记录一下使用pyRender在没有显示器的服务器端做场景渲染时遇到的一些报错和解决。
写在前面,pyrender真是个大坑,渲染还很慢, realrender用cpu渲染也很快,问题没这么多,如果还没有绑定pyrender可以早些转投realreader,调试时候也需要灵活些,发现egl后端问题解不了,可以先用osmega后端,两个可以切换着来。
a blog driven by interest~
HDRFLOW论文地址:https://arxiv.org/pdf/2403.03447.pdf 首先,我们看 … 阅读更多
把densepose官方给的代码做了简化,去除了各种封装和log,只保留核心功能。 使用之前先pip安装den … 阅读更多
记录pycharm启动wsl调试器时出现问题和解决方法。 1. 报错:wsl a localhost prox … 阅读更多
记录一下使用pyRender在没有显示器的服务器端做场景渲染时遇到的一些报错和解决。
写在前面,pyrender真是个大坑,渲染还很慢, realrender用cpu渲染也很快,问题没这么多,如果还没有绑定pyrender可以早些转投realreader,调试时候也需要灵活些,发现egl后端问题解不了,可以先用osmega后端,两个可以切换着来。
https://github.com/Meshcapade/SMPL_blender_addon https: … 阅读更多
收藏一些python包的unofficial下载地址,有的包我们直接安装有问题,或者编译安装有问题,可以来这些 … 阅读更多
挖坑,回填

这篇博客主要介绍Codebook机制和CodeFormer,之前介绍了一种类似包含dictionary的算法 RestoreFormer和RestoreFormer++,他们有一些共通的机制,之前看VQ-VAE时候没有把Codebook梳理清楚,这里补补坑。
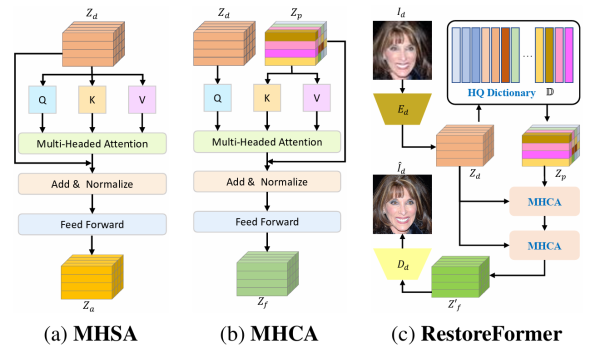
RestoreFormer收录于CVPR2022,其后续工作RestoreFormer++被收录于TPAMI2023,属于图像复原领域比较具有代表性的工作。这里需要一些transformer的前置知识,可以参见Vision Transformer.
在控制生成式模型时,ControlNet/Ip-adaptor比较有用,这边博客主要介绍ControlNet和 … 阅读更多
CVAT的一些笔记和常用命令: deploy启动: docker compose -f docker-comp … 阅读更多
情况一、软路由同主机部署 1. 增加规则 2. 用户ID区分 新建一个用户, id 设为 1010, 用此用户 … 阅读更多
PyCharm的ImageWatch插件最近4.0版本开始收费了,收费版本的部分功能在之前版本中都是免费的,之 … 阅读更多
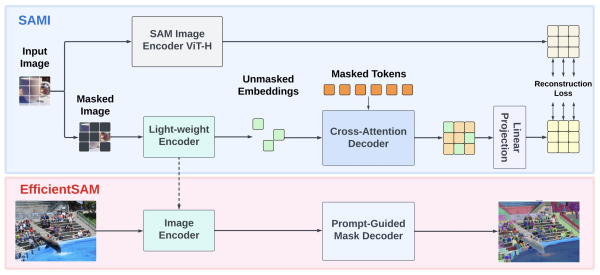
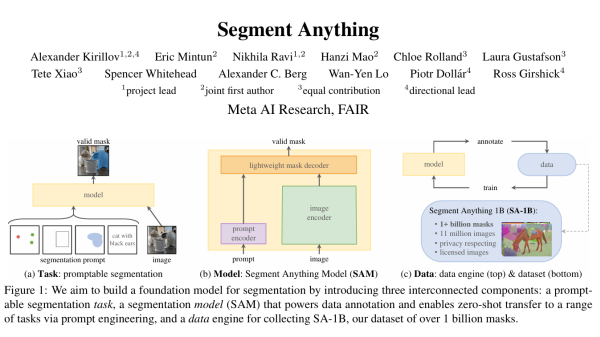
开始之前需要一些前置知识,关于SAM请移步:SAM论文笔记, 关于ViT基础请移步:Vision Transformer,关于MAE请移步知乎:MAE(Masked Autoencoders) – 知乎 (zhihu.com)。
SAM的解码器已经足够快,但是图像编码器用的ViT还是很大,于是很多工作就在SAM基础上改进性能,进行轻量化,其中有一些比较出色的工作 比如 MobileSAM 、 FastSAM 和 EfficientSAM 等,已经将SAM推到了相当轻量。这篇博客主要是EfficientSAM的论文笔记。