ApplyCoeffs()
# self.bsa = bsa.BilateralSliceApply()
def forward(self, lowres, fullres):
coeffs = self.coeffs(lowres)
guide = self.guide(fullres)
slice_coeffs = self.slice(coeffs, guide)
out = self.apply_coeffs(slice_coeffs, fullres)
# out = bsa.bsa(coeffs,guide,fullres)
return out
我们再下面,特别留意输出参数的规模(网格和通道)
from turtle import forward
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from collections import OrderedDict
from slice import bilateral_slice
class L2LOSS(nn.Module):
def forward(self, x,y):
return torch.mean((x-y)**2)
class ConvBlock(nn.Module):
def __init__(self, inc , outc, kernel_size=3, padding=1, stride=1, use_bias=True, activation=nn.ReLU, batch_norm=False):
super(ConvBlock, self).__init__()
self.conv = nn.Conv2d(int(inc), int(outc), kernel_size, padding=padding, stride=stride, bias=use_bias)
self.activation = activation() if activation else None
self.bn = nn.BatchNorm2d(outc) if batch_norm else None
if use_bias and not batch_norm:
self.conv.bias.data.fill_(0.00)
# aka TF variance_scaling_initializer
torch.nn.init.kaiming_uniform_(self.conv.weight)#, mode='fan_out',nonlinearity='relu')
def forward(self, x):
x = self.conv(x)
if self.bn:
x = self.bn(x)
if self.activation:
x = self.activation(x)
return x
class FC(nn.Module):
def __init__(self, inc , outc, activation=nn.ReLU, batch_norm=False):
super(FC, self).__init__()
self.fc = nn.Linear(int(inc), int(outc), bias=(not batch_norm))
self.activation = activation() if activation else None
self.bn = nn.BatchNorm1d(outc) if batch_norm else None
if not batch_norm:
self.fc.bias.data.fill_(0.00)
# aka TF variance_scaling_initializer
torch.nn.init.kaiming_uniform_(self.fc.weight)#, mode='fan_out',nonlinearity='relu')
def forward(self, x):
x = self.fc(x)
if self.bn:
x = self.bn(x)
if self.activation:
x = self.activation(x)
return x
class Slice(nn.Module):
def __init__(self):
super(Slice, self).__init__()
def forward(self, bilateral_grid, guidemap):
bilateral_grid = bilateral_grid.permute(0,3,4,2,1)
guidemap = guidemap.squeeze(1)
# grid: The bilateral grid with shape (gh, gw, gd, gc).
# guide: A guide image with shape (h, w). Values must be in the range [0, 1].
coeefs = bilateral_slice(bilateral_grid, guidemap).permute(0,3,1,2)
return coeefs
# Nx12x8x16x16
# print(guidemap.shape)
# print(bilateral_grid.shape)
# device = bilateral_grid.get_device()
# N, _, H, W = guidemap.shape
# hg, wg = torch.meshgrid([torch.arange(0, H), torch.arange(0, W)]) # [0,511] HxW
# if device >= 0:
# hg = hg.to(device)
# wg = wg.to(device)
# hg = hg.float().repeat(N, 1, 1).unsqueeze(3) / (H-1)# * 2 - 1 # norm to [-1,1] NxHxWx1
# wg = wg.float().repeat(N, 1, 1).unsqueeze(3) / (W-1)# * 2 - 1 # norm to [-1,1] NxHxWx1
# guidemap = guidemap.permute(0,2,3,1).contiguous()
# guidemap_guide = torch.cat([hg, wg, guidemap], dim=3).unsqueeze(1) # Nx1xHxWx3
# # When mode='bilinear' and the input is 5-D, the interpolation mode used internally will actually be trilinear.
# coeff = F.grid_sample(bilateral_grid, guidemap_guide, 'bilinear')#, align_corners=True)
# print(coeff.shape)
# return coeff.squeeze(2)
class ApplyCoeffs(nn.Module):
def __init__(self):
super(ApplyCoeffs, self).__init__()
def forward(self, coeff, full_res_input):
'''
Affine:
r = a11*r + a12*g + a13*b + a14
g = a21*r + a22*g + a23*b + a24
...
'''
# out_channels = []
# for chan in range(n_out):
# ret = scale[:, :, :, chan, 0]*input_image[:, :, :, 0]
# for chan_i in range(1, n_in):
# ret += scale[:, :, :, chan, chan_i]*input_image[:, :, :, chan_i]
# if has_affine_term:
# ret += offset[:, :, :, chan]
# ret = tf.expand_dims(ret, 3)
# out_channels.append(ret)
# ret = tf.concat(out_channels, 3)
"""
R = r1[0]*r2 + r1[1]*g2 + r1[2]*b3 +r1[3]
"""
# print(coeff.shape)
# R = torch.sum(full_res_input * coeff[:, 0:3, :, :], dim=1, keepdim=True) + coeff[:, 3:4, :, :]
# G = torch.sum(full_res_input * coeff[:, 4:7, :, :], dim=1, keepdim=True) + coeff[:, 7:8, :, :]
# B = torch.sum(full_res_input * coeff[:, 8:11, :, :], dim=1, keepdim=True) + coeff[:, 11:12, :, :]
R = torch.sum(full_res_input * coeff[:, 0:3, :, :], dim=1, keepdim=True) + coeff[:, 9:10, :, :]
G = torch.sum(full_res_input * coeff[:, 3:6, :, :], dim=1, keepdim=True) + coeff[:, 10:11, :, :]
B = torch.sum(full_res_input * coeff[:, 6:9, :, :], dim=1, keepdim=True) + coeff[:, 11:12, :, :]
return torch.cat([R, G, B], dim=1)
class GuideNN(nn.Module):
def __init__(self, params=None):
super(GuideNN, self).__init__()
self.params = params
self.conv1 = ConvBlock(3, params['guide_complexity'], kernel_size=1, padding=0, batch_norm=True)
self.conv2 = ConvBlock(params['guide_complexity'], 1, kernel_size=1, padding=0, activation= nn.Sigmoid) #nn.Tanh nn.Sigmoid
def forward(self, x):
return self.conv2(self.conv1(x))#.squeeze(1)
class Coeffs(nn.Module):
def __init__(self, nin=4, nout=3, params=None):
super(Coeffs, self).__init__()
self.params = params
self.nin = nin
self.nout = nout
lb = params['luma_bins']
cm = params['channel_multiplier']
sb = params['spatial_bin']
bn = params['batch_norm']
nsize = params['net_input_size']
self.relu = nn.ReLU()
# splat features
n_layers_splat = int(np.log2(nsize/sb))
self.splat_features = nn.ModuleList()
prev_ch = 3
for i in range(n_layers_splat):
use_bn = bn if i > 0 else False
self.splat_features.append(ConvBlock(prev_ch, cm*(2**i)*lb, 3, stride=2, batch_norm=use_bn))
prev_ch = splat_ch = cm*(2**i)*lb
# global features
n_layers_global = int(np.log2(sb/4))
self.global_features_conv = nn.ModuleList()
self.global_features_fc = nn.ModuleList()
for i in range(n_layers_global):
self.global_features_conv.append(ConvBlock(prev_ch, cm*8*lb, 3, stride=2, batch_norm=bn))
prev_ch = cm*8*lb
n_total = n_layers_splat + n_layers_global
prev_ch = prev_ch * (nsize/2**n_total)**2
self.global_features_fc.append(FC(prev_ch, 32*cm*lb, batch_norm=bn))
self.global_features_fc.append(FC(32*cm*lb, 16*cm*lb, batch_norm=bn))
self.global_features_fc.append(FC(16*cm*lb, 8*cm*lb, activation=None, batch_norm=bn))
# local features
self.local_features = nn.ModuleList()
self.local_features.append(ConvBlock(splat_ch, 8*cm*lb, 3, batch_norm=bn))
self.local_features.append(ConvBlock(8*cm*lb, 8*cm*lb, 3, activation=None, use_bias=False))
# predicton
self.conv_out = ConvBlock(8*cm*lb, lb*nout*nin, 1, padding=0, activation=None)#,batch_norm=True)
def forward(self, lowres_input):
params = self.params
bs = lowres_input.shape[0]
lb = params['luma_bins']
cm = params['channel_multiplier']
sb = params['spatial_bin']
x = lowres_input
for layer in self.splat_features:
x = layer(x)
splat_features = x
for layer in self.global_features_conv:
x = layer(x)
x = x.view(bs, -1)
for layer in self.global_features_fc:
x = layer(x)
global_features = x
x = splat_features
for layer in self.local_features:
x = layer(x)
local_features = x
fusion_grid = local_features
fusion_global = global_features.view(bs,8*cm*lb,1,1)
fusion = self.relu( fusion_grid + fusion_global )
x = self.conv_out(fusion)
s = x.shape
y = torch.stack(torch.split(x, self.nin*self.nout, 1),2)
# y = torch.stack(torch.split(y, self.nin, 1),3)
# print(y.shape)
# x = x.view(bs,self.nin*self.nout,lb,sb,sb) # B x Coefs x Luma x Spatial x Spatial
# print(x.shape)
return y
class HDRPointwiseNN(nn.Module):
def __init__(self, params):
super(HDRPointwiseNN, self).__init__()
self.coeffs = Coeffs(params=params)
self.guide = GuideNN(params=params)
self.slice = Slice()
self.apply_coeffs = ApplyCoeffs()
# self.bsa = bsa.BilateralSliceApply()
def forward(self, lowres, fullres):
coeffs = self.coeffs(lowres)
guide = self.guide(fullres)
slice_coeffs = self.slice(coeffs, guide)
out = self.apply_coeffs(slice_coeffs, fullres)
# out = bsa.bsa(coeffs,guide,fullres)
return out