在深度学习中,数据仿真一直是重要的topic,Unreal(虚幻引擎)是Epic主导的渲染引擎,常被用于游戏、场景设计、渲染计算,也可以被用于深度学习中的数据仿真,其中有一些比较有名的基于Unreal开发的数据仿真平台,比如CARLA(http://carla.org/)、AirSim等优秀的仿真平台被用于自动驾驶、机器人自动控制等。这篇博客也是介绍一个这样的项目UnrealCV,简单介绍下unrealcv的部署和使用。实际上UnrealCV没有CARLA和AirSim强大(主要是没有运动模型和碰撞检测),所以简单介绍仅供参考。
深度学习
Pytorch使用2d卷积来实现3d卷积
我们在深度学习模型转换和推理过程中常常会遇到算子不被工具链支持的情况,这时我们可以通过其它算子来等价实现我们想要的算子,比如3d卷积不被工具链支持,我们可以将其拆分成2d卷积,拆分之后我们需要进行权重字典的拆分。这篇博客贴一下pytorch的实现。
Vision Transformer
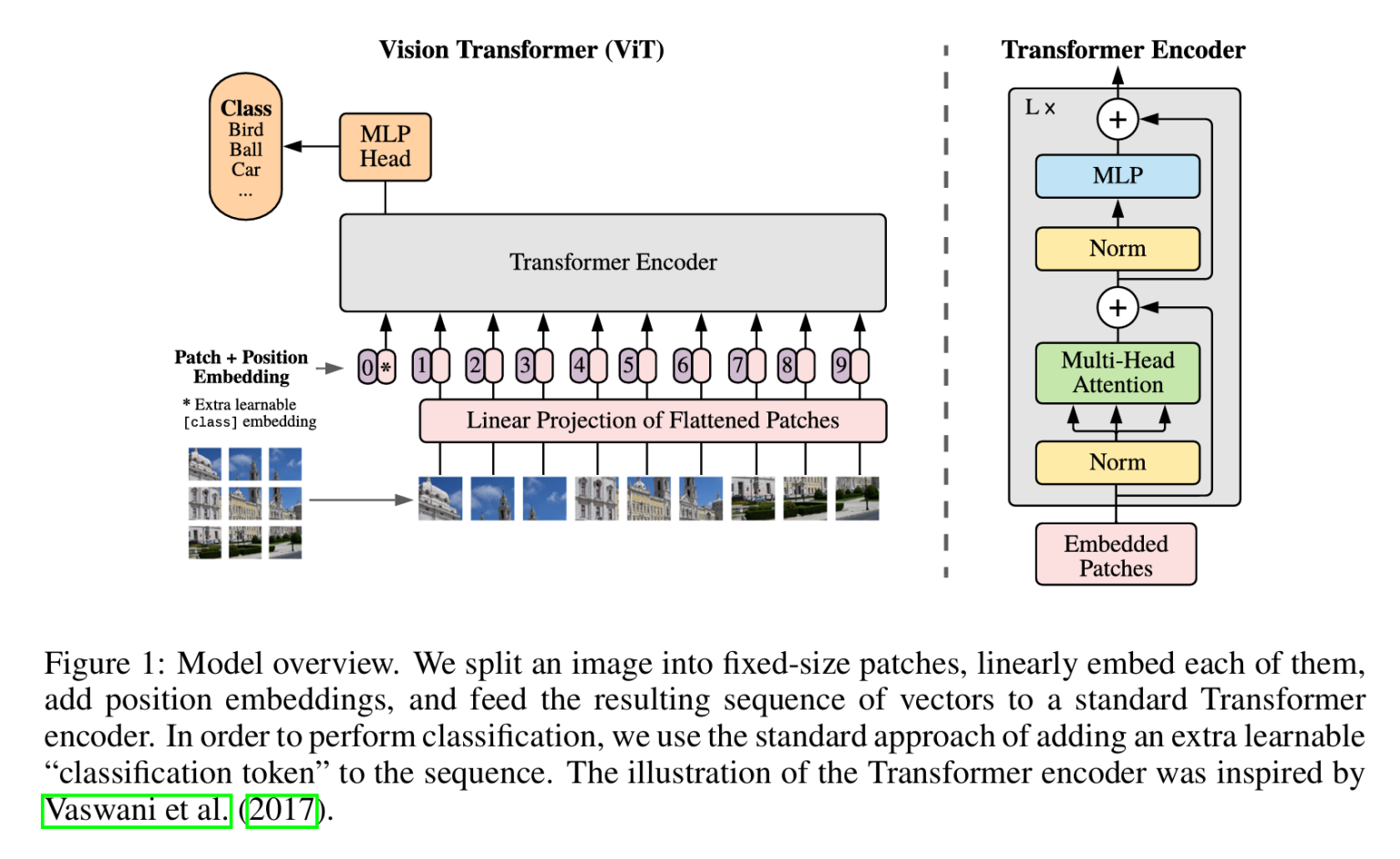
Transformer从NLP发展到视觉,开始改变视觉问题的处理方式,SwinTransformer和ViT都是典型的网络结构,典型的Transformer结构中大量使用Multi-Head Attention。ViT基于经典的Transformer模型,采用图像分块的方式将图像处理的问题转化为seq2seq的问题,这篇博客会从Attention开始,介绍到ViT。
神经网络训练量化(QAT)基本概念
QAT(Quantization Aware Training)量化感知训练是神经网络优化模型容量的重要方法,关系到模型精度和性能。pytorch对模型量化支持有三种方式:模型训练完毕后的动态量化、模型训练完毕后的静态量化、模型训练中开启量化QAT。这篇博客主要基于pytorh介绍QAT的基本概念。
使用OpCounter和flops-counter评估pytorch模型大小
在Pytorch中统计模型大小有一个非常好用的工具opcounters,opcounters用法也非常简单,这篇博客介绍opcounters用法。
CNN直接处理YUV图像
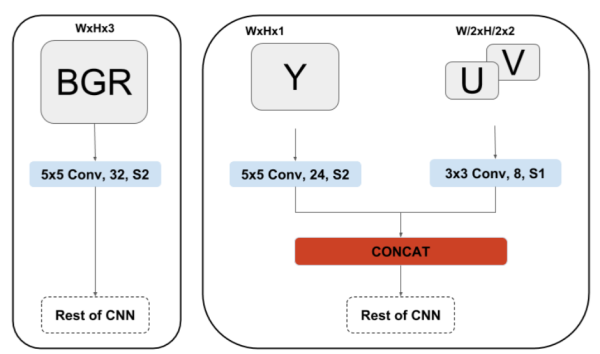
在ISP pipe中,最后输出的一般都是YUV图像,YUV420的数据量是RGB数据量的两倍,我们在送入CNN处理的时候处理RGB图像居多,如果CNN也可以直接输入YUV图像,那么前级需要的带宽就会减为输入RGB图的一半。
YUVMultiNet提供了一种实用的结构来处理YUV图像。这篇博客只会介绍处理YUV的这种结构,如果对MultiNet感兴趣可以移步原文:https://arxiv.org/pdf/1904.05673.pdf
论文速览:Optical Flow Estimation from a Single Motion-blurred Image
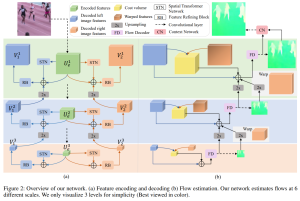
AAAI 2021接收论文,使用单帧模糊图像估计光流。论文地址:https://arxiv.org/pdf/2103.02996v1.pdf
论文主要有三个贡献:一是首次实现通过单帧运动模糊图像估计光流和运动,二是从视频序列中生成运动模糊图像和groundtruth来训练网络,三是将结果用于运动模糊去除和运动目标分割。
从RNN到Seq2Seq
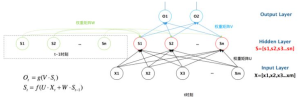
循环神经网络RNN结构被广泛应用与NPL领域,在机器翻译、语音识别、文字识别等方向大放异彩。后来RNN产生了多种变种,其中Seq2Seq结构和Attention机制被证明在语义理解方面有很大的增益。博主也很久没有碰过这块内容了,简单的摘抄和拼凑,权当复习笔记了 0.0
YOLO_V3从训练到部署
darknet是一个C语言实现的深度学习框架,几乎不依赖任何库,安装编译都很方便,训练好的模型可以直接在opencv上部署,堪称业界良心。这篇博客主要包含目标检测数据标注和预处理、yolo_v3代码编译、模型训练、在opencv上部署,都是简要的笔记。
目标检测算法梳理YOLO、SSD、CornerNet
大概两三年前,博主有发过一篇综述:深度学习综述(二)深度学习用于目标检测 ,那时候主要是Fast-RCNN系列到yolo和ssd系列,之后很久不务正业没有跟进了。最近又开始跟进下,摘抄些笔记,没啥有深度的东西。
梳理下目标检测算法,大致经历了如下发展: 传统机器学习方法(slide window+feature extraction) -> Region Proposal + CNN -> Anchor Based CNN -> Anchor Free CNN。本文简单介绍Anchor Base方法中最著名的YOLO和SSD,Anchor Free方法中的CornerNet。
Pytorch图像分类之ShuffleNet

在图像分类应用下,诞生了不少经典网络。ShuffleNet以速度快和便于移植而著称,这篇博客将简单介绍ShuffleNet,以及Pytorch下模型的训练、保存、微调、生成CaffeModle。
MTCNN进行人脸特征点检测和特征点提取

级联CNN提出与2015年,在目标检测领域有着很成功的应用。好久好久好久没看过目标检测了,今天被问到这个,临时翻论文到源码,发现还是很容易理解的。只是好久好久好久没玩Caffe,发现Caffe现在丰富了太多。这篇博客介绍的MTCNN人脸检测,就是基于Caffe平台的,与级联CNN有关,清楚所有技术细节之后,决定写一篇博客记录一下。
MatConvNet进行FCN语义分割
FCN语义分割算法已经在很多主流深度学习平台上实现了,包括Caffe、TenserFlow、MatConvNet等。这篇博客主要介绍如何在MatConvNet上运行起FCN语义分割,包括CPU和GPU版本。博主的平台是Matlab2017a+Cuda8.0。
图像跟踪(九)FCNT语义跟踪
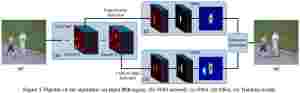
刚有一个idea,用语义分割来做图像跟踪,搜了一下发现已经有人做过了,细细的看了下Paper,和自己相当还不一样。FCN是深度学习语义分割的鼻祖,而这片Paper的名字叫做FCNT,看了之后发现我误会了,此FCN非彼FCN,由于是比较早的算法了,性能和MEEM处于同一层次,不过考虑到这是深度学习方法用于跟踪的重要实践,还是做个笔记好了。
博主认为图像跟踪过程的本质就是语义的跟踪(我是这么理解的),所以,使用语义分割来完成图像跟踪是自然而然想到的。事实上深度学习用于图像跟踪,也就是利用了其深层特征中的语义信息。这篇博客就主要介绍这篇文献:Visual Tracking with Fully Convolutional Networks。
视频图像跟踪算法综述
 图像跟踪一直都是计算机视觉领域的难题,事先知道第一帧中的目标位置,然后需要在后续帧中找到目标。先验知识少,目标被遮挡、目标消失、运动模糊、目标和环境的剧烈变化、目标的高速运动、相机的抖动都会对目标跟踪造成影响,图像跟踪一直都是CV领域的难题。
图像跟踪一直都是计算机视觉领域的难题,事先知道第一帧中的目标位置,然后需要在后续帧中找到目标。先验知识少,目标被遮挡、目标消失、运动模糊、目标和环境的剧烈变化、目标的高速运动、相机的抖动都会对目标跟踪造成影响,图像跟踪一直都是CV领域的难题。
深度学习用于图像跟踪有两大要解决的问题,一是图像跟踪一般使用在线学习,很难提供大量样本集,二是深度学习使用CNN时,由于卷积池化,最后一层的输出丢失了位置信息,而图像跟踪就是要输出目标的位置。
2013年以来,深度学习开始用于目标跟踪,并且为这些问题提供了一些解决思路。这篇博客首先阐述图像跟踪今年来的研究进展,然后再介绍深度学习用于图像跟踪近年来的研究,最后附上一些学习资料和相关网站。