数据来源是东方财富网站,博客只做贴图(特别留意几个时间点:2018年贸易战,2019-2022疫情情前后的变化),数据本身很有趣,博主的comments不构成投资建议,不过毫无疑问的是我们正处于通缩周期中。
Demosaic算法的零散笔记
demosaic算法主要过程是判边(Direction)和插值,同时需要考虑区域的饱和度(Saturation … 阅读更多
a blog driven by interest~
demosaic算法主要过程是判边(Direction)和插值,同时需要考虑区域的饱和度(Saturation … 阅读更多

数据来源是东方财富网站,博客只做贴图(特别留意几个时间点:2018年贸易战,2019-2022疫情情前后的变化),数据本身很有趣,博主的comments不构成投资建议,不过毫无疑问的是我们正处于通缩周期中。

不动产投资信托(Real Estate Investment Trusts,缩写REITs)又称房托基金、地产信托,于1960年发源于美国,是一种通过发行收益信托凭证/股份汇集资金,由管理人进行房地产投资、经营和管理,并将投资总和收益分配给投资者的证券。
对于投资者而言,REITs由不动产的证券话以及许多投资人的资金募集,使得没有庞大资本的一般投资人也能以降低门槛参与不动产市场,活动不动产市场交易、租金与增值所带来的收益。同时投资人不需要实质持有不动产标的,就可在正确市场交易,因此市场流通性由于不动产。
参考链接: https://wzproject.com/n26-review/
上一篇博客给了一个QImageView类,其中实现了图片浏览器的基础鼠标操作,在此基础之上,进一步实现鼠标框选的操作。具体实现时,我们先构建一个场景类QImageScene,用于管理场景中的Item,场景中的Item主要有两类,一类是图像,另一类是选择框。对于选择框的操作,我们把鼠标事件定义在QImage Scene类中。
实现了一个ImageView类,继承自QGraphicsView,主要overwrite鼠标和滚轮事件,实现基本的拖拽,以鼠标中心点进行缩放。
问题是我们估计一对图像之间是否存在局部运动,我们知道这两张图像各自的噪声分布,在某个亮度下服从正态分布sigm … 阅读更多
使用符号工具箱求导函数,以及使用solve解方程的一个简单例子:
两个例子, 一是用solve函数解带约束条件的方程组, 二是用fmincon函数解带约束条件的最小化问题 一个 … 阅读更多
翻老代码发现之前写了一个简单的符号工具箱化简方程,好久不用遗忘了,留个代码备份
一、偏微分方程

这篇博客是论文:High Accuracy Optical Flow Estimation Based Theory for Warp 的笔记,论文为2004年,在2015年EpicFlow方法中引用。
在稠密光流估计中,最后一步往往是将光流图进行Refine和smooth,来确保光流在空间上连续,大部分区域符合刚体运动假设,同时也会处理遮挡,为遮挡区域提供连续的光流值。
在介绍的论文中,建立了一个能量函数,将光流图的优化和优化能量函数联系起来。论文偏向传统,但是也很经典,接下来一起看下做法。
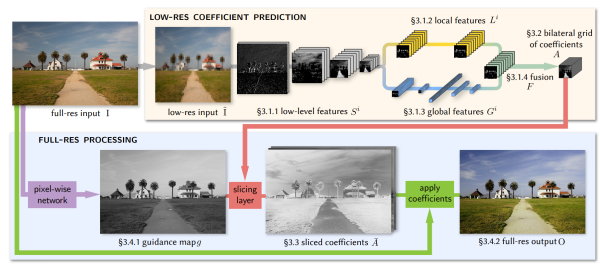
这篇博客介绍 Google 近年来在Photography方面一篇具有代表性的论文,Deep Bilateral Learning for Real-Time Image Enhancement
HDRNET的主要特征数数据分成两路,低分辨率偏向high level语义,这一路学习到的是一系列参数(分mesh的3×4 color matrix),学习参数需要的计算资源相对于学习输出图需要的资源更少,移动端部署更加方便。高分辨率一路更偏向low-level引导,学些引导图和参数apply。
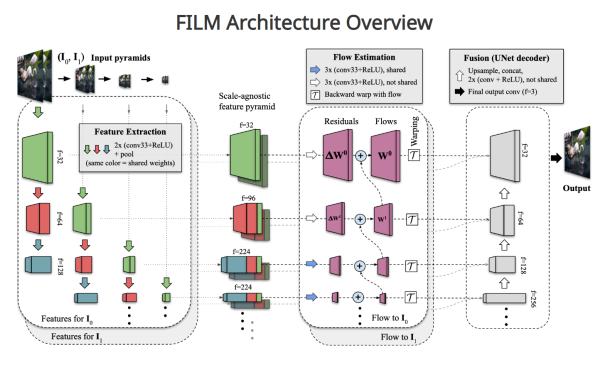
两张图片就可以生成一小段视频,效果很不错,可以直接在网站上用demo玩儿一玩儿。
网站和源码:https://film-net.github.io/
Google AI Blog:https://ai.googleblog.com/2022/10/large-motion-frame-interpolation.html

京东方的一篇论文,主打轻量级网络做Real-Time SR,只有一层,对标传统bicubic上采样,因为轻量,所以实用,同时一层网络的可解释性也更强。
论文地址:Edge-SR:Super-Resolution For The Masses
Hugging face起初是一家总部位于纽约的聊天机器人初创服务商,聊天机器人服务没搞起来,但是hugging face在github上开源的transformers库大火,已经成为机器学习届最活跃的开源社区。这篇博客简单介绍下怎样从hugggingface获取数据和使用模型。
hugging face的官方网站:http://www.huggingface.co./ 。 我们基本可以从这里捞到很多数据集、预训练模型、课程 和 文档。