前面一个篇章:算法的嵌入式移植(一)C代码优化部分 侧重语言层面的优化,而更多针对DSP特性进行的优化将在本篇章进行介绍 ,内容大多是摘抄书本和网络资源,因为是整理以往的笔记,来源已经不可靠了,不过不影响其中内容的经典。
LeetCode_210: CourseScheduleII 拓扑排序
这道题与前一版本207一样,只不过前一版本要求判断是否有环,而当前版本还要给出可行顺序,那么这个问题就自然而然的归为拓扑排序了。这篇博客将对有向图和无向图中是否存在环这一问题进行归纳,并且给出一个较为简洁的拓扑排序代码。拓扑排序,简单的说就是不断将度为0的点提取出来,提取的顺序就是拓扑排序。在算法导论中,给出了DFS和BFS解法,其中DFS采用完成时间倒序作为拓扑排序,我们需要了解拓扑排序问题的解法是多样的,这篇博客给出的代码不算唯一的。
算法的嵌入式移植(一)C代码优化
一般C/C++的算法代码不适合直接移植到嵌入式设备,需要做一些优化和处理。一方面是出于速度考虑,另一方面是针对嵌入式设备支持的语言特性差异进行修改,还有就是硬件上的考虑,比如就定点DSP而言,就需要将原来的浮点运算进行转化。
近期博主在整理以往笔记,就将算法嵌入式移植这部分差分成两个章节,一是C代码优化部分,二是DSP代码移植部分,第一章节是语言层面的一般而言是适合所有嵌入式设备的,第二章节是和DSP开发环境相关方面的。特此整理,谨供参考。
OpenCV特征点提取算法对比
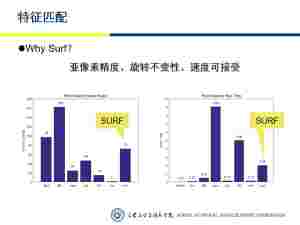
除了我们熟知的SIFT、SURF、ORB等特征点提取算法,OpenCV中还提供了十余种特征点提取算法。最近在整理以往的ppt和报告,看到其中一页ppt,发现已经忘得差不多了,就再写篇博客复习下好了,这篇博客注重对比,技术方面的内容不会太过细致,希望能有帮助。当然,文章末尾会提供这些算法OpenCV调用的实例代码。
首先,引发内容的就是下面这张ppt:(不要注意Why Surf了,当时根据具体应用场景所做的选择)左边一栏是特征点的数目,右边一栏是检测的速度,数据是在博主自己的测试集(大概四五百张图片)上测试的。
点云数据处理方法概述
结束目标跟踪的研究,回到课题上,接下来要面对的就是点云数据的处理了。这篇博客主要介绍三维计算机视觉中点云数据处理面对的问题,主要方法和技术,概述其特点。这篇博客主要介绍最基本的点云数据处理技术和概念,不会有任何代码。
ICP点云配准就是我们非常熟悉的点云处理算法之一。实际上点云数据在形状检测和分类、立体视觉、运动恢复结构、多视图重建中都有广泛的使用。点云的存储、压缩、渲染等问题也是研究的热点。随着点云采集设备的普及、双目立体视觉技术、VR和AR的发展,点云数据处理技术正成为最有前景的技术之一。PCL是三维点云数据处理领域必备的工具和基本技能,这篇博客也将粗略介绍。
LeetCode_174: Dungeon Game 动态规划
做了一道很有意思的题目,要求是从左上角开始,在HP不掉到0的情况下,到达右下角。虽然明显是使用动态规划来解,但是其中隐藏了一些技巧 。这里,如果从左上角开始进行DP将使得问题复杂化,技巧就是反向,从终点开始反向DP,这篇博客将详细这种方法的应用条件。
LeetCode_134: Gas Station
这道题目可以使用一般的DP来做,但是博主想到的方法更加直接:对于判断是否存在解,直接把数组累加,如果和非负,那么必然存在一个位置,使得从这个位置开始进行累加的所有结构都非负。在进行累加的过程中,找到累加和最小的位置,从这个位置的下一个位置开始,就可以保证在累加过程中,累加曲线的最小值最大(想象积分曲线的过程,积分的终点sum相同,一个先下降再上升,一个先上升再下降)。有点绕,多想想 :)
算法导论总结(四)字符串运算
刷了150多道题,再来一发总结。再LeetCode中有一类题目,要求直接使用数字字符串进行运算,这类题目掌握技巧之后不容易出错,也比较简单,那么这篇博客将对这类题目进行总结,希望有所帮助。
LeetCode_068: Text Justification
又是一道通过率不过20%的题,总结这种通过率比较多的题目,发现其中很多原理并不难,导致通过率比较低的原因是各种极端情况,还有就是题目理解和表述不够清晰。比如自己实现Atoi,如果列出要处理的各种情况,写出来并不难。这道题也是一样,其实没什么难度,只是有些情况下,具体说来就是最后一行或者一行的最后一个单词,需要特殊处理。
LeetCode_091: DecodeWays 从DFS到动态规划
从LeetCode中有一些数字字符串处理问题,它们的解法有许多相似之处,但是在具体操作上又有所不同,91题和93题IPAddress就是比较好的范例。这篇博客主要从DFS和DP两种方法来分析问题,并判断适应问题环境使用合适的方法。
LeetCode_131: Palindrome Partition 回文字符串
回文字符串问题可以看做是一个划分链问题,这个和算法导论中介绍动态规划时的矩阵链乘法是一样的,找到一个最优的划分方案。很自然的想到动态规划来得到一个回文串的真值表,然后就是要列举出所有的情况,回溯法可以做到,自然而然的DP+BackTracking解决掉。
LeetCode_010: 正则表达式匹配 与 044: 通配符匹配
最近在攻略动态规划,在做正则表达式匹配的时候看错了题目,发现写出来的是通配符匹配,后来看了下什么是正则表达式才明白过来。这两道题都是有很多解法的题目,按照标签刷题目还是限制了自己的思路,一开始就没有往其它地方想。事实上,通配符匹配用贪心算法(可以看做一种特殊的动态规划)更合适。
Scikit-learn学习笔记(一)环境搭建
Scikit-learn在机器学习领域已经无人不晓了,如此给力的工具应该早点接触到的。sk-learn既不支持深度学习,也不支持GPU加速,sk-learn是专门用来搞定传统机器学习的,这一点要给深度学习玩家提醒下。这篇博客主要讲Python环境的搭建,博主使用的是pycharm+anaconda,pycharm是python的IDE,支持断点调试和工作区变量查看,anaconda用来解决各种包的依赖关系,scikit-learn已经集成在其中了,安装之后检查包的更新就可以了。
算法导论总结(三)树
树作为重要的数据结构,在很多领域有着重要的用途。在LeetCode中对数的考察主要分为三个方面,一是树的遍历,二是BST(二叉搜索树),三是和树相关的算法。有时,树也常常被看做一个图,做BFS和DFS,树的考察是相当灵活的。这篇博客就这些问题做部分小结。
算法导论总结(二)链表
LeetCode刷了一百多道题,决定来发小小的总结。这篇博客主要对LeetCode中链表标签下的题目进行总结,linked-list标签下总共有27道题,这些题目较为全面的考察链表操作:插入、删除、反转、交换、合并、环路检查等。
LeetCode_023: Merge k Sorted Lists
一种结合链表和优先队列的优雅解法,巧妙之处在于使用优先队列出队元素,可以直接得到下一个入队元素,算法复杂度是O(nlgn)。联想到如果不是优先队列结构,那么我们可以使用同样的解法,只是我们需要在队列中记录每个元素属于哪一行,而使用链表结构就避免了这种麻烦。
LeetCode_126: Word Ladder II
最近总是Rank到很难的题目,这次遇到了LeetCode中通过率最低的题目。这道题目是一个图相关的问题,同时牵扯到很多坑,很多细节,即使思路正确稍不注意内存超出,时间超出都是常事儿,自己做出来还是需要废一番功夫的。博主写了BFS算法的大概就放弃了,后面翻了几份代码,找了个最简洁的 ,这里也只能讲解一下别人的代码了。